
大话程序猿眼里的高并发之续篇
分层,分割,分布式
大型网站要很好支撑高并发,这是需要长期的规划设计
在初期就需要把系统进行分层,在发展过程中把核心业务进行拆分成模块单元,根据需求进行分布式部署,可以进行独立团队维护开发。
- 分层
- 将系统在横向维度上切分成几个部分,每个部门负责一部分相对简单并比较单一的职责,然后通过上层对下层的依赖和调度组成一个完整的系统
- 比如把电商系统分成:应用层,服务层,数据层。(具体分多少个层次根据自己的业务场景)
- 应用层:网站首页,用户中心,商品中心,购物车,红包业务,活动中心等,负责具体业务和视图展示
- 服务层:订单服务,用户管理服务,红包服务,商品服务等,为应用层提供服务支持
- 数据层:关系数据库,nosql数据库 等,提供数据存储查询服务
- 分层架构是逻辑上的,在物理部署上可以部署在同一台物理机器上,但是随着网站业务的发展,必然需要对已经分层的模块分离部署,分别部署在不同的服务器上,使网站可以支撑更多用户访问
- 分割
- 在纵向方面对业务进行切分,将一块相对复杂的业务分割成不同的模块单元
- 包装成高内聚低耦合的模块不仅有助于软件的开发维护,也便于不同模块的分布式部署,提高网站的并发处理能力和功能扩展
- 比如用户中心可以分割成:账户信息模块,订单模块,充值模块,提现模块,优惠券模块等
- 分布式
- 分布式应用和服务,将分层或者分割后的业务分布式部署,独立的应用服务器,数据库,缓存服务器
- 当业务达到一定用户量的时候,再进行服务器均衡负载,数据库,缓存主从集群
- 分布式静态资源,比如:静态资源上传cdn
- 分布式计算,比如:使用hadoop进行大数据的分布式计算
- 分布式数据和存储,比如:各分布节点根据哈希算法或其他算法分散存储数据
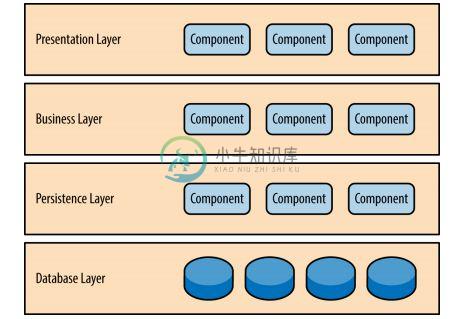
网站分层-图1来自网络
集群
对于用户访问集中的业务独立部署服务器,应用服务器,数据库,nosql数据库。 核心业务基本上需要搭建集群,即多台服务器部署相同的应用构成一个集群,通过负载均衡设备共同对外提供服务, 服务器集群能够为相同的服务提供更多的并发支持,因此当有更多的用户访问时,只需要向集群中加入新的机器即可, 另外可以实现当其中的某台服务器发生故障时,可以通过负载均衡的失效转移机制将请求转移至集群中其他的服务器上,因此可以提高系统的可用性
- 应用服务器集群
- nginx 反向代理
- slb
- ... ...
- (关系/nosql)数据库集群
- 主从分离,从库集群
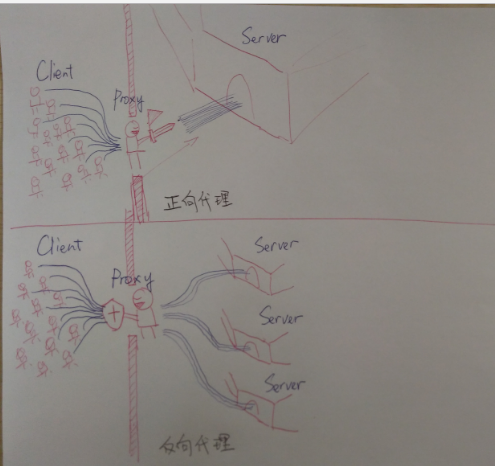
通过反向代理均衡负载-图2来自网络
异步
在高并发业务中如果涉及到数据库操作,主要压力都是在数据库服务器上面,虽然使用主从分离,但是数据库操作都是在主库上操作,单台数据库服务器连接池允许的最大连接数量是有限的
当连接数量达到最大值的时候,其他需要连接数据操作的请求就需要等待有空闲的连接,这样高并发的时候很多请求就会出现connection time out 的情况
那么像这种高并发业务我们要如何设计开发方案可以降低数据库服务器的压力呢?
如:
- 自动弹窗签到,双11跨0点的时候并发请求签到接口
- 双11抢红包活动
- 双11订单入库
- 等
设计考虑:
- 逆向思维,压力在数据库,那业务接口就不进行数据库操作不就没压力了
- 数据持久化是否允许延迟?
- 如何让业务接口不直接操作DB,又可以让数据持久化?
方案设计:
- 像这种涉及数据库操作的高并发的业务,就要考虑使用异步了
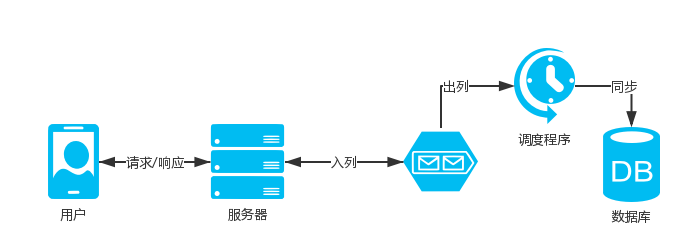
- 客户端发起接口请求,服务端快速响应,客户端展示结果给用户,数据库操作通过异步同步
- 如何实现异步同步?
- 使用消息队列,将入库的内容enqueue到消息队列中,业务接口快速响应给用户结果(可以温馨提示高峰期延迟到账)
- 然后再写个独立程序从消息队列dequeue数据出来进行入库操作,入库成功后刷新用户相关缓存,如果入库失败记录日志,方便反馈查询和重新持久化
- 这样一来数据库操作就只有一个程序(多线程)来完成,不会给数据带来压力
补充:
- 消息队列除了可以用在高并发业务,其他只要有相同需求的业务也是可以使用,如:短信发送中间件等
- 高并发下异步持久化数据可能会影响用户的体验,可以通过可配置的方式,或者自动化监控资源消耗来切换时时或者使用异步,这样在正常流量的情况下可以使用时时操作数据库来提高用户体验
- 异步同时也可以指编程上的异步函数,异步线程,在有的时候可以使用异步操作,把不需要等待结果的操作放到异步中,然后继续后面的操作,节省了等待的这部分操作的时间
缓存
高并发业务接口多数都是进行业务数据的查询,如:商品列表,商品信息,用户信息,红包信息等,这些数据都是不会经常变化,并且持久化在数据库中
高并发的情况下直接连接从库做查询操作,多台从库服务器也抗不住这么大量的连接请求数(前面说过,单台数据库服务器允许的最大连接数量是有限的)
那么我们在这种高并发的业务接口要如何设计呢?
设计考虑:
- 还是逆向思维,压力在数据库,那么我们就不进行数据库查询
- 数据不经常变化,我们为啥要一直查询DB?
- 数据不变化客户端为啥要向服务器请求返回一样的数据?
方案设计:
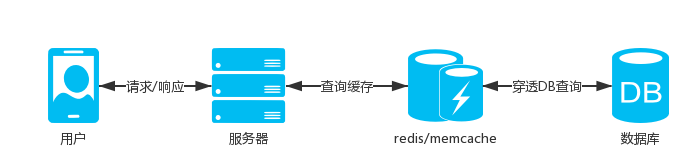
- 数据不经常变化,我们可以把数据进行缓存,缓存的方式有很多种,一般的:应用服务器直接Cache内存,主流的:存储在memcache、redis内存数据库
- Cache是直接存储在应用服务器中,读取速度快,内存数据库服务器允许连接数可以支撑到很大,而且数据存储在内存,读取速度快,再加上主从集群,可以支撑很大的并发查询
- 根据业务情景,使用配合客户端本地存,如果我们数据内容不经常变化,为啥要一直请求服务器获取相同数据,可以通过匹配数据版本号,如果版本号不一样接口重新查询缓存返回数据和版本号,如果一样则不查询数据直接响应
- 这样不仅可以提高接口响应速度,也可以节约服务器带宽,虽然有些服务器带宽是按流量计费,但是也不是绝对无限的,在高并发的时候服务器带宽也可能导致请求响应慢的问题
补充:
面向服务
SOA面向服务架构设计微服务更细粒度服务化,一系列的独立的服务共同组成系统
使用服务化思维,将核心业务或者通用的业务功能抽离成服务独立部署,对外提供接口的方式提供功能。
最理想化的设计是可以把一个复杂的系统抽离成多个服务,共同组成系统的业务,优点:松耦合,高可用性,高伸缩性,易维护。
通过面向服务化设计,独立服务器部署,均衡负载,数据库集群,可以让服务支撑更高的并发
- 服务例子:
- 用户行为跟踪记录统计
- 说明:
- 通过上报应用模块,操作事件,事件对象,等数据,记录用户的操作行为
- 比如:记录用户在某个商品模块,点击了某一件商品,或者浏览了某一件商品
- 背景:
- 由于服务需要记录用户的各种操作行为,并且可以重复上报,准备接入服务的业务又是核心业务的用户行为跟踪,所以请求量很大,高峰期会产生大量并发请求。
- 架构:
- nodejs WEB应用服务器均衡负载
- redis主从集群
- mysql主
- nodejs+express+ejs+redis+mysql
- 服务端采用nodejs,nodejs是单进程(PM2根据cpu核数开启多个工作进程),采用事件驱动机制,适合I/O密集型业务,处理高并发能力强
- 业务设计:
- 并发量大,所以不能直接入库,采用:异步同步数据,消息队列
- 请求接口上报数据,接口将上报数据push到redis的list队列中
- nodejs写入库脚本,循环pop redis list数据,将数据存储入库,并进行相关统计Update,无数据时sleep几秒
- 因为数据量会比较大,上报的数据表按天命名存储
- 接口:
- 上报数据接口
- 统计查询接口
- 上线跟进:
- 服务业务基本正常
- 每天的上报表有上千万的数据
冗余,自动化
当高并发业务所在的服务器出现宕机的时候,需要有备用服务器进行快速的替代,在应用服务器压力大的时候可以快速添加机器到集群中,所以我们就需要有备用机器可以随时待命。 最理想的方式是可以通过自动化监控服务器资源消耗来进行报警,自动切换降级方案,自动的进行服务器替换和添加操作等,通过自动化可以减少人工的操作的成本,而且可以快速操作,避免人为操作上面的失误。
- 冗余
- 数据库备份
- 备用服务器
- 自动化
- 自动化监控
- 自动化报警
- 自动化降级
通过GitLab事件,我们应该反思,做了备份数据并不代表就万无一失了,我们需要保证高可用性,首先备份是否正常进行,备份数据是否可用,需要我们进行定期的检查,或者自动化监控, 还有包括如何避免人为上的操作失误问题。(不过事件中gitlab的开放性姿态,积极的处理方式还是值得学习的)
总结
高并发架构是一个不断衍变的过程,冰洞三尺非一日之寒,长城筑成非一日之功
打好基础架构方便以后的拓展,这点很重要
这里重新整理了下高并发下的架构思路,举例了几个实践的例子,如果对表述内容有啥意见或者建议欢迎在博客中留言