
并行查询
在某些情况下,需要多次查询数据库,为了减少用户的等待时间,bugu-mongo提供了并行查询机制。
比如:一个网页上要展示3部分数据,需要查询3次数据库,假设每个查询所需要的时间分别是500ms、600ms、700ms,如果依次执行3个查询,总共需要1800ms时间;如果使用bugu-mongo的并行查询机制,3个查询同时执行,则只需要700ms就能返回全部数据。
要实现并行查询,需要使用ParallelQueryExecutor类,它提供了一个方法:
public List<Iterable> execute(Parallelable... querys)
例如:
List<Iterable> list = new ParallelQueryExecutor().execute(query1, query2, query3);
参数
execute()方法的参数,是多个Parallelable对象。Parallelable是一个接口,BuguQuery、BuguAggregation、JoinQuery这三个类均实现了该接口。如下图:
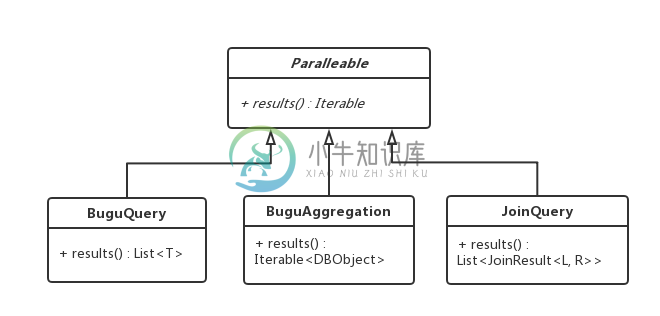
返回
execute()方法的返回,是一个List列表,List的长度,与参数querys的长度相一致;List中的元素,按顺序对应着每个查询的结果。参照上图中不同results()的实现,可以把List中的元素强制转换成我们需要的类型:
BuguDao<LargeData> dao = new BuguDao(LargeData.class);
BuguAggregation<LargeData> agg1 = dao.aggregate().group("{_id:null, maxValue:{$max:'$randomValue'}}");
BuguAggregation<LargeData> agg2 = dao.aggregate().group("{_id:null, minValue:{$min:'$randomValue'}}");
BuguAggregation<LargeData> agg3 = dao.aggregate().group("{_id:null, avgValue:{$avg:'$randomValue'}}");
BuguQuery<LargeData> q4 = dao.query().greaterThan("randomValue", 0.8).sort(SortUtil.asc("randomValue")).pageNumber(1).pageSize(10);
//执行并行查询
List<Iterable> list = new ParallelQueryExecutor().execute(agg1, agg2, agg3, q4);
//如何获取返回数据?如下:
//对于BuguAggregation的结果,强制转换为Iterable<DBObject>
Iterable<DBObject> it1 = (Iterable<DBObject>)list.get(0);
DBObject dbo1 = it1.iterator().next();
System.out.println("maxValue: " + dbo1.get("maxValue"));
Iterable<DBObject> it2 = (Iterable<DBObject>)list.get(1);
DBObject dbo2 = it2.iterator().next();
System.out.println("minValue: " + dbo2.get("minValue"));
Iterable<DBObject> it3 = (Iterable<DBObject>)list.get(2);
DBObject dbo3 = it3.iterator().next();
System.out.println("avgValue: " + dbo3.get("avgValue"));
//对于BuguQuery的结果,强制转换为List<T>
List<LargeData> it4 = (List<LargeData>)list.get(3);
for(LargeData data : it4){
System.out.println("randomValue: " + data.getRandomValue());
}
注意
如果你的应用,即使是依次执行多个查询,也并不显得慢,那就没必要使用并行查询。因为bugu-mongo使用线程池来实现并行查询,而创建线程池也是有开销的。