
第2章 C++ 的重要性质
C++ 是一种扭转程序员思维模式的语言。
一个人思维模式的扭转,不可能轻而易举一蹴而成。
近来「面向对象」一词席卷了整个软件界。面向对象程序设计( Object Oriented Programming)其实是一种观念,用什么语言实现它都可以。但,当然,面向对象程序语言(Object Oriented Programming Language)是专门为面向对象观念而发展出来的,以之完成面向对象的封装、继承、多态等特性自是最为便利。
C++ 是最重要的面向对象语言,因为它站在 C 语言的肩膀上,而 C 语言拥有绝对优势的使用者。C++ 并非纯粹的面向对象程序语言,不过有时候混血并不是坏事,纯种也不见得就多好。
所谓纯面向对象语言,是指不管什么东西,都应该存在于对象之中。JAVA 和 Small Talk都是纯面向对象语言。
如果你是C++的初学者,本章不适合你(事实上整本书都不适合你),你的当务之急是去买一本C++专书。一位专精Basic和Assembly语言的朋友问我,有没有可能不会C++而学会MFC?答案是当然没有可能。
如果你对C++一知半解,语法大约都懂了,语意大约都不懂,本章是我能够给你的最好礼物。我将从类与对象的关系开始,逐步解释封装、继承、多态、虚函数、动态联编。不只解释其操作方式,更要点出其意义与应用,也就是,为什么需要这些性质。
C++ 语言范围何其广大,这一章的主题挑选完全是以MFC Programming 所需技术为前提。下一章,我们就把这里学到的C++ 技术和OO观念应用到application framework 的仿真上,那是一个 DOS 程序,不牵扯 Windows。
类及其成员——谈封装(encapsulation)
让我们把世界看成是一个由对象(object)所组成的大环境。对象是什么?白一点说,「东西」是也!任何实际的物体你都可以说它是对象。为了描述对象,我们应该先把对象的属性描述出来。好,给「对象的属性」一个比较学术的名词,就是「类」(class)。
对象的属性有两大成员,一是数据,一是行为。在面向对象的术语中,前者常被称为property(Java 语言则称之为 field),后者常被称为 method。另有一双比较像程序设计领域的术语,名为 member variable(或 data member)和 member function。为求统一,本书使用第二组术语,也就是 member variable(成员变量)和 member function(成员函数)。一般而言,成员变量通常由成员函数处理之。
如果我以 CSquare 代表「四方形」这种类,四方形有 color,四方形可以 display。好,color 就是一种成员变量,display 就是一种成员函数:
CSquare square; // 声明square 是一个四方形。
square.color = RED; // 设定成员变量。RED代表一个颜色值。
square.display(); // 调用成员函数。
下面是C++ 语言对于CSquare 的描述:
class CSquare // 常常我们以 C 作为类名称的开头
{
private:
int m_color; // 通常我们以 m_ 作为成员变量的名称开头
public:
void display() { ... }
void setcolor(int color) { m_color = color; }
};
成员变量可以只在类内被处理,也可以开放给外界处理。以数据封装的目的而言,自然是前者较为妥当,但有时候也不得不开放。为此,C++ 提供了private、public 和protected 三种修饰词。一般而言成员变量尽量声明为private,成员函数则通常声明为public。上例的m_color 既然声明为private,我们势必得准备一个成员函数setcolor,供外界设定颜色用。
把数据声明为 private,不允许外界随意存取,只能通过特定的接口来操作,这就是面向对象的封装(encapsulation)特性。
基类与派生类:谈继承(Inheritance)
其它语言欲完成封装性质,并不太难。以 C 为例,在结构(struct)之中放置数据,以及处理数据的函数的指针(function pointer),就可得到某种程度的封装精神。
C++ 神秘而特有的性质其实在于继承。
矩形是形,椭圆形是形,三角形也是形。苍蝇是昆虫,蜜蜂是昆虫,蚂蚁也是昆虫。是的,人类习惯把相同的性质抽取出来,成立一个基类(base class),再从中衍化出派生类(derived class)。所以,关于形状,我们就有了这样的类阶层:
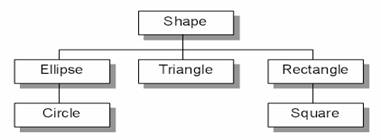
#0001 class CShape // 形状
#0002 {
#0003 private:
#0005 int m_color;
#0006 public:
#0007 void setcolor(int color) { m_color = color; }
#0008 };
#0010 class CRect : public CShape // 矩形是一种形状
#0011 { //它会继承m_color 和setcolor()
#0012 public:
#0013 void display() { ... }
#0014 };
#0016 class CEllipse : public CShape // 椭圆形是一种形状
#0017 { //它会继承m_color 和setcolor()
#0018 public:
#0019 void display() { ... }
#0020 };
#0022 class CTriangle : public CShape // 三角形是一种形状
#0023 { //它会继承m_color 和setcolor()
#0024 public:
#0025 void display() { ... }
#0026 };
#0028 class CSquare : public CRect // 四方形是一种矩形
#0029 {
#0030 public:
#0031 void display() { ... }
#0032 };
#0034 class CCircle : public CEllipse // 圆形是一种椭圆形
#0035 {
#0036 public:
#0037 void display() { ... }
#0038 };
于是你可以这么动作:
CSquare square;
CRect rect1, rect2;
CCircle circle;
square.setcolor(1); // 令 square.m_color = 1;
square.display(); // 调用 CSquare::display
rect1.setcolor(2); // 于是 rect1.m_color = 2
rect1.display(); // 调用 CRect::display
rect2.setcolor(3); // 于是 rect2.m_color = 3
rect2.display(); // 调用 CRect::display
circle.setcolor(4); // 于是 circle.m_color = 4
circle.display(); // 调用 CCircle::display
注意以下这些事实与问题:
1. 所有类都由CShape 派生下来,所以它们都自然而然继承了CShape的成员,包括变量和函数。也就是说,所有的形状类都「暗自」具备了m_color 变量和setcolor函数。我所谓暗自(implicit),意思是无法从各派生类的声明中直接看出来。
2. 两个矩形对象rect1和rect2各有自己的m_color,但关于setcolor函数却是共享相同的CRect::setcolor(其实更应该说是CShape::setcolor)。我用这张图表示其间的关系:
对象 rect1 对象 rect2
m_color m_color
↑ ↑
this 指针 this 指针
CRect::setcolor(int color, CRect* this)
{
this->m_color = color;
}//这个this参数是编译器自行为我们加上的,所以我说它是个 "隐藏指针"。
rect1.setcolor 和 rect2.setcolor 调用的都是 CRect::setcolor,后者之所以能分别处理不同对象的成员变量,完全是靠一个隐藏的this指针。
让我替你问一个问题:同一个函数如何处理不同的数据?为什么rect1.setcolor 和rect2.setcolor 明明都是调用CRect::setcolor(其实也就是CShape::setcolor),却能够有条不紊地分别处理 rect1.m_color 和rect2.m_color?答案在于所谓的this 指针。下一节我就会提到它。
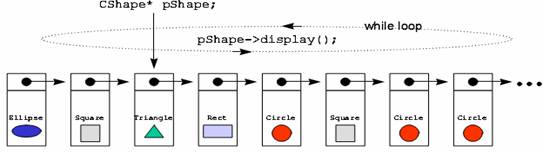
3. 既然所有类都有display动作,把它提升到老祖宗CShape去,然后再继承之,好吗?不好,因为display函数应该因不同的形状而动作不同。
4. 如果display不能提升到基类去,我们就不能够以一个for循环或while循环干净漂亮地完成下列动作(此种动作模式在面向对象程序方法中重要无比):
CShape shapes[5];
... // 令 5 个 shapes 各为矩形、四方形、椭圆形、圆形、三角形
for (int i=0; i<5; i++)
{
shapes[i].display;
}
5. Shape 只是一种抽象概念,世界上并没有「形状」这种东西!你可以在一个 C++程序中做以下动作,但是不符合生活法则:
CShape shape; // 世界上没有「形状」这种东西,
shape.setcolor();// 所以这个动作就有点奇怪。
这同时也说出了第三点的另一个否定理由:按理你不能够把一个抽象的「形状」显示出来,不是吗?!
如果语法允许你产生一个不应该有的抽象对象,或如果语法不支持「把所有形状(不管什么形状)都 display 出来」的一般化动作,这就是个失败的语言。C++ 是成功的,自然有它的整治方式。记住,「面向对象」观念是描绘现实世界用的。所以,你可以以真实生活中的经验去思考程序设计的逻辑。
this 指针
刚刚我才说过,两个矩形对象rect1 和rect2 各有自己的m_color 成员变量,但rect1.setcolor 和rect2.setcolor却都通往唯一的 CRect::setcolor成 员 函 数 。
那么CRect::setcolor如何处理不同对象中的m_color?答案是:成员函数有一个隐藏参数,名为this指针。当你调用:
rect1.setcolor(2); // rect1 是 CRect 对象
rect2.setcolor(3); // rect2 是 CRect 对象
编译器实际上为你做出来的代码是:
CRect::setcolor(2, (CRect*)&rect1);
CRect::setcolor(3, (CRect*)&rect2);
不过,由于CRect本身并没有声明setcolor,它是从CShape继承来的,所以编译器实际上产生的代码是:
CShape::setcolor(2, (CRect*)&rect1);
CShape::setcolor(3, (CRect*)&rect2);
多出来的参数,就是所谓的 this 指针。至于类之中,成员函数的定义:
class CShape
{
...
public:
void setcolor(int color) { m_color = color; }
};
被编译器整治过后,其实是:
class CShape
{
...
public:
void setcolor(int color,(CShape*)this){ this->m_color = color; }
};
我们拨开了第一道疑云。
虚函数与多态(Polymorphism)
我曾经说过,前一个例子没有办法完成这样的动作:
CShape shapes[5];
... // 令 5 个 shapes 各为矩形、四方形、椭圆形、圆形、三角形
for (int i=0; i<5; i++)
{
shapes[i].display;
}
可是这种所谓对象操作的一般化动作在application framework中非常重要。作为framework设计者的我,总是希望能够准备一个display 函数,给我的使用者调用;不管他根据我的这一大堆形状类派生出其它什么奇形怪状的类,只要他想 display,像下面那么做就行。
为了支持这种能力,C++ 提供了所谓的虚函数(virtual function)。
虚拟 + 函数?! 听起来很恐怖的样子。如果你了解汽车的离合器踩下去代表汽车空档,空档表示失去引擎本身的牵制力,你就会了解「高速行驶间煞车绝不能踩离合器」的道理并矢志遵行。好,如果你真的了解为什么需要虚函数以及什么情况下需要它,你就能够掌握它的灵魂与内涵,真正了解它的设计原理,并且发现认为它非常人性。并且,真正知道怎么用它。
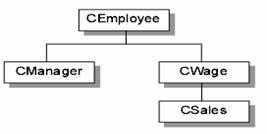
让我用另一个例子来展开我的说明。这个范例灵感得自Visual C++手册之一:Introdoction to C++。假设你的类种类如下:
程序代码实现如下 :
#0001 #include <string.h>
#0003 //---------------------------------------------------------------
#0004 class CEmployee // 职员
#0005 {
#0006 private:
#0007 char m_name[30];
#0009 public:
#0010 CEmployee();
#0011 CEmployee(const char* nm) { strcpy(m_name, nm); }
#0012 };
#0013//---------------------------------------------------------------
#0014 class CWage : public CEmployee // 时薪职员是一种职员
#0015 {
#0016 private :
#0017 float m_wage;
#0018 float m_hours;
#0020 public :
#0021 CWage(const char* nm):CEmployee(nm){ m_wage = 250.0; m_hours =40.0; }
#0022 void setWage(float wg) { m_wage = wg; }
#0023 void setHours(float hrs) { m_hours = hrs; }
#0024 float computePay();
#0025 };
#0026//---------------------------------------------------------------
#0027 class CSales : public CWage // 销售员是一种时薪职员
#0028 {
#0029 private :
#0030 float m_comm;
#0031 float m_sale;
#0033 public :
#0034 CSales(const char* nm) : CWage(nm) { m_comm = m_sale = 0.0; }
#0035 void setCommission(float comm) {m_comm = comm; }
#0036 void setSales(float sale) { m_sale = sale; }
#0037 float computePay();
#0038 };
#0039//---------------------------------------------------------------
#0040 class CManager : public CEmployee // 经理也是一种职员
#0041 {
#0042 private :
#0043 float m_salary;
#0044 public :
#0045 CManager(const char* nm):CEmployee(nm){ m_salary = 15000.0; }
#0046 void setSalary(float salary) { m_salary = salary; }
#0047 float computePay();
#0048 };
#0049//---------------------------------------------------------------
#0050 void main()
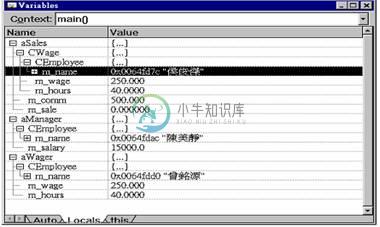
#0051 {
#0052 CManager aManager("陈美静");
#0053 CSales aSales("侯俊杰");
#0054 CWage aWager("曾铭源");
#0055 }
#0056//---------------------------------------------------------------
#0057 //虽然各类的 computePay函数都没有定义,但因为程序也没有调用之,所以无妨。
如此一来,CWage继承了CEmployee所有的成员(包括数据与函数),CSales 又继承了CWage 所有的成员(包括数据与函数)。在意义上, 相当于CSales拥有数据如下:
// private data of CEmployee
char m_name[30];
// private data of CWage
float m_wage;
float m_hours;
// private data of CSales
float m_comm;
float m_sale;
以及函数如下:
void setWage(float wg);
void setHours(float hrs);
void setCommission(float comm);
void setSale(float sales);
void computePay();
从Visual C++的除错器中,我们可以看到,上例的main执行之后,程序拥有三个对象,内容(我是指成员变量)分别为:
从薪水说起
虚函数的故事要从薪水的计算说起。根据不同职员的计薪方式,我设计 computePay 函数如下:
float CManager::computePay()
{
return m_salary; // 经理以「固定周薪」计薪。
}
float CWage::computePay()
{
return (m_wage * m_hours); // 时薪职员以「钟点费 * 每周工时」计薪。
}
float CSales::computePay()
{ // 销售员以「钟点费 * 每周工时」再加上「佣金 * 销售额」计薪。
return (m_wage * m_hours + m_comm * m_sale); // 语法错误。
}
但是CSales对象不能够直接取用CWage的m_wage和m_hours,因为它们是 private成员变量。所以是不是应该改为这样:
float CSales::computePay()
{
return computePay() + m_comm * m_sale;
}
这也不好,我们应该指明函数中所调用的 computePay 究归谁属——编译器没有厉害到能够自行判断而保证不出错。正确写法应该是:
float CSales::computePay()
{
return CWage::computePay() + m_comm * m_sale;
}
这就合乎逻辑了:销售员是一般职员的一种,他的薪水应该是以时薪职员的计薪方式作为底薪,再加上额外的销售佣金。我们看看实际情况,如果有一个销售员:
CSales aSales("侯俊杰");
那么侯俊杰的底薪应该是:
aSales.CWage::computePay(); // 这是销售员的底薪。注意语法。
而侯俊杰的全薪应该是 :
aSales.computePay(); // 这是销售员的全薪
结论是:要调用父类的函数,你必须使用scope resolution operator(::)明白指出。接下来我要触及对象类型的转换,这关系到指针的运用,更直接关系到为什么需要虚函数。了解它,对于application framework如MFC者的运用十分十分重要。
假设我们有两个对象:
CWage aWager;
CSales aSales("侯俊杰");
销售员是时薪职员之一,因此这样做是合理的:
aWager = aSales; // 合理,销售员必定是时薪职员。
这样就不合理:
aSales = aWager; // 错误,时薪职员未必是销售员。
如果你一定要转换,必须使用指针,并且明显地做类型转换(cast)动作 :
CWage* pWager;
CSales* pSales;
CSales aSales("侯俊杰");
pWager = &aSales; // 把一个「基类指针」指向派生类之对象,合理且自然。
pSales = (CSales *)pWager; //强迫转型。语法上可以,但不符合现实生活。
真实世界中某些时候我们会以「一种动物」来总称猫啊、狗啊、兔子猴子等等。为了某种便利(这个便利稍后即可看到),我们也会想以「一个通用的指针」表示所有可能的职员类型。无论如何,销售员、时薪职员、经理,都是职员,所以下面动作合情合理:
CEmployee* pEmployee;
CWage aWager("曾铭源");
CSales aSales("侯俊杰");
CManager aManager("陈美静");
pEmpolyee = &aWager; // 合理,因为时薪职员必是职员
pEmpolyee = &aSales; // 合理,因为销售员必是职员
pEmpolyee = &aManager; // 合理,因为经理必是职员
也就是说,你可以把一个「职员指针」指向任何一种职员。这带来的好处是程序设计的巨大弹性,譬如说你设计一个串列(linked list),各个元素都是职员(哪一种职员都可以),你的add函数可能因此希望有一个「职员指针」作为参数:
add(CEmployee* pEmp); // pEmp 可以指向任何一种职员
晴天霹雳
我们渐渐接触问题的核心。上述 C++ 性质使真实生活经验的确在计算机语言中仿真了出来,但是万里无云的日子里却出现了一个晴天霹雳:如果你以一个「基类之指针」指向一个「派生类之对象」,那么经由此指针,你就只能够调用基类(而不是派生类)所定义的函数。因此:
CSales aSales("侯俊杰");
CSales* pSales;
CWage* pWager;
pSales = &aSales;
pWager = &aSales; // 以「基类之指针」指向「派生类之对象」
pWager->setSales(800.0);//错误(编译器会检测出来),因为CWage并没有定义setSales 函数。
pSales->setSales(800.0);//正确,调用 CSales::setSales 函数。
虽然 pSales 和 pWager 指向同一个对象,但却因指针的原始类型而使两者之间有了差异。延续此例,我们看另一种情况:
pWager->computePay(); // 调用 CWage::computePay()
pSales->computePay(); // 调用 CSales::computePay()
虽然pSales和pWager实际上都指向CSales对象,但是两者调用的computePay 却不相同。到底调用到哪个函数,必须视指针的原始类型而定,与指针实际所指之对象无关。
三个结论
我们得到了三个结论:
1. 如果你以一个「基类之指针」指向「派生类之对象」,那么经由该指针你只能够调用基类所定义的函数。
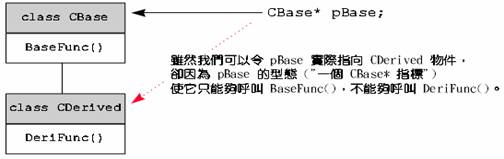
2. 如果你以一个「派生类之指针」指向一个「基类之对象」,你必须先做明显的转型动作(explicit cast)。这种作法很危险,不符合真实生活经验,在程序设计上也会带给程序员困惑。

3. 如果基类和派生类都定义了「相同名称之成员函数」,那么通过对象指针调用成员函数时,到底调用到哪一个函数,必须视该指针的原始类型而定,而不是视指针实际所指之对象的类型而定。这与第 1点其实意义相通。

得到这些结论后,看看什么事情会困扰我们。前面我曾提到一个由职员组成的串列,如果我想写一个 printNames 函数走访串列中的每一个元素并印出职员的名字,我们可以在CEmployee(最基类)中多加一个getName 函数,然后再设计一个while循环如下:
int count = 0;
CEmployee* pEmp;
...
while (pEmp = anIter.getNext())
{
count++;
cout << count << ' ' << pEmp->getName() << endl;
}
你可以把anIter.getNext想象是一个可以走访串列的函数,它传回 CEmPloyee*,也因此每一次获得的指针才可以调用定义于CEmployee中的 getName。
但是,由于函数的调用是依赖指针的原始类型而不管它实际上指向何方(何种对象),因此如果上述 while 循环中调用的是 pEmp->computePay,那么 while 循环所执行的将总是相同的运算,也就是 CEmployee::computePay,这就糟了(销售员领到经理的薪水还不糟吗)。更糟的是,我们根本没有定义 CEmployee::computePay,因为CEmployee只是个抽象概念(一个抽象类)。指针必须落实到实例类型上如CWage或CManager 或CSales,才有薪资计算公式。
计薪循环图
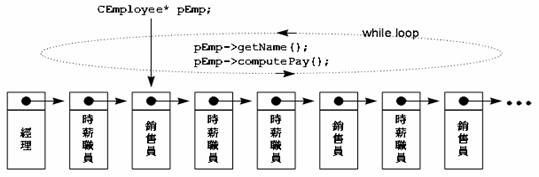
虚函数与一般化
我想你可以体会,上述的while 循环其实就是把动作「一般化」。「一般化」之所以重要,在于它可以把现在的、未来的情况统统纳入考虑。将来即使有另一种名曰「顾问」的职员,上述计薪循环应该仍然能够正常运作。当然啦,「顾问」的 computePay 必须设计好。
「一般化」是如此重要,解决上述问题因此也就迫切起来。我们需要的是什么呢?是能够「依旧以 CEmpolyee 指针代表每一种职员」,而又能够在「实际指向不同种类之职员」时,「调用到不同版本(不同类中)之 computePay」这种能力。
这种性质就是多态(polymorphism),靠虚函数来完成。
再次看看那张计薪循环图:
当pEmp指向经理,我希望pEmp->computePay是经理的薪水计算式,也就是CManager::computePay。
当pEmp指向销售员,我希望pEmp->computePay是销售员的薪水计算式,也就是CSales::computePay。
当pEmp指向时薪职员,我希望pEmp->computePay是时薪职员的薪水计算式,
也就是CWage::computePay。
虚函数正是为了对「如果你以一个基类之指针指向一个派生类之对象,那么透过该指针你就只能够调用基类所定义之成员函数」这条规则反其道而行的设计。
不必设计复杂的串列函数如add或getNext才能验证这件事,我们看看下面这个简单例子。如果我把职员一例中所有四个类的computePay 函数前面都加上 virtual关键字,使它们成为虚函数,那么:
CEmployee* pEmp;
CWage aWager("曾铭源");
CSales aSales("侯俊杰");
CManager aManager("陈美静");
pEmp = &aWager;
cout << pEmp->computePay(); // 调用的是 CWage::computePay
pEmp = &aSales;
cout << pEmp->computePay(); // 调用的是 CSales::computePay
pEmp = &aManager;
cout << pEmp->computePay(); // 调用的是 CManager::computePay
现在重新回到Shape例子,我打算让display 成为虚函数:
#0001 #include <iostream.h>
#0002 class CShape
#0003 {
#0004 public:
#0005 virtual void display() { cout << "Shape \n"; }
#0006 };
#0007 //------------------------------------------------
#0008 class CEllipse : public CShape
#0009 {
#0010 public:
#0011 virtual void display() { cout << "Ellipse \n"; }
#0012 };
#0013 //------------------------------------------------
#0014 class CCircle : public CEllipse
#0015 {
#0016 public:
#0017 virtual void display() { cout << "Circle \n"; }
#0018 };
#0019 //------------------------------------------------
#0020 class CTriangle : public CShape
#0021 {
#0022 public:
#0023 virtual void display() { cout << "Triangle \n"; }
#0024 };
#0025 //------------------------------------------------
#0026 class CRect : public CShape
#0027 {
#0028 public:
#0029 virtual void display() { cout << "Rectangle \n"; }
#0030 };
#0031 //------------------------------------------------
#0032 class CSquare : public CRect
#0033 {
#0034 public:
#0035 virtual void display() { cout << "Square \n"; }
#0036 };
#0037 //------------------------------------------------
#0038 void main()
#0039 {
#0040 CShape aShape;
#0041 CEllipse aEllipse;
#0042 CCircle aCircle;
#0043 CTriangle aTriangle;
#0044 CRect aRect;
#0045 CSquare aSquare;
#0046 CShape* pShape[6] = { &aShape,&aEllipse,&aCircle,&aTriangle,&aRect, &aSquare };
#0053 for(int i=0; i< 6; i++)
#0054 pShape[i]->display();
#0055 }
#0056 //------------------------------------------------
得到的结果是:Shape\n Ellipse\n Circle \n Triangle\n Rectangle\n Square
如果把所有类中的virtual 保留字拿掉,执行结果变成:Shape Shape Shape Shape Shape Shape
综合Employee 和Shape两例,第一个例子是:
pEmp = &aWager;
cout << pEmp->computePay();
pEmp = &aSales;
cout << pEmp->computePay();
pEmp = &aBoss; 这三进程序代码完全相同
cout << pEmp->computePay();
第二个例子是:
CShape* pShape[6];
for (int i=0; i< 6; i++)
pShape[i]->display(); // 此进程序代码执行了 6 次。
我们看到了一种奇特现象:程序代码完全一样(因为一般化了),执行结果却不相同。这就是虚函数的妙用。
如果没有虚函数这种东西,你还是可以使用 scope resolution operator(::)明白指出调用哪一个函数,但程序就不再那么优雅与弹性了。
从操作型定义来看,什么是虚函数呢?如果你预期派生类有可能重新定义某一个成员函数,那么你就在基类中把此函数设为 virtual。MFC 有两个十分十分重要的虚函数:与 document 有关的 Serialize 函数和与 view 有关的 OnDraw 函数。你应该在自己的 CMyDoc 和 CMyView 中改写这两个虚函数。
多态(Polymorphism)
你看,我们以相同的指令却唤起了不同的函数,这种性质称为Polymorphism,意思是 "the ability to assume many forms"(多态)。编译器无法在编译时期判断 pEmp->computePay到底是调用哪一个函数,必须在运行时才能评估之,这称为后期联编 late binding 或动态联编 dynamic binding。至于 C 函数或 C++ 的 non-virtual 函数,在编译时期就转换为一个固定地址的调用了,这称为前期联编 early binding 或静态联编 static binding。
Polymorphism 的目的,就是要让处理「基类之对象」的程序代码,能够完全透通地继续适当处理「派生类之对象」。
可以说,虚函数是了解多态(Polymorphism)以及动态联编的关键。同时,它也是了解如何使用 MFC 的关键。
让我再次提示你,当你设计一套类,你并不知道使用者会派生什么新的子类出来。如果动物世界中出现了新品种名曰雅虎,类使用者势必在 CAnimal 之下派生一个CYahoo。饶是如此,身为基类设计者的你,可以利用虚函数的特性,将所有动物必定会有的行为(例如哮叫roar),规划为虚函数,并且规划一些一般化动作(例如「让每一种动物发出一声哮叫」)。那么,虽然,你在设计基类以及这个一般化动作时,无法掌握使用者自行派生的子类,但只要他改写了 roar 这个虚函数,你的一般化对象操作动作自然就可以调用到该函数。
再次回到前述的Shape例子。我们说CShape是抽象的,所以它根本不该有 display这个动作。但为了在各实例派生类中绘图,我们又不得不在基类 CShape 加上display 虚函数。你可以定义它什么也不做(空函数):
class CShape
{
public:
virtual void display() { }
};
或只是给个消息:
class CShape
{
public:
virtual void display() { cout << "Shape \n"; }
};
这两种作法都不高明,因为这个函数根本就不应该被调用(CShape 是抽象的),我们根本就不应该定义它。不定义但又必须保留一块空间(spaceholder)给它,于是 C++ 提供了所谓的纯虚函数:
class CShape
{
public:
virtual void display() = 0; // 注意 "= 0"
};
纯虚函数不需定义其实际动作,它的存在只是为了在派生类中被重新定义,只是为了提供一个多态接口。只要是拥有纯虚函数的类,就是一种抽象类,它是不能够被实例化 (instantiate)的,也就是说,你不能根据它产生一个对象(你怎能说一种形状为 'Shape' 的物体呢)。如果硬要强渡关山,会换来这样的编译消息:
error : illegal attempt to instantiate abstract class.
关于抽象类,我还有一点补充。CCircle 继承了CShape 之后,如果没有改写CShape中的纯虚函数,那么CCircle 本身也就成为一个拥有纯虚函数的类,于是它也是一个抽象类。
是对虚函数做结论的时候了:
如果你期望派生类重新定义一个成员函数,那么你应该在基类中把此函数设为virtual。
以单一指令唤起不同函数,这种性质称为Polymorphism,意思是 "the ability to assume many forms",也就是多态。
虚函数是C++语言的Polymorphism 性质以及动态联编的关键。
既然抽象类中的虚函数不打算被调用,我们就不应该定义它,应该把它设为纯虚函数(在函数声明之后加上"=0" 即可)。
我们可以说,拥有纯虚函数者为抽象类(abstract Class),以别于所谓的实例类(concrete class)。
抽象类不能产生出对象实体,但是我们可以拥有指向抽象类之指针,以便于操作抽象类的各个派生类。
虚函数派生下去仍为虚函数,而且可以省略virtual关键词。
类与对象大解剖
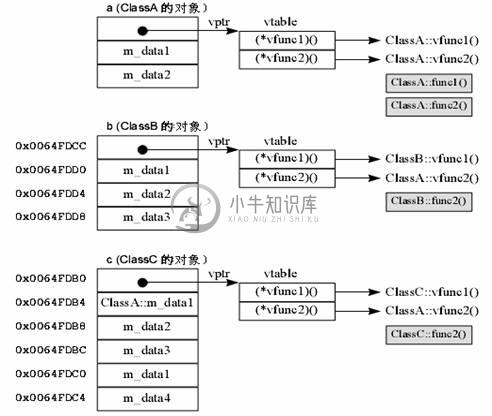
为了达到动态联编(后期联编)的目的,C++ 编译器通过某个表格,在运行时「间接」调用实际上欲联编的函数(注意「间接」这个字眼)。这样的表格称为虚函数表(常被称为 vtable)。每一个「内含虚函数的类」,编译器都会为它做出一个虚函数表,表中的每一个元素都指向一个虚函数的地址。此外,编译器当然也会为类加上一项成员变量,是一个指向该虚函数表的指针(常被称为 vptr)。举个例:
class Class1 {
public :
data1;
data2;
memfunc();
virtual vfunc1();
virtual vfunc2();
virtual vfunc3();
};
Class1 对象实体在内存中占据这样的空间:
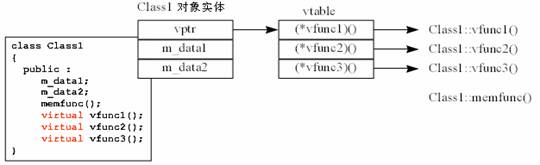
C++ 类的成员函数,你可以想象就是C语言中的函数。它只是被编译器改过名称,并增加一个参数(this 指针),因而可以处理调用者(C++ 对象)中的成员变量。所以,你并没有在 Class1 对象的内存区块中看到任何与成员函数有关的任何东西。
每一个由此类派生出来的对象,都有这么一个 vptr。当我们通过这个对象调用虚函数,事实上是通过 vptr 找到虚函数表,再找出虚函数的真正地址。
奥妙在于这个虚函数表以及这种间接调用方式。虚函数表的内容是依据类中的虚函数声明次序,一一填入函数指针。派生类会继承基类的虚函数表(以及所有其它可以继承的成员),当我们在派生类中改写虚函数时,虚函数表就受了影响:表中元素所指的函数地址将不再是基类的函数地址,而是派生类的函数地址。
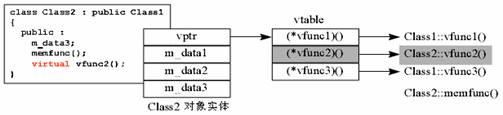
看看这个例子:
class Class2 : public Class1 {
public :
data3;
memfunc();
virtual vfunc2();
};
于是,一个「指向Class1所生对象」的指针,所调用的 vfunc2 就是 Class1::vfunc2,而一个「指向Class2 所生对象」的指针,所调用的 vfunc2 就是 Class2::vfunc2。动态联编机制,在运行时,根据虚函数表,做出了正确的选择。我们解开了第二道神秘。口说无凭,何不看点实际。观其地址,物焉廋哉,下面是一个测试程序:
#0001 #include <iostream.h>
#0002 #include <stdio.h>
#0004 class ClassA
#0005 {
#0006 public:
#0007 int m_data1;
#0008 int m_data2;
#0009 void func1() { }
#0010 void func2() { }
#0011 virtual void vfunc1() { }
#0012 virtual void vfunc2() { }
#0013 };
#0015 class ClassB : public ClassA
#0016 {
#0017 public:
#0018 int m_data3;
#0019 void func2() { }
#0020 virtual void vfunc1() { }
#0021 };
#0023 class ClassC : public ClassB
#0024 {
#0025 public:
#0026 int m_data1;
#0027 int m_data4;
#0028 void func2() { }
#0029 virtual void vfunc1() { }
#0030 };
#0032 void main()
#0033 {
#0034 cout << sizeof(ClassA) << endl;
#0035 cout << sizeof(ClassB) << endl;
#0036 cout << sizeof(ClassC) << endl;
#0038 ClassA a;
#0039 ClassB b;
#0040 ClassC c;
#0041
#0042 b.m_data1 = 1;
#0043 b.m_data2 = 2;
#0044 b.m_data3 = 3;
#0045 c.m_data1 = 11;
#0046 c.m_data2 = 22;
#0047 c.m_data3 = 33;
#0048 c.m_data4 = 44;
#0049 c.ClassA::m_data1 = 111;
#0050
#0051 cout << b.m_data1 << endl;
#0052 cout << b.m_data2 << endl;
#0053 cout << b.m_data3 << endl;
#0054 cout << c.m_data1 << endl;
#0055 cout << c.m_data2 << endl;
#0056 cout << c.m_data3 << endl;
#0057 cout << c.m_data4 << endl;
#0058 cout << c.ClassA::m_data1 << endl;
#0059
#0060 cout << &b << endl;
#0061 cout << &(b.m_data1) << endl;
#0062 cout << &(b.m_data2) << endl;
#0063 cout << &(b.m_data3) << endl;
#0064 cout << &c << endl;
#0065 cout << &(c.m_data1) << endl;
#0066 cout << &(c.m_data2) << endl;
#0067 cout << &(c.m_data3) << endl;
#0068 cout << &(c.m_data4) << endl;
#0069 cout << &(c.ClassA::m_data1) << endl;
#0070 }
执行结果与分析如下:
执行结果 意义 说明
12 Sizeof (ClassA) 2 个int 加上一个vptr
16 Sizeof (ClassB) 继承自ClassA,再加上1 个int
24 Sizeof (ClassC) 继承自ClassB,再加上2 个int
1 b.m_data1 的内容
2 b.m_data2 的内容
3 b.m_data3 的内容
11 c.m_data1 的内容
22 c.m_data2 的内容
33 c.m_data3 的内容
44 c.m_data4 的内容
111 c.ClassA::m_data1的内容
0x0064FDCC b 对象的起始地址 这个地址中的内容就是vptr
0x0064FDD0 b.m_data1 的地址
0x0064FDD4 b.m_data2 的地址
0x0064FDD8 b.m_data3 的地址
0x0064FDB0 c 对象的起始地址 这个地址中的内容就是vptr
0x0064FDC0 c.m_data1 的地址
0x0064FDB8 c.m_data2 的地址
0x0064FDBC c.m_data3 的地址
0x0064FDC4 c.m_data4 的地址
0x0064FDB4 c.ClassA::m_data1 的地址
a、b、c 对象的内容图标如下:
Object slicing与虚函数
我要在这里说明虚函数另一个极重要的行为模式。假设有三个类,阶层关系如下:
以程序表现如下:
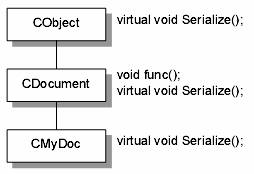
#0001 #include <iostream.h>
#0003 class CObject
#0004 {
#0005 public:
#0006 virtual void Serialize() { cout << "CObject::Serialize() \n\n"; }
#0007 };
#0009 class CDocument : public CObject
#0010 {
#0011 public:
#0012 int m_data1;
#0013 void func() { cout << "CDocument::func()" << endl;
#0014 Serialize();
#0015 }
#0017 virtual void Serialize(){cout << "CDocument::Serialize() \n\n"; }
#0018 };
#0020 class CMyDoc : public CDocument
#0021 {
#0022 public:
#0023 int m_data2;
#0024 virtual void Serialize() { cout << "CMyDoc::Serialize() \n\n"; }
#0025 };
#0026 //-------------------------------------------------------------
#0027 void main()
#0028 {
#0029 CMyDoc mydoc;
#0030 CMyDoc* pmydoc = new CMyDoc;
#0032 cout << "#1 testing" << endl;
#0033 mydoc.func();
#0035 cout << "#2 testing" << endl;
#0036 ((CDocument*)(&mydoc))->func();
#0038 cout << "#3 testing" << endl;
#0039 pmydoc->func();
#0041 cout << "#4 testing" << endl;
#0042 ((CDocument)mydoc).func();
#0043 }
由于CMyDoc自己没有func 函数,而它继承了CDocument 的所有成员,所以 main 之中的四个调用动作毫无问题都是调用CDocument::func。但,CDocument::func 中所调用Serialize 是哪一个类的成员函数呢?如果它是一般(non-virtual)函数,毫无问题应该是 CDocument::Serialize。但因为这是个虚函数,情况便有不同。以下是执行结果:
#1 testing
CDocument::func()
CMyDoc::Serialize()
#2 testing
CDocument::func()
CMyDoc::Serialize()
#3 testing
CDocument::func()
CMyDoc::Serialize()
#4 testing
CDocument::func()
CDocument::Serialize() <-- 注意
前三个测试都符合我们对虚函数的期望:既然派生类已经改写了虚函数 Serialize,那么理当调用派生类之Serialize 函数。这种行为模式非常频繁地出现在applicationframework 身上。后续当我追踪 MFC 原始代码时,遇此情况会再次提醒你。
第四项测试结果则有点出乎意料之外。你知道,派生对象通常都比基础对象大(我是指内存空间),因为派生对象不但继承其基类的成员,又有自己的成员。那么所谓的upcasting(向上强制转型):(CDocument)mydoc,将会造成对象的内容被切割(object slicing):
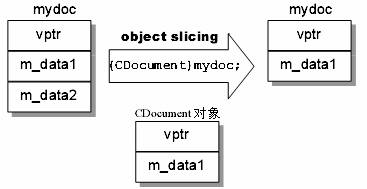
当我们调用:((CDocument)mydoc).func(); mydoc已经是一个被切割得剩下半条命的对象,而 func 内部调用虚函数 Serialize;后者将使用的「mydoc 的虚函数指针」虽然存在,它的值是什么呢?你是不是隐隐觉得有什么大灾难要发生?
幸运的是,由于 ((CDocument)mydoc).func() 是个传值而非传址动作,编译器以所谓的复制构造函数(copy constructor)把CDocument 对象内容复制了一份,使得mydoc的vtable 内容与CDocument对象的vtable 相同。本例虽没有明显做出一个复制构造函数,编译器会自动为你合成一个。
说这么多,总结就是,经过所谓的data slicing,本例的mydoc 真正变成了一个完完全全的 CDocument 对象。所以,本例的第四项测试结果也就水落石出了。注意,"upcasting" 并不是惯用的动作,应该小心,甚至避免。
静态成员(变量与函数)
我想你已经很清楚了,如果你依据一个类产生出三个对象,每一个对象将各有一份成员变量。有时候这并不是你要的。假设你有一个类,专门用来处理存款账户,它至少应该要有存户的姓名、地址、存款额、利率等成员变量:
class SavingAccount
{
private:
char m_name[40]; // 存户姓名
char m_addr[60]; // 存户地址
double m_total; // 存款额
double m_rate; // 利率
...
};
这家行库采用浮动利率,每个账户的利息都是根据当天的挂牌利率来计算。这时候m_rate 就不适合成为每个账户对象中的一笔数据,否则每天一开市,光把所有账户内容叫出来,修改 m_rate 的值,就花掉不少时间。m_rate 应该独立在各对象之外,成为类独一无二的数据。怎么做?在 m_rate 前面加上 static 修饰词即可:
class SavingAccount
{
private:
char m_name[40]; // 存户姓名
char m_addr[60]; // 存户地址
double m_total; // 存款额
static double m_rate; // 利率
...
};
static 成员变量不属于对象的一部分,而是类的一部分,所以程序可以在还没有诞生任何对象的时候就处理此种成员变量。但首先你必须初始化它。
不要把 static 成员变量的初始化动作安排在类的构造函数中,因为构造函数可能一再被调用,而变量的初值却只应该设定一次。也不要把初始化动作安排在头文件中,因为它可能会被含入许多地方,因此也就可能被执行许多次。你应该在实现文件中且类以外的任何位置设定其初值。例如在 main 之中,或全局函数中,或任何函数之外:
double SavingAccount::m_rate = 0.0075; // 设立 static 成员变量的初值
void main() { ... }
这么做可曾考虑到 m_rate 是个 private 数据?没关系,设定 static 成员变量初值时,不受任何存取权限的束缚。请注意,static 成员变量的类型也出现在初值设定句中,因为这是一个初值设定动作,不是一个数量指定(assignment)动作。事实上,static 成员变量是在这时候(而不是在类声明中)才定义出来的。如果你没有做这个初始化动作,会产生链接错误:
error LNK2001: unresolved external symbol "private: static double
SavingAccount::m_rate"([email protected]@@2HA)
下面是存取static成员变量的一种方式,注意,此刻还没有诞生任何对象实体:
// 第一种存取方式
void main()
{
SavingAccount::m_rate = 0.0075; // 欲此行成立,须把 m_rate 改为 public
}
下面这种情况则是产生一个对象后,通过对象来处理static成员变量:
// 第二种存取方式
void main()
{
SavingAccount myAccount;
myAccount.m_rate = 0.0075; // 欲此行成立,须把 m_rate 改为 public
}
你得搞清楚一个观念,static 成员变量并不是因为对象的实现而才得以实现,它本来就存在,你可以想象它是一个全局变量。因此,第一种处理方式在意义上比较不会给人错误的印象。
只要access level允许,任何函数(包括全局函数或成员函数,static 或 non-static)都可以存取static成员变量。但如果你希望在产生任何object之前就存取其class的private static 成员变量,则必须设计一个static成员函数(例如以下的 setRate):
class SavingAccount
{
private:
char m_name[40]; // 存户姓名
char m_addr[60]; // 存户地址
double m_total; // 存款额
static double m_rate; // 利率
...
public:
static void setRate(double newRate) { m_rate = newRate; }
...
};
double SavingAccount::m_rate = 0.0075; // 设立 static 成员变量的初值
void main()
{
SavingAccount::setRate(0.0074); // 直接调用类的 static 成员函数
SavingAccount myAccount;
myAccount.setRate(0.0074); // 通过对象调用 static 成员函数
}
由于static成员函数不需要借助任何对象,就可以被调用执行,所以编译器不会为它暗加一个this指针。也因为如此,static成员函数无法处理类之中的 non-static 成员变量。还记得吗,我在前面说过,成员函数之所以能够以单一一份函数代码处理各个对象的数据而不紊乱,完全靠的是this指针的指示。
static 成员函数「没有this 参数」的这种性质,正是我们的MFC应用程序在准备callback函数时所需要的。第6章的 Hello World 例中我就会举这样一个实例。
C++ 程序的生与死:兼谈构造函数与析构函数
C++ 的new运算符和C的malloc函数都是为了配置内存,但前者比之后者的优点是,new不但配置对象所需的内存空间时,同时会引发构造函数的执行。
所谓构造函数(constructor),就是对象诞生后第一个执行(并且是自动执行)的函数,它的函数名称必定要与类名称相同。
相对于构造函数,自然就有个析构函数(destructor),也就是在对象行将毁灭但未毁灭之前一刻,最后执行(并且是自动执行)的函数,它的函数名称必定要与类名称相同,再在最前面加一个~符号。
一个有着阶层架构的类群组,当派生类的对象诞生之时,构造函数的执行是由最基类(most based)至最尾端派生类(most derived);当对象要毁灭之前,析构函数的执行则是反其道而行。第3章的 frame1 程序对此有所示范。
我以实例展示不同种类之对象的构造函数执行时机。程序代码中的编号请对照执行结果。
#0001 #include <iostream.h>
#0002 #include <string.h>
#0004 class CDemo
#0005 {
#0006 public:
#0007 CDemo(const char* str);
#0008 ~CDemo();
#0009 private:
#0010 char name[20];
#0011 };
#0013 CDemo::CDemo(const char* str) // 构造函数
#0014 {
#0015 strncpy(name, str, 20);
#0016 cout << "Constructor called for " << name << '\n';
#0017 }
#0019 CDemo::~CDemo()// 析构函数
#0020 {
#0021 cout << "Destructor called for " << name << '\n';
#0022 }
#0024 void func()
#0025 {
#0026 CDemo LocalObjectInFunc("LocalObjectInFunc"); // in stack ⑤
#0027 static CDemo StaticObject("StaticObject"); // local static ⑥
#0028 CDemo* pHeapObjectInFunc=new CDemo("HeapObjectInFunc");//in heap ⑦
#0030 cout << "Inside func" << endl; ⑧
#0032 } ⑨
#0034 CDemo GlobalObject("GlobalObject"); // global static ①
#0036 void main()
#0037 {
#0038 CDemo LocalObjectInMain("LocalObjectInMain"); // in stack ②
#0039 CDemo* pHeapObjectInMain=new CDemo("HeapObjectInMain");//in heap ③
#0041 cout << "In main, before calling func\n";④
#0042 func();
#0043 cout << "In main, after calling func\n"; ➓
#0045 } ➀ ② ③
以下是执行结果:
➀ Constructor called for GlobalObject
② Constructor called for LocalObjectInMain
③ Constructor called for HeapObjectInMain
④ In main, before calling func
⑤ Constructor called for LocalObjectInFunc
⑥ Constructor called for StaticObject
⑦ Constructor called for HeapObjectInFunc
⑧ Inside func
⑨ Destructor called for LocalObjectInFunc
➓ In main, after calling func
➀ Destructor called for LocalObjectInMain
② Destructor called for StaticObject
③ Destructor called for GlobalObject
我的结论是:
对于全局对象(如本例之GlobalObject),程序一开始,其构造函数就先被执行(比程序进入点更早);程序即将结束前其析构函数被执行。MFC 程序就有这样一个全局对象,通常以application object 称呼之,你将在第6章看到它。
对于局部对象,当对象诞生时,其构造函数被执行;当程序流程将离开该对象的存活范围(以至于对象将毁灭),其析构函数被执行。
对于静态(static)对象,当对象诞生时其构造函数被执行;当程序将结束时(此对象因而将遭致毁灭)其析构函数才被执行,但比全局对象的析构函数早一步执行。
对于以new方式产生出来的局部对象,当对象诞生时其构造函数被执行。析构式则在对象被delete 时执行(上例程序未示范)。
四种不同的对象生存方式(in stack、in heap、global、local static)
既然谈到了static对象,就让我把所有可能的对象生存方式及其构造函数调用时机做个整理。所有作法你都已经在前一节的小程序中看过。
在C++ 中,有四种方法可以产生一个对象。第一种方法是在堆栈(stack)之中产生它:
void MyFunc()
{
CFoo foo; // 在堆栈(stack)中产生 foo 对象
...
}
第二种方法是在堆积(heap)之中产生它:
void MyFunc()
{
...
CFoo* pFoo = new CFoo(); // 在堆积(heap)中产生对象
}
第三种方法是产生一个全局对象(同时也必然是个静态对象):
CFoo foo; // 在任何函数范围之外做此动作
第四种方法是产生一个局部静态对象:
void MyFunc()
{
static CFoo foo; // 在函数范围(scope)之内的一个静态对象
...
}
不论任何一种作法,C++ 都会产生一个针对CFoo 构造函数的调用动作。前两种情况,C++ 在配置内存 -- 来自堆栈(stack)或堆积(heap)-- 之后立刻产生一个隐藏的(你的原始代码中看不出来的)构造函数调用。第三种情况,由于对象实现于任何「函数活动范围(function scope)」之外,显然没有地方来安置这样一个构造函数调用动作。
是的,第三种情况(静态全局对象)的构造函数调用动作必须靠startup代码帮忙。startup代码是什么?是更早于程序进入点(main 或 WinMain)执行起来的代码,由 C++ 编译器提供,被链接到你的程序中。startup 代码可能做些像函数库初始化、进程信息设立、I/O stream 产生等等动作,以及对 static 对象的初始化动作(也就是调用其构造函数)。
当编译器编译你的程序,发现一个静态对象,它会把这个对象加到一个串列之中。更精确地说则是,编译器不只是加上此静态对象,它还加上一个指针,指向对象之构造函数及其参数(如果有的话)。把控制权交给程序进入点(main 或 WinMain)之前,startup代码会快速在该串列上移动,调用所有登记有案的构造函数并使用登记有案的参数,于是就初始化了你的静态对象。
第四种情况(局部静态对象)相当类似C语言中的静态局部变量,只会有一个实体(instance)产生,而且在固定的内存上(既不是stack 也不是heap)。它的构造函数在控制权第一次移转到其声明处(也就是在MyFunc第一次被调用)时被调用。
所谓 "Unwinding"
C++ 对象依其生存空间,适当地依照一定的顺序被析构(destructed)。但是如果发生异常情况(exception),而程序设计了异常情况处理程序(exception handling),控制权就会截弯取直地「直接跳」到你所设定的处理例程去,这时候堆栈中的 C++ 对象有没有机会被析构?这得视编译器而定。如果编译器有支持 unwinding 功能,就会在一个异常情况发生时,将堆栈中的所有对象都析构掉。
关于异常情况(exception)及异常处理(exception handling),稍后有一节讨论之。
运行时类型信息(RTTI)
我们有可能在程序执行过程中知道某个对象是属于哪一种类吗?这种在C++ 中称为运行时类型信息(Runtime Type Information,RTTI)的能力,晚近较先进的编译器如Visual C++ 4.0 和Borland C++ 5.0 才开始广泛支持。以下是一个实例:
#0001 // RTTI.CPP - built by C:\> cl.exe -GR rtti.cpp <ENTER>
#0002 #include <typeinfo.h>
#0003 #include <iostream.h>
#0004 #include <string.h>
#0006 class graphicImage
#0007 {
#0008 protected:
#0009 char name[80];
#0011 public:
#0012 graphicImage()
#0013 {
#0014 strcpy(name,"graphicImage");
#0015 }
#0017 virtual void display()
#0018 {
#0019 cout << "Display a generic image." << endl;
#0020 }
#0022 char* getName()
#0023 {
#0024 return name;
#0025 }
#0026 };
#0027 //-------------------------------------------------------------
#0028 class GIFimage : public graphicImage
#0029 {
#0030 public:
#0031 GIFimage()
#0032 {
#0033 strcpy(name,"GIFimage");
#0034 }
#0036 void display()
#0037 {
#0038 cout << "Display a GIF file." << endl;
#0039 }
#0040 };
#0042 class PICTimage : public graphicImage
#0043 {
#0044 public:
#0045 PICTimage()
#0046 {
#0047 strcpy(name,"PICTimage");
#0048 }
#0050 void display()
#0051 {
#0052 cout << "Display a PICT file." << endl;
#0053 }
#0054 };
#0055 //------------------------------------------------------------
#0056 void processFile(graphicImage *type)
#0057 {
#0058 if (typeid(GIFimage) == typeid(*type))
#0059 {
#0060 ((GIFimage *)type)->display();
#0061 }
#0062 else if (typeid(PICTimage) == typeid(*type))
#0063 {
#0064 ((PICTimage *)type)->display();
#0065 }
#0066 else
#0067 cout << "Unknown type! " << (typeid(*type)).name() << endl;
#0068 }
#0070 void main()
#0071 {
#0072 graphicImage *gImage = new GIFimage();
#0073 graphicImage *pImage = new PICTimage();
#0075 processFile(gImage);
#0076 processFile(pImage);
#0077 }
执行结果如下:
Display a GIF file.
Display a PICT file.
这个程序与RTTI相关的地方有三个:
1. 编译时需选用/GR 选项(/GR 的意思是enable C++ RTTI)
2. 含入typeinfo.h
3. 新的typeid 运算符。这是一个重载(overloading)运算符,重载的意思就是拥有一个以上的型式,你可以想象那是一种静态的多态(Polymorphism)。typeid的参数可以是类名称(如本例#58 左),也可以是对象指针(如本例#58 右)。它传回一个type_info&。type_info 是一个类,定义于typeinfo.h 中:
class type_info {
public:
virtual ~type_info();
int operator==(const type_info& rhs) const;
int operator!=(const type_info& rhs) const;
int before(const type_info& rhs) const;
const char* name() const;
const char* raw_name() const;
private:
...
};
虽然Visual C++编译器自从4.0 版已经支持RTTI,但MFC 4.x并未使用编译器的能力完成其对RTTI 的支持。MFC有自己一套沿用已久的办法(从1.0 版就开始了)。喔,不要因为 MFC 的作法特殊而非难它,想想看它的悠久历史。
MFC的RTTI能力牵扯到一组非常神秘的宏(DECLARE_DYNAMIC 、 IMPLEMENT_DYNAMIC)和一个非常神秘的类(CRuntimeClass)。MFC 程序员都知道怎么用它,却没几个人懂得其运作原理。大道不过三两行,说穿不值一文钱,下一章我就模拟出一个 RTTI 的DOS 版本给你看。
动态生成(Dynamic Creation)
面向对象术语中有一个名为persistence,意思是永续存留。放在RAM中的东西,生命受到电力的左右,不可能永续存留;唯一的办法是把它写到文件去。MFC 的一个术语Serialize,就是做有关文件读写的永续存留动作,并且实做作出一个虚函数,就叫作Serialize。
看起来永续存留与本节的主题「动态生成」似乎没有什么干连。有!你把你的数据储存到文件,这些数据很可能(通常是)对象中的成员变量;我把它读出来后,势必要依据文件上的记载,重新new 出那些个对象来。问题在于,即使我的程序有那些类定义(就算我的程序和你的程序有一样的内容好了),我能够这么做吗:
char className[30] = getClassName(); // 从文件(或使用者输入)获得一个类名称
CObject* obj = new classname; // 这一行行不通
首先,new classname 这个动作就过不了关。其次,就算过得了关,new 出来的对象究竟该是什么类类型?虽然以一个指向MFC 类老祖宗(CObject)的对象指针来容纳它绝对没有问题,但终不好总是如此吧!不见得这样子就能够满足你的程序需求啊。
显然,你能够以Serialize函数写文件,我能够以Serialize函数读文件,但我就是没办法恢复你原来的状态—— 除非我的程序能够「动态生成」。
MFC支持动态生成,靠的是一组非常神秘的宏( DECLARE_DYNCREATE 、 IMPLEMENT_DYNCREATE)和一个非常神秘的类(CRuntimeClass)。第3章中我将把它抽丝剥茧,以一个 DOS 程序仿真出来。
异常处理(Exception Handling)
Exception(异常情况)是一个颇为新鲜的 C++ 语言特征,可以帮助你管理运行时的错误,特别是那些发生在深度巢状(nested)函数调用之中的错误。Watcom C++ 是最早支持ANSI C++异常情况的编译器,Borland C++ 4.0随后跟进,然后是 Microsoft Visual C++ 和 Symantec C++。现在,这已成为 C++ 编译器必需支持的项目。
C++ 的exception 基本上是与C的setjmp和longjmp函数对等的东西,但它增加了一些功能,以处理 C++ 程序的特别需求。从深度巢状的例程调用中直接以一条快捷方式撤回到异常情况处理例程(exception handler),这种「错误管理方式」远比结构化程序中经过层层的例程传回一系列的错误状态来的好。事实上exception handling是MFC和OWL两个application frameworks 的防弹中心。
C++ 导入了三个新的 exception 保留字:
1.try。之后跟随一段以{ }圈出来的程序代码,exception可能在其中发生。
2.catch。之后跟随一段以{ } 圈出来的程序代码,那是exception 处理例程之所在。catch 应该紧跟在 try 之后。
3.throw。这是一个指令,用来产生(丢出)一个exception。
下面是个实例 :
try {
// try block.
}
catch (char *p) {
printf("Caught a char* exception, value %s\n",p);
}
catch (double d) {
printf("Caught a numeric exception, value %g\n",d);
}
catch (...) { // catch anything
printf("Caught an unknown exception\n");
}
MFC早就支持exception,不过早期它用的是非标准语法。Visual C++ 4.0 编译器本身支持完整的C++ exceptions,MFC也因此有了两个exception 版本:你可以使用语言本身提供的性能,也可以沿用MFC古老的方法(以宏形式出现)。人们曾经因为MFC 的方案不同于ANSI标准而非难它,但是不要忘记它已经运作了多少年。
MFC的exceptions机制是以宏和exception types为基础。这些宏类似C++ 的exception 保留字,动作也满像。MFC以下列宏仿真C++ exception handling:
TRY
CATCH(type,object)
AND_CATCH(type,object)
END_CATCH
CATCH_ALL(object)
AND_CATCH_ALL(object)
END_CATCH_ALL
END_TRY
THROW()
THROW_LAST()
MFC所使用的语法与日渐浮现的标准稍微不同,不过其间差异微不足道。为了以MFC捕捉 exceptions,你应该建立一个TRY 区块,下面接着CATCH 区块:
TRY {
// try block.
}
CATCH (CMemoryException, e) {
printf("Caught a memory exception.\n");
}
AND_CATCH_ALL (e) {
printf("Caught an exception.\n");
}
END_CATCH_ALL
THROW宏相当于C++语言中的throw指令;你以什么类型做为THROW的参数,就会有一个相对应的 AfxThrow_ 函数被调用(这是台面下的行为):
以下是MFC 4.x 的exceptions 宏定义 :

// in AFX.H
////////////////////////////////////////////////////////////////////
// Exception macros using try, catch and throw
// (for backward compatibility to previous versions of MFC)
#ifndef _AFX_OLD_EXCEPTIONS
#define TRY { AFX_EXCEPTION_LINK _afxExceptionLink; try {
#define CATCH(class, e) } catch (class* e) \
{ ASSERT(e->IsKindOf(RUNTIME_CLASS(class))); \
_afxExceptionLink.m_pException = e;
#define AND_CATCH(class, e) } catch (class* e) \
{ ASSERT(e->IsKindOf(RUNTIME_CLASS(class))); \
_afxExceptionLink.m_pException = e;
#define END_CATCH } }
#define THROW(e) throw e
#define THROW_LAST() (AfxThrowLastCleanup(), throw)
// Advanced macros for smaller code
#define CATCH_ALL(e) } catch (CException* e) \
{ { ASSERT(e->IsKindOf(RUNTIME_CLASS(CException))); \
_afxExceptionLink.m_pException = e;
#define AND_CATCH_ALL(e) } catch (CException* e) \
{ { ASSERT(e->IsKindOf(RUNTIME_CLASS(CException))); \
_afxExceptionLink.m_pException = e;
#define END_CATCH_ALL } } }
#define END_TRY } catch (CException* e) \
{ ASSERT(e->IsKindOf(RUNTIME_CLASS(CException))); \
_afxExceptionLink.m_pException = e; } }
#else //_AFX_OLD_EXCEPTIONS
////////////////////////////////////////////////////////////////////
// Exception macros using setjmp and longjmp
// (for portability to compilers with no support for C++ exception handling)
#define TRY \
{ AFX_EXCEPTION_LINK _afxExceptionLink; \
if (::setjmp(_afxExceptionLink.m_jumpBuf) == 0)
#define CATCH(class, e) \
else if (::AfxCatchProc(RUNTIME_CLASS(class))) \
{ class* e = (class*)_afxExceptionLink.m_pException;
#define AND_CATCH(class, e) \
} else if (::AfxCatchProc(RUNTIME_CLASS(class))) \
{ class* e = (class*)_afxExceptionLink.m_pException;
#define END_CATCH \
} else { ::AfxThrow(NULL); } }
#define THROW(e) AfxThrow(e)
#define THROW_LAST() AfxThrow(NULL)
// Advanced macros for smaller code
#define CATCH_ALL(e) \
else { CException* e = _afxExceptionLink.m_pException;
#define AND_CATCH_ALL(e) \
} else { CException* e = _afxExceptionLink.m_pException;
#define END_CATCH_ALL } }
#define END_TRY }
#endif //_AFX_OLD_EXCEPTIONS
Template
这并不是一本C++书籍,我也并不打算介绍太多距离「运用 MFC」主题太远的C++论题。Template 虽然很重要,但它与「运用MFC」有什么关系?有!第8章当我们开始设计 Scribble 程序时,需要用到MFC 的collection classes,而这一组类自从MFC 3.0以来就有了template 版本(因为Visual C++ 编译器从 2.0 版开始支持 C++ template)。运用之前,我们总该了解一下新的语法、精神、以及应用。
到底什么是template?重要性如何?Kaare Christian在1994/01/25 的 PC-Magazine上有一篇文章,说得很好:
无性生殖并不只是存在于遗传工程上,对程序员而言它也是一个由来已久的动作。过去,我们只不过是以一个简单而基本的工具,也就是一个文字编辑器,重制我们的程序代码。今天,C++ 提供给我们一个更好的繁殖方法:template。
复制一段既有程序代码的一个最平常的理由就是为了改变数据类型。举个例子,假设你写了一个绘图函数,使用整数 x, y 坐标;突然之间你需要相同的程序代码,但坐标值改采long。你当然可以使用一个文字编辑器把这段代码复制一份,然后把其中的数据类型改变过来。有了C++,你甚至可以使用重载(overloaded)函数,那么你就可以仍旧使用相同的函数名称。函数的重载的确使我们有比较清爽的程序代码,但它们意味着你还是必须在你的程序的许多地方维护完全相同的算法。
C语言对此问题的解答是:使用宏。虽然你因此对于相同的算法只需写一次程序代码,但宏有它自己的缺点。第一,它只适用于简单的功能。第二个缺点比较严重:宏不提供数据类型检验,因此牺牲了 C++ 的一个主要效益。第三个缺点是:宏并非函数,程序中任何调用宏的地方都会被编译器前置处理器原原本本地插入宏所定义的那一段代码,而非只是一个函数调用,因此你每使用一次宏,你的执行文件就会膨胀一点。
Templates 提供比较好的解决方案,它把「一般性的算法」和其「对数据类型的实现部分」区分开来。你可以先写算法的程序代码,稍后在使用时再填入实际数据类型。新的 C++ 语法使「数据类型」也以参数的姿态出现。有了 template,你可以拥有宏「只写一次」的优点,以及重载函数「类型检验」的优点。
C++ 的template 有两种,一种针对function,另一种针对class。
Template Functions
假设我们需要一个计算数值幂次方的函数,名曰power。我们只接受正幂次方数,如果是负幂次方,就让结果为0。
对于整数,我们的函数应该是这样:
#0001 int power(int base, int exponent)
#0002 {
#0003 int result = base;
#0004 if (exponent == 0) return (int)1;
#0005 if (exponent < 0) return (int)0;
#0006 while (--exponent) result *= base;
#0007 return result;
#0008 }
对于长整数,函数应该是这样:
#0001 long power(long base, int exponent)
#0002 {
#0003 long result = base;
#0004 if (exponent == 0) return (long)1;
#0005 if (exponent < 0) return (long)0;
#0006 while (--exponent) result *= base;
#0007 return result;
#0008 }
对于浮点数,我们应该...,对于复数,我们应该...。喔喔,为什么不能够把数据类型也变成参数之一,在使用时指定呢?是的,这就是 template 的妙用:
template <class T> T power(T base, int exponent);
写成两行或许比较清楚:
template <class T>
T power(T base, int exponent);
这样的函数声明是以一个特殊的template前缀开始,后面紧跟着一个参数列(本例只一个参数)。容易让人迷惑的是其中的 "class" 字眼,它其实并不一定表示C++的class,它也可以是一个普通的数据类型。<class T> 只不过是表示:T 是一种类型,而此一类型将在调用此函数时才给予。
下面就是power函数的template版本:
#0001 template <class T>
#0002 T power(T base, int exponent)
#0003 {
#0004 T result = base;
#0005 if (exponent == 0) return (T)1;
#0006 if (exponent < 0) return (T)0;
#0007 while (--exponent) result *= base;
#0008 return result;
#0009 }
传回值必须确保为类型T,以吻合template函数的声明。
下面是template函数的调用方法:
#0001 #include <iostream.h>
#0002 void main()
#0003 {
#0004 int i = power(5, 4);
#0005 long l = power(1000L, 3);
#0006 long double d = power((long double)1e5, 2);
#0008 cout << "i= " << i << endl;
#0009 cout << "l= " << l << endl;
#0010 cout << "d= " << d << endl;
#0011 }
执行结果如下:
i= 625
l= 1000000000
d= 1e+010
在第一次调用中,T变成int,在第二次调用中,T变成long。而在第三次调用中,T 又成为了一个 long double。但如果调用时候把数据类型混乱掉了,像这样:
int i = power(1000L, 4); // 基值是个 long,传回值却是个 int。错误示范!
编译时就会出错。
template 函数的数据类型参数 T 究竟可以适应多少种类型?我要说,几乎「任何数据类型」都可以,但函数中对该类型数值的任何运算动作,都必须支持——否则编译器就不知道该怎么办了。以 power 函数为例,它对于 result 和 base 两个数值的运算动作有:
1. T result = base;
2. return (T)1;
3. return (T)0;
4. result *= base;
5. return result;
C++ 所有内建数据类型如int或long都支持上述运算动作。但如果你为某个 C++ 类产生一个 power 函数,那么这个C++类必须包含适当的成员函数以支持上述动作。
如果你打算在template函数中以C++ 类代替class T,你必须清楚知道哪些运算动作曾被使用于此一函数中,然后在你的C++类中把它们全部实现出来。否则,出现的错误耐人寻味。
Template Classes
我们也可以建立template classes,使它们能够神奇地操作任何类型的数据。下面这个例子是让CThree 类储存三个成员变量,成员函数Min传回其中的最小值,成员函数Max则传回其中的最大值。我们把它设计为template class,以便这个类能适用于各式各样的数据类型:
#0001 template <class T>
#0002 class CThree
#0003 {
#0004 public :
#0005 CThree(T t1, T t2, T t3);
#0006 T Min();
#0007 T Max();
#0008 private:
#0009 T a, b, c;
#0010 };
语法还不至于太稀奇古怪,把T看成是大家熟悉的int或float也就是了。下面是成员函数的定义:
#0001 template <class T>
#0002 T CThree<T>::Min()
#0003 {
#0004 T minab = a < b ? a : b;
#0005 return minab < c ? minab : c;
#0006 }
#0008 template <class T>
#0009 T CThree<T>::Max()
#0010 {
#0011 T maxab = a < b ? b : a;
#0012 return maxab < c ? c : maxab;
#0013 }
#0015 te mplate <class T>
#0016 CThree <T>::CThree(T t1, T t2, T t3) :
#0017 a(t1), b(t2), c(t3)
#0018 {
#0019 return;
#0020 }
这里就得多注意些了。每一个成员函数前都要加上template <class T>,而且类名称应该使用CThree<T>。
以下是 template class 的使用方式:
#0001 #include <iostream.h>
#0002 void main()
#0003 {
#0004 CThree<int> obj1(2, 5, 4);
#0005 cout << obj1.Min() << endl;
#0006 cout << obj1.Max() << endl;
#0008 CThree<float> obj2(8.52, -6.75, 4.54);
#0009 cout << obj2.Min() << endl;
#0010 cout << obj2.Max() << endl;
#0012 CThree<long> obj3(646600L, 437847L, 364873L);
#0013 cout << obj3.Min() << endl;
#0014 cout << obj3.Max() << endl;
#0015 }
执行结果如下:
2
5
-6.75
8.52
364873
646600
稍早我曾说过,只有当 template 函数对于数据类型 T支持所有必要的运算动作时,T 才得被视为有效。此一限制对于template classes亦属实。为了针对某些类产生一个CThree,该类必须提供copy构造函数以及operator<,因为它们是Min和Max成员函数中对 T 的运算动作。
但是如果你用的是别人template classes,你又如何知道什么样的运算动作是必须的呢?唔,该template classes的说明文件中应该有所说明。如果没有,只有原始代码才能揭露秘密。C++ 内建数据类型如int和float等不需要在意这份要求,因为所有内建的数据型别都支持所有的标准运算动作。
Templates 的编译与链接
对程序员而言C++ templates可说是十分容易设计与使用,但对于编译器和链接器而言却是一大挑战。编译器遇到一个template时,不能够立刻为它产生机器代码,它必须等待,直到template被指定某种类型。从程序员的观点来看,这意味着template function或template class的完整定义将出现在 template 被使用的每一个角落,否则,编译器就没有足够的信息可以帮助产生目的代码。当多个源文件使用同一个 template 时,事情更趋复杂。
随着编译器的不同,掌握这种复杂度的技术也不同。有一个常用的技术,Borland 称之为Smart,应该算是最容易的:每一个使用Template 的程序代码的目的文件中都存在有template代码,链接器负责复制和删除。
假设我们有一个程序,包含两个源文件A.CPP 和B.CPP,以及一个THREE.H(其内定义了一个template类,名为CThree)。A.CPP 和 B.CPP 都含入 THREE.H。如果 A.CPP以 int 和 double 使用这个template 类,编译器将在 A.OBJ 中产生 int 和 double 两种版本的template 类可执行代码。如果 B.CPP 以 int 和 float 使用这个 template 类,编译器将在 B.OBJ中产生int和 float 两种版本的template类可执行代码。即使虽然A.OBJ中已经有一个 int 版了,编译器没有办法知道。
然后,在链接过程中,所有重复的部分将被删除。请看图 2-1。
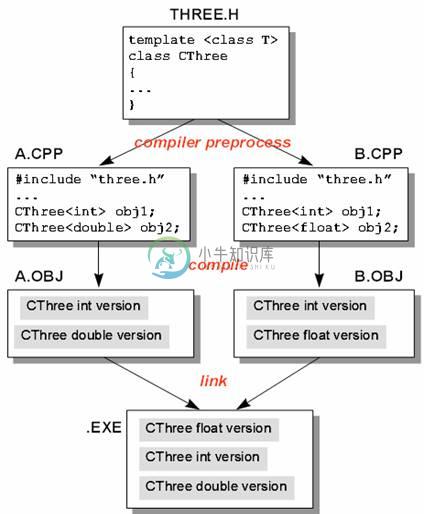
图2-1 链接器会把所有赘余的template 代码剔除。这在Borland 链接器里
头称为smart技术。其它链接器亦使用类似的技术。