
3.4. Notepad++的正则表达式替换和替换
下面就来详细介绍Notepad++中关于正则表达式的部分,主要是查找和替换。
对于替换功能,一般的文本编辑器,都具有此功能,但是对于高级的正则表达式替换,则很多都不支持。而此处Notepad++支持此功能。
正则表达式的替换,在很长一段时间内,我都没有用到过。而后来有此需求的时候,由于不熟悉,导致也没去折腾具体如何使用的。
后来有空去弄了下,终于搞懂了。对此类功能不了解的人,会没啥感觉,但是看了下面的介绍,你就会发现这类功能的强大之处。
例 3.3. Notepad++正则表达式替换举例:一次性替换多个文件的后缀
举例说明,此处我有个xml文件,其中原始的内容为:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/right_click_then_property.jpg" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/right_click_then_property.jpg" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/advance_enviroment.jpg" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/advance_enviroment.jpg" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
其中images/env_var/win/xxx.jpg出现的次数,有好几十处。
此处需要把images/env_var/win/xxx.jpg,全部替换为images/env_var/win/xxx.png,即替换文件的后缀。
但是呢,如果手动改的话,改动量很大,效率很低,所以要尽量避免手动改。
另外,此处也不能通过全局的那个替换功能,因为全局替换只适用于固定的文字xxx替换为yyy,而此处文件名都不一样,所以无法实现统一的替换。
此时,才会考虑用Notepad++的正则表达式替换,去实现复杂的,非规则性的替换功能。
而对于正则表达式的替换,最开始,由于不了解其语法,错写成:
查找目标 :
images/env_var/win/\w+\.jpg
替换为(P):
images/env_var/win/\w+\.png
则替换结果是错的,原来的文件名都被替换为w+这两个字符了:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/w+.png" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/w+.png" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/w+.png" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/w+.png" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
后来,参考了[10]
然后得知是用反斜杠,加上数字,实现向后引用(back reference)。
| Notepad++的正则表达式的语法 |
|---|
不过后来也找到了其他更专业和全面的解释:[11]
|
| 注意 |
|---|
之前就知道Notepad++底层是使用SciTE的库的,也顺便找到了SciTE的关于正则表达式的解释[12] 不过其中关于backreference的解释很不清楚。 |
最后写出正确的语法:
查找目标 :
images/env_var/win/(\w+)\.jpg
替换为(P):
images/env_var/win/\1\.png
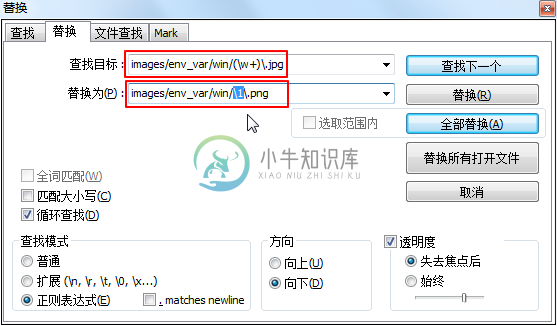 |
可以成功替换为:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/right_click_then_property.png" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/right_click_then_property.png" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/advance_enviroment.png" scalefit="0"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/advance_enviroment.png" align="center" scalefit="1"/></imageobject>
</mediaobject>
</informalfigure>
如此,如果有类似需要,想要实现批量的,非规则性的替换,就可以好好利用Notepad++中的正则表达式去替换了。
例 3.4. Notepad++正则表达式替换举例:一次性替换多个路径
又比如,由于我把很多jpg,png等类型的图片,从images文件夹移动到了images下面的npp文件夹下了,
所以需要把一个文件中所有的:
images/xxx.yyy
其中xxx为文件名(此处文件名全部都是只包含字母和下划线),yyy=jpg或png,都替换为
images/npp/xxx.yyy
此时,就可以写成:
images/(\w+)\.(\w{3})
images/npp/\1\.\2
此处提示我成功替换了58处:
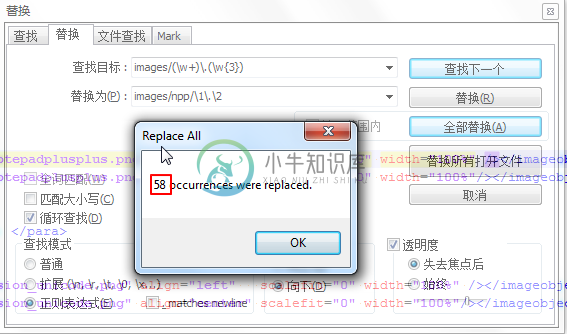 |
相比之下,如果手动去改这58个地方,那真的是累死了不说,还容易由于手误而出错,效率太低。
通过正则表达式去替换,则是高效,又准确。
例 3.5. Notepad++正则表达式替换举例:一次性替换多个listitem为sect4
又比如,在docbook中,想要把原先的listitem部分的内容,都替换为sect4:
 |
并且也注意到,其中除了上层的listitem,其内部还有一些特殊的子listitem:
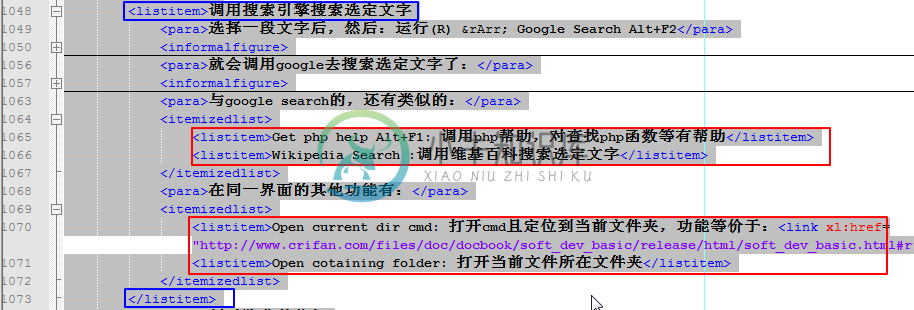 |
需要在替换的时候,考虑到此点,不要将子listitem也替换掉了。
然后就是去想办法,写对应的正则表达式。
此时,注意到每个要替换的listitem的标题部分之后,是有回车和换行的,所以参考第 3.10 节 “Notepad++支持显示回车符,换行符,TAB键,行首,行尾等特殊字符”去"显示所有字符":
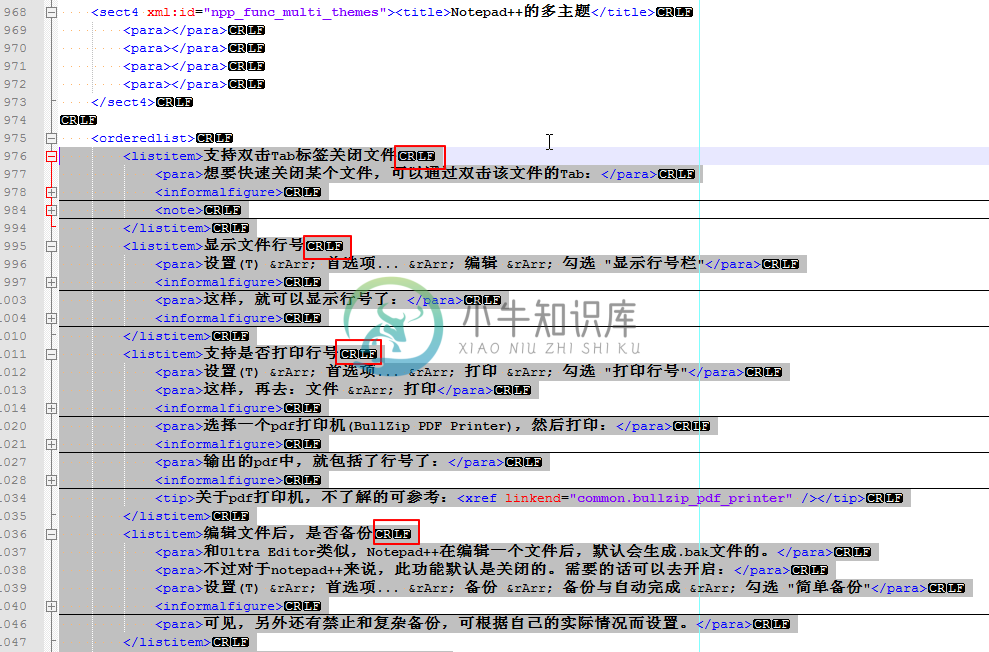 |
这样就清楚,到底包含哪些字符,方便我们接下来去写正则表达式了。
经过折腾,用如下的正则表达式:
<listitem>(.+?)\r\n(.+?)\r\n\s+</listitem>\r\n
<sect4 xml:id="npp_"><title>\1</title>\r\n\2\r\n </sect4>\r\n
将原先内容:
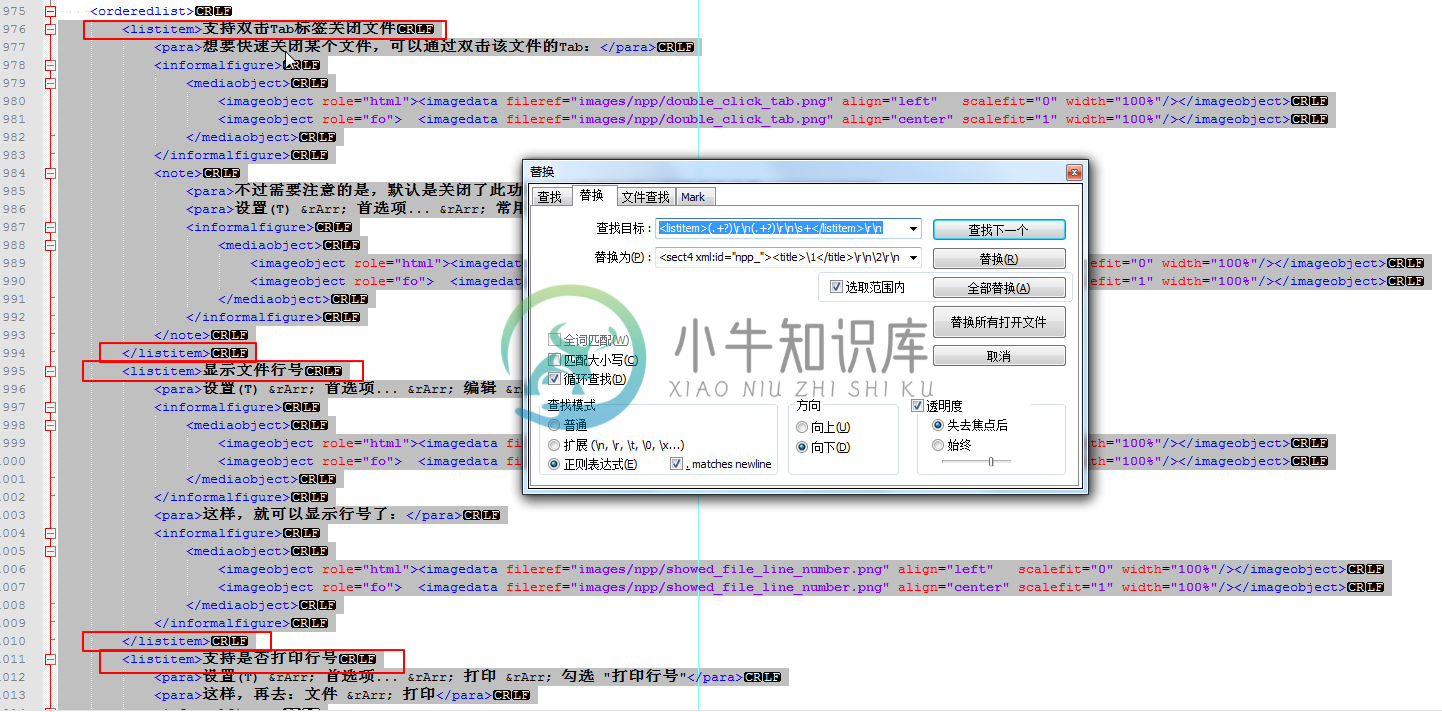 |
替换为:
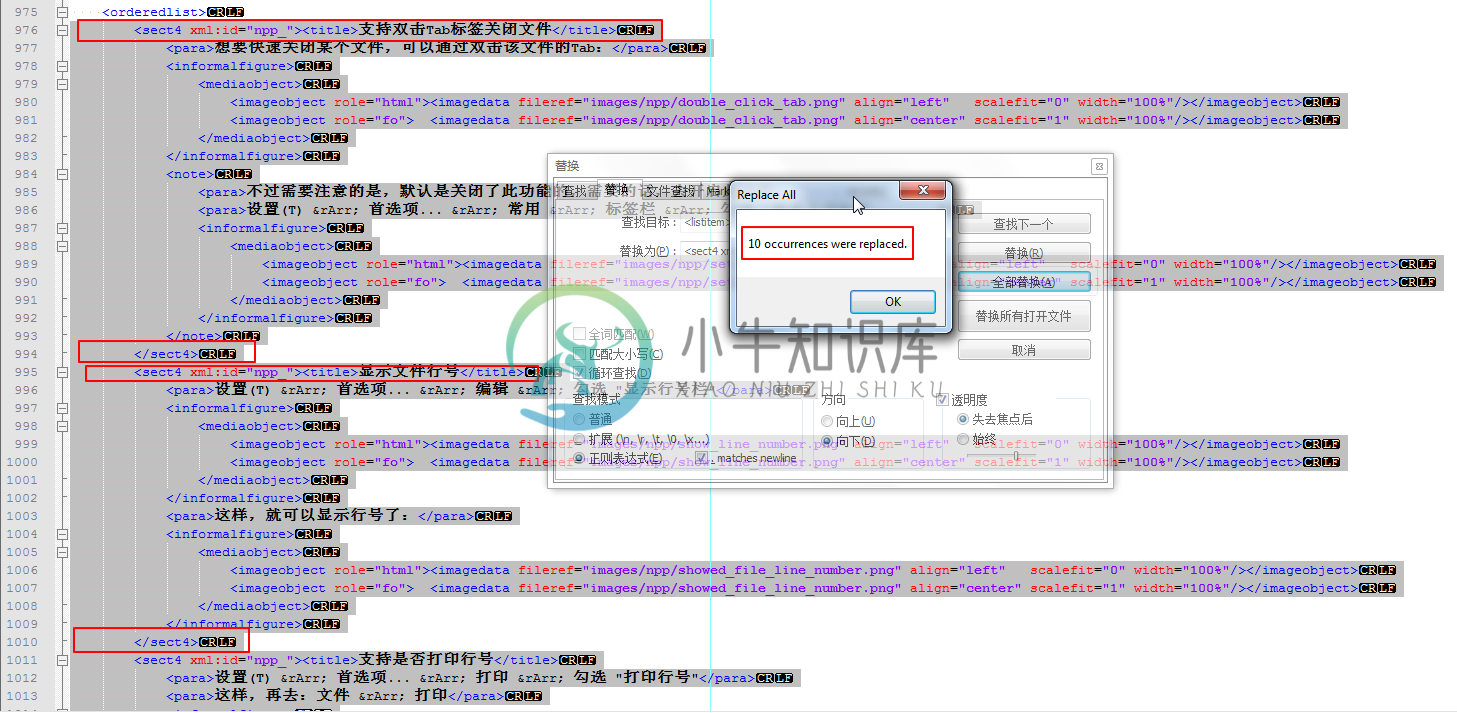 |
可以看到,成功替换了10个。
对应的,也可以看到,对于那些特殊的子listitem来说,也没有被替换掉:
 |
如此,就可以避免了手动的去一点点的修改了。
例 3.6. Notepad++正则表达式替换举例:给每一行都添加AddIcon的前缀
需要把每一行中的文件类型的图片名,替换成加上前缀和后缀。
然后就可以去写正则表达式了:
(\w+)\.png\s+\r\n
AddIcon http://www\.xnip\.com/files/res/apache/icons/20x22/\1\.png \.\1\r\n
就可以从:
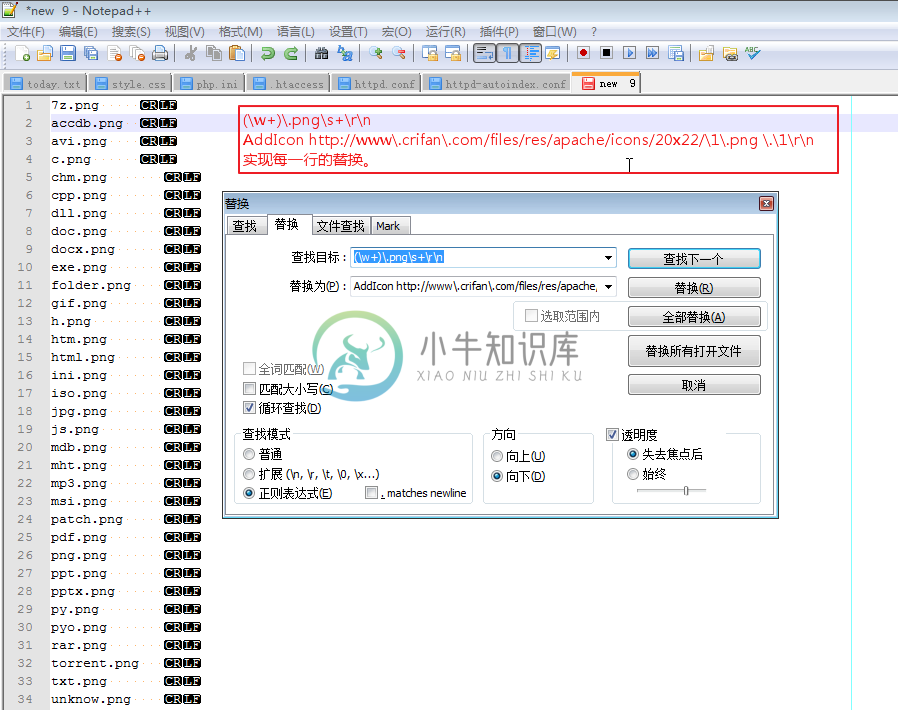 |
替换为:
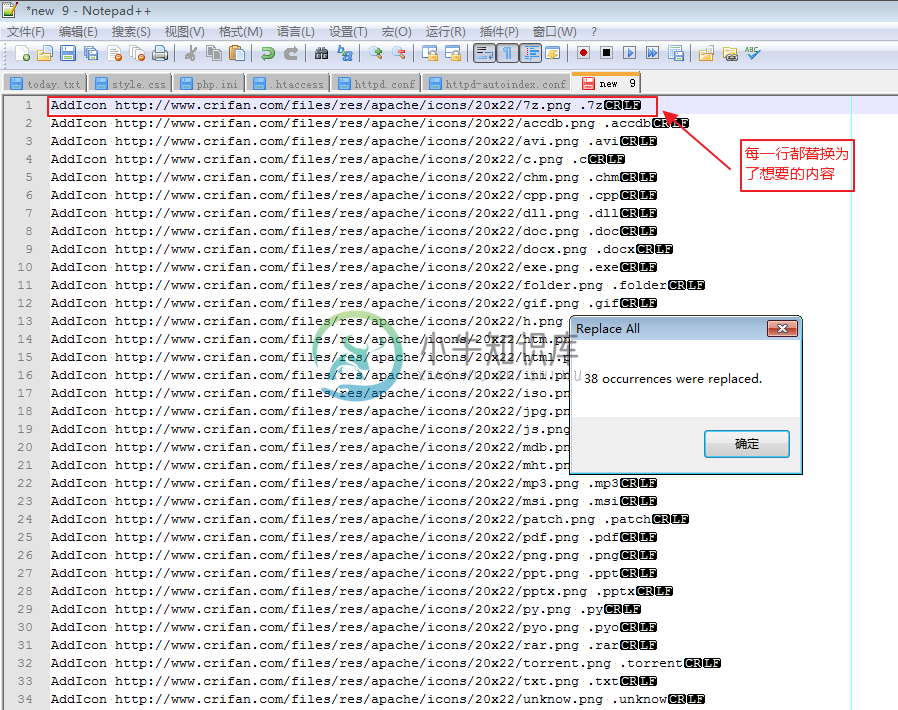 |
所以,如果能利用到此种功能,还是可以很大地提高工作效率的。
例 3.7. Notepad++正则表达式替换举例:给book的标题和地址添加html代码
又比如,对于原先是这样的代码:
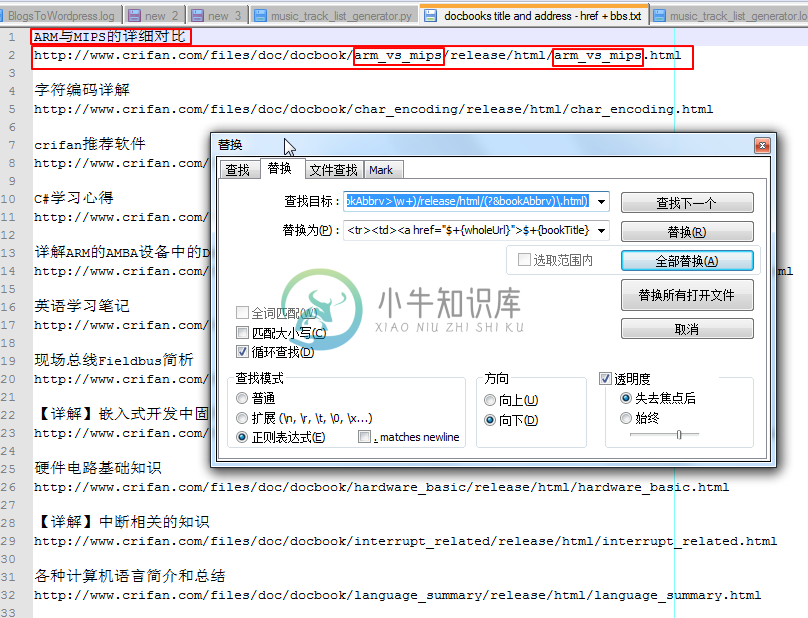 |
即,有很多组,每组分别是标题和地址。
而想要做的事情是,把对应的标题和地址,以及其中缩写,都提取出来,并且添加相关的html代码。
最后经过参考:[11]
而写出了相应的正则表达式:
(?<bookTitle>.+?)\r\n(?<wholeUrl>http://www\.xnip\.com/files/doc/docbook/(?<bookAbbrv>\w+)/release/html/(?&bookAbbrv)\.html)
<tr><td><a href="$+{wholeUrl}">$+{bookTitle}</a></td><td><a href="https://www.xnip.cn/bbs/categories/$+{bookAbbrv}">$+{bookTitle}</td></tr>
然后就可以成功实现28处的替换,替换出来的效果为:
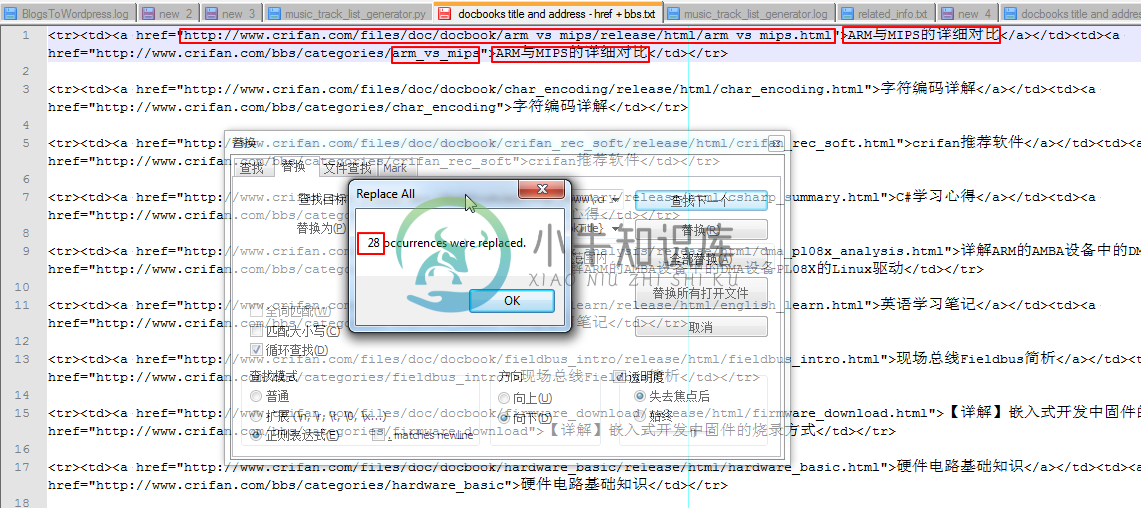 |
替换后的html代码,再添加上相应的html代码:头部的:
<table cellspacing="0" cellpadding="0">
<tbody>
<tr><td><strong>单个Book</strong></td><td><strong>对应的讨论区</strong></td></tr>
和尾部的:
</tbody>
</table>
最终就可以实现需要显示出来的完整的表格信息了:
 |
则又一次地,极大地提高了工作效率。否则要一个个的复制和粘贴,累死了不说,也还容易出错。
例 3.8. Notepad++正则表达式替换举例:查找单个的CR或LF
后来一次,遇到一个需求是:对于单个文件中,查找所谓的不一致的换行符
去看了一下当前文件中,正常都是Windows类型的回车换行,CRLF
想要找到哪里出现了单个的CR或LF
而由于文件有很多行,里面有N个CRLF,而要一眼看出哪里有单个的CR或LF,很困难,或者说不可能,所以只能靠正则表达式去搜索寻找了
然后最终使用正则表达式是:
\r(?!\n)|(?<!\r)\n
然后找到了对应的2处,单个的CR或者LF:
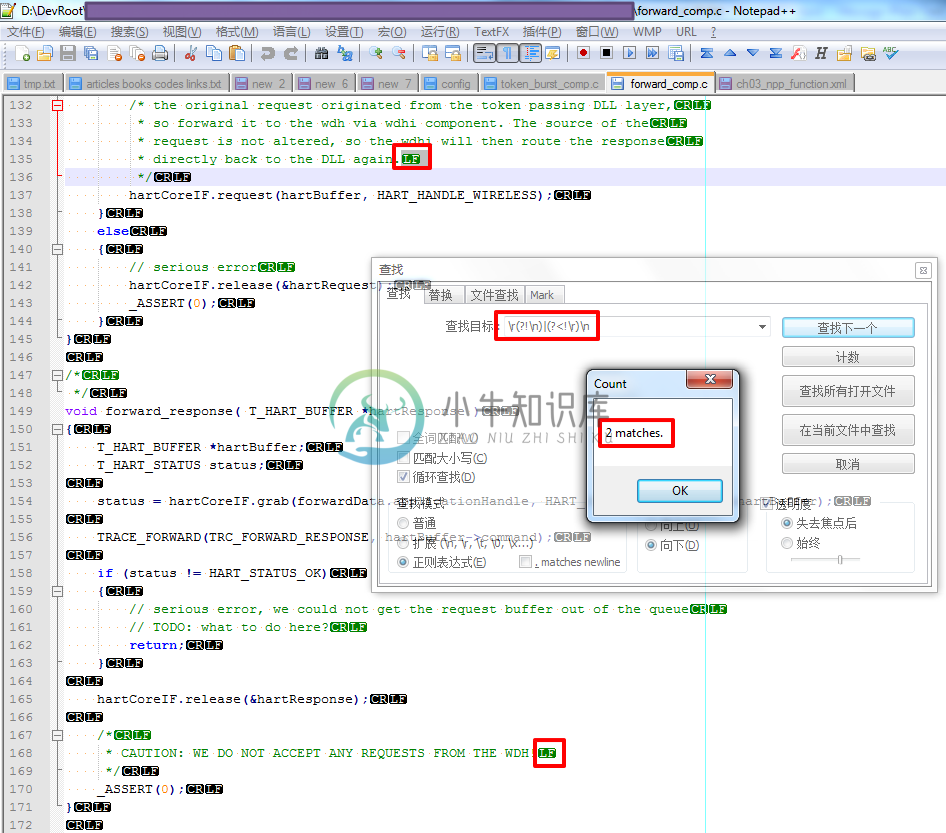 |
此处,顺便简单解释一下此处的正则表达式的含义:
- 具体的语法,还是去参考这个最全的语法:[11]
- 关于CR LF不清楚的,还是先去看:[13]
- 此处的
\r(?!\n)|(?<!\r)\n
是xxx|yyy的格式,表示匹配xxx或yyy - 其中xxx是
\r(?!\n)
,yyy是(?<!\r)\n
- 其中\r和\n,分别表示回车CR,换行LF
- 而
\r(?!\n)
用于匹配一个\r,但是后面不是\n - 而
(?<!\r)\n
用于匹配一个\n,但是前面不是\r
例 3.9. Notepad++正则表达式替换举例:去除href链接
遇到一个问题是,想要把一个表格中的内容,粘贴到WLW中,结果由于其中N个内容,都包含了对应的链接,想要把链接去掉。
所以就去切换到源码模式,然后把html代码拷贝出来,然后用Notepad++去替换
所用正则是:
<p><a href="http://.+?/gpu\.php.+?">(<b>.+?</b>)</a></p>
<p>\1</p>
替换前是:
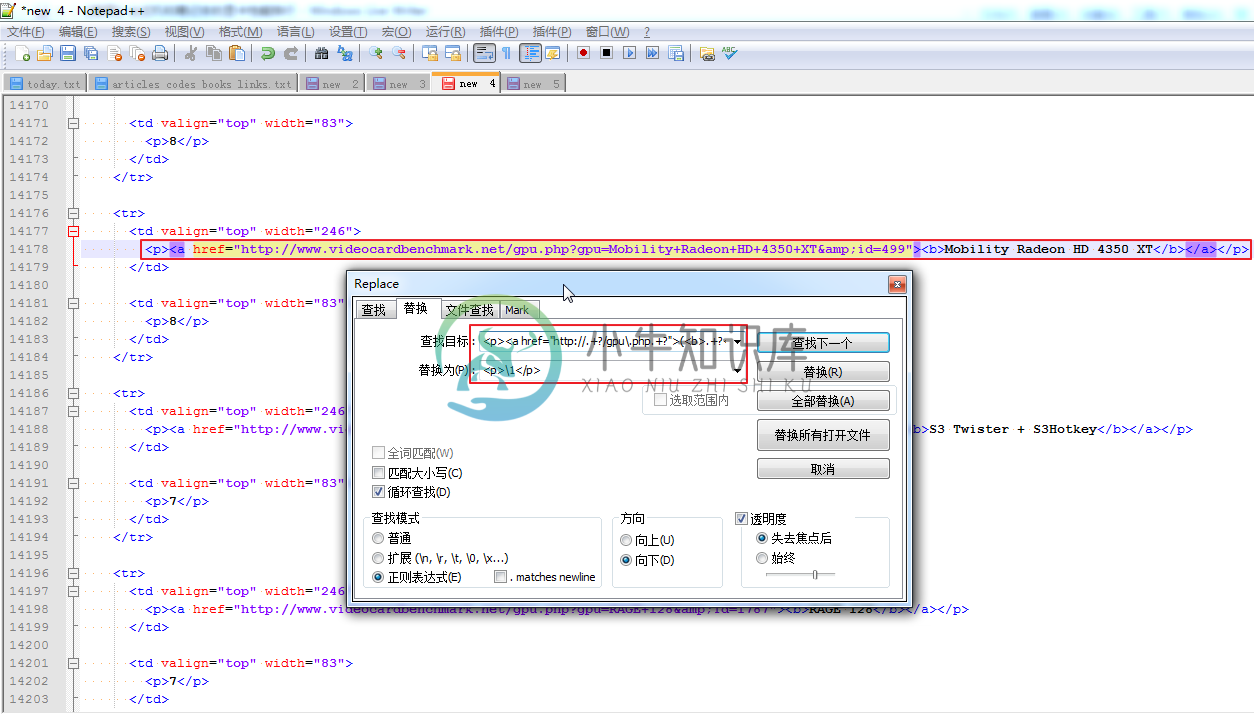 |
替换后,变成这样的:
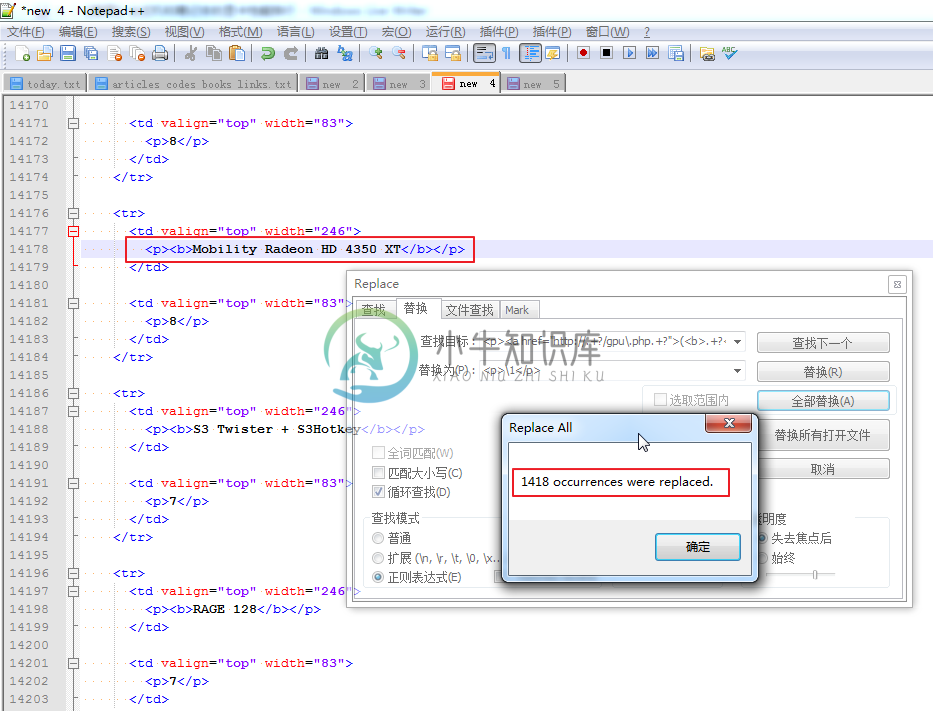 |
效率不是一般的高。
例 3.10. Notepad++正则表达式替换举例:把标题和地址转换为link格式
遇到一个问题是,想要把对应的,帖子的标题和地址,变成docbook中的link格式,一般拷贝到Docbook的xml中直接使用,就省的自己一点点复制粘贴和修改了。
所用Notepad++的正则替换的如下:
([\S ]+)\s+(http://www\.xnip\.com/\w+)
<para><link xl:href="\2">\1</link></para>
替换前是:
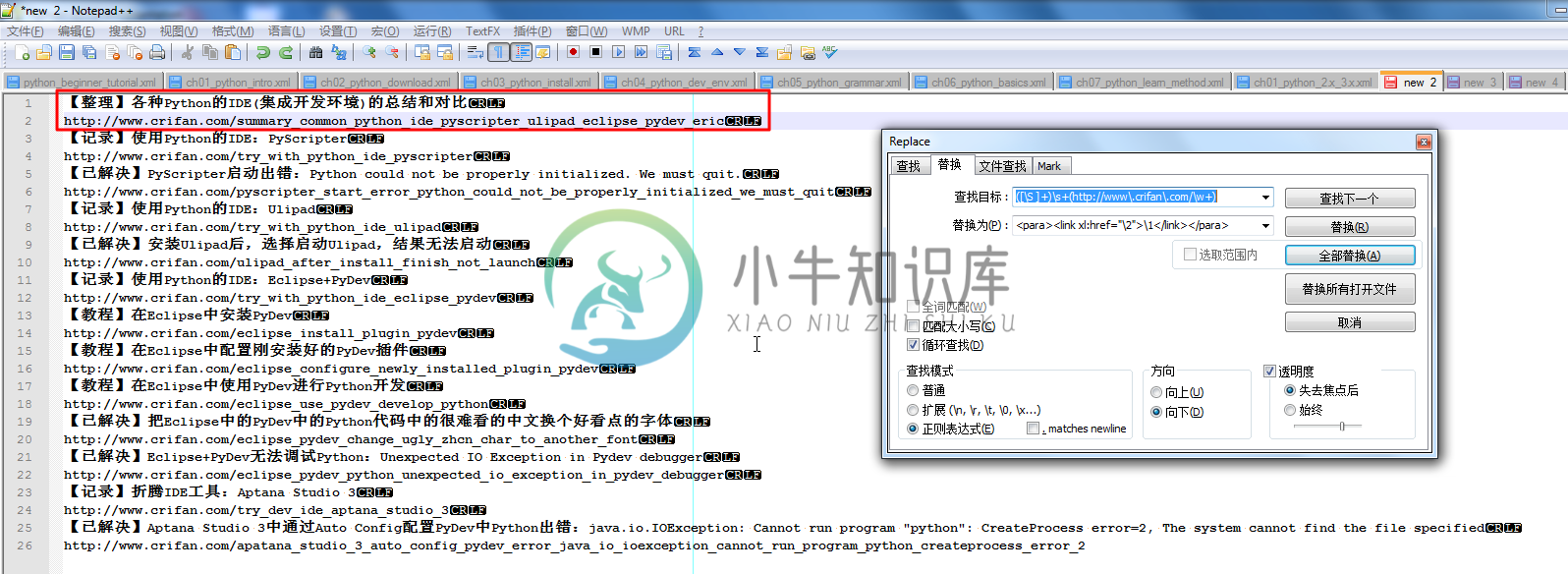 |
替换后,变成这样的:
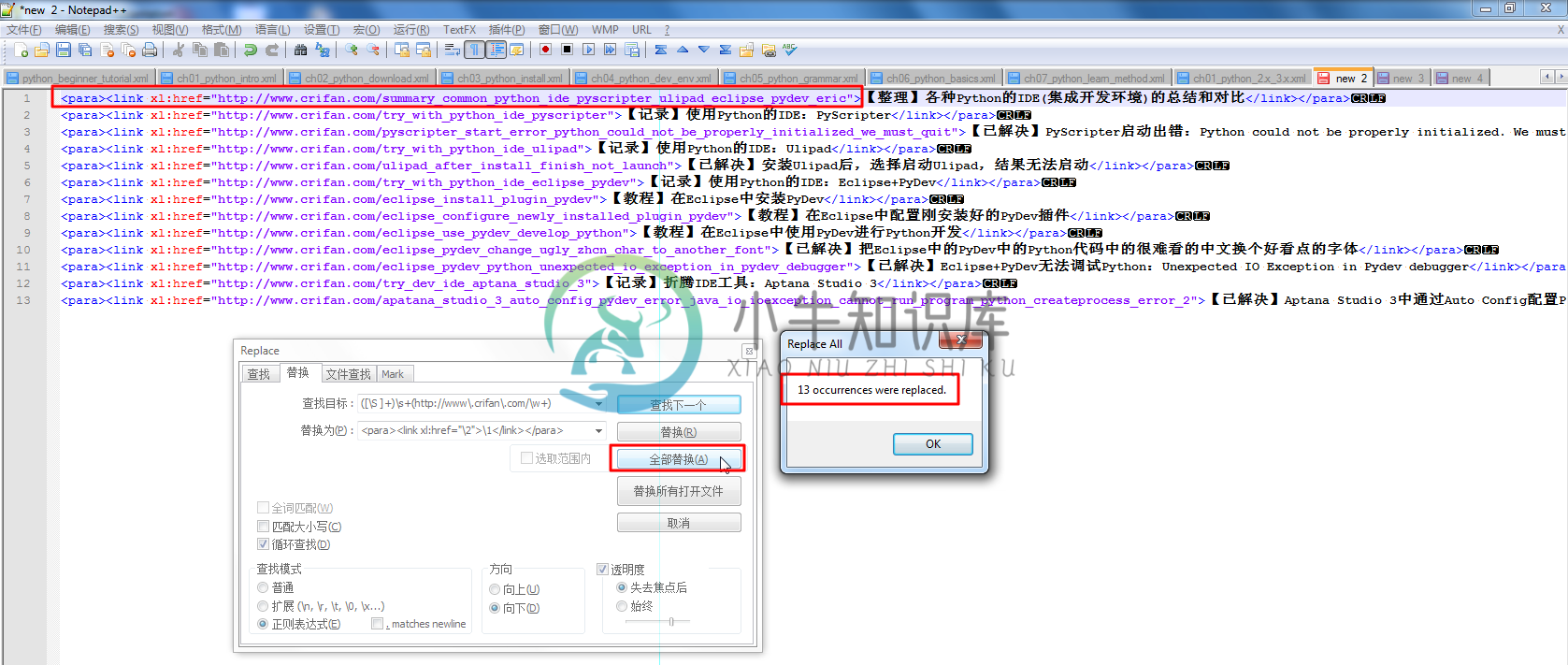 |
例 3.11. Notepad++正则表达式替换举例:给关键字添加双引号,把逗号变成竖杠
想要把:
XXX,
变为:
'XXX'|
所用Notepad++的正则替换表达式是:
([A-Z\_]+),?\s*
'\1'|
替换前:
 |
替换后:
 |
例 3.12. Notepad++正则表达式替换举例:wlw中图片分行
背景是,wlw编辑帖子,一次性导入70多个多个图片后,如果直接发布,则会导致图片之间没有换行,会横向接着排列,不好看。
想要在每两个图片之间,加上回车换行,即,对应的,对于html来说,是从:
<a href="$astronomy_dispel_trouble_20[2].jpg"><img title="astronomy_dispel_trouble_20" alt="astronomy_dispel_trouble_20" src="$astronomy_dispel_trouble_20_thumb.jpg" width="960" height="720" /></a>
变成:
<p><a href="$astronomy_dispel_trouble_20[2].jpg"><img title="astronomy_dispel_trouble_20" alt="astronomy_dispel_trouble_20" src="$astronomy_dispel_trouble_20_thumb.jpg" width="960" height="720" /></a></p>
而此转换,如果用手工去做,就只能在wlw中,手动输入回车换行,则至少需要按50多次的左右键加上回车,很是繁琐。
所以,就可以在wlw中,切换到源码,然后将html拷贝出来粘贴到notepad++中,利用notepad++中的正则,实现对应的替换。
对应的用的Notepad++的正则如下:
(<a[^<>]+?><img[^<>]+?/></a>)
<p>\1</p>\r\n
从:
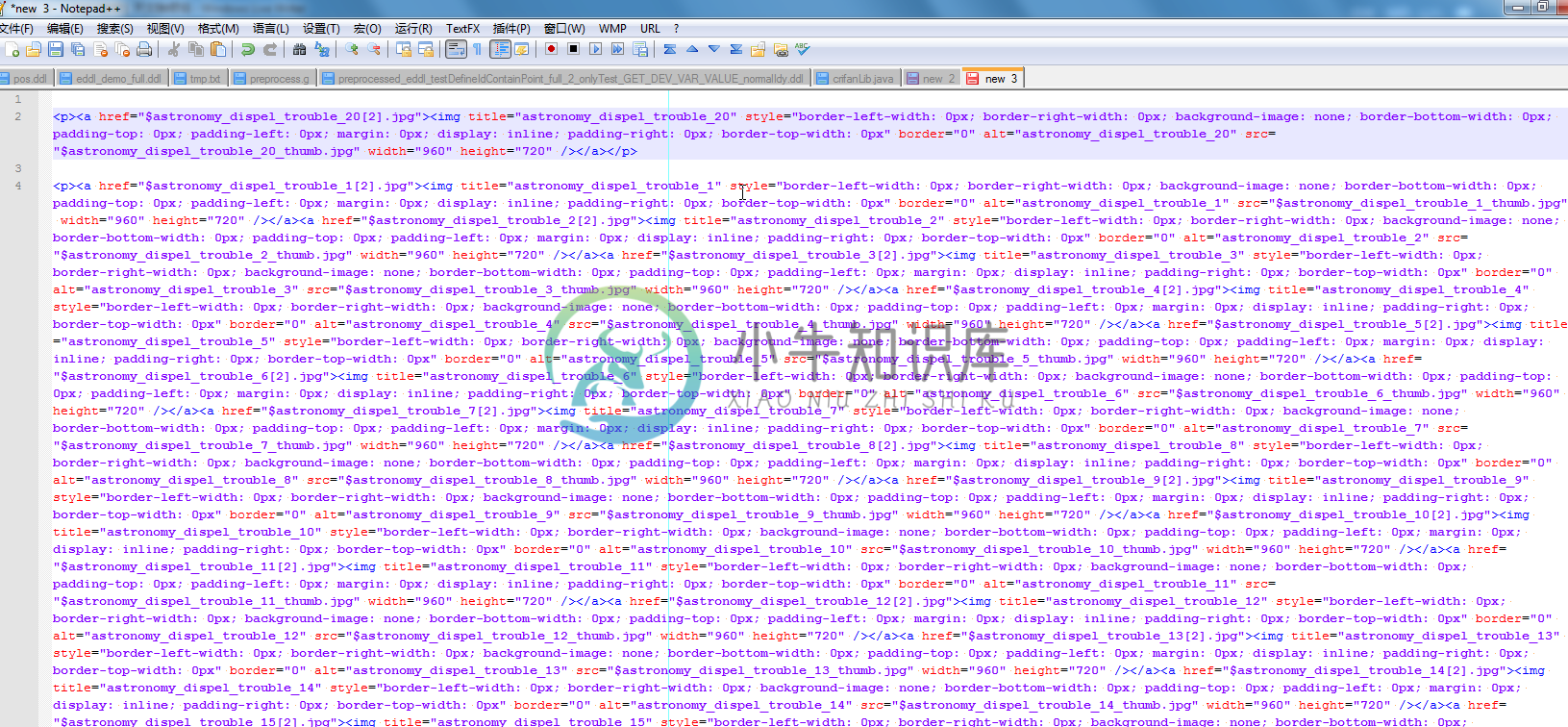 |
替换为:
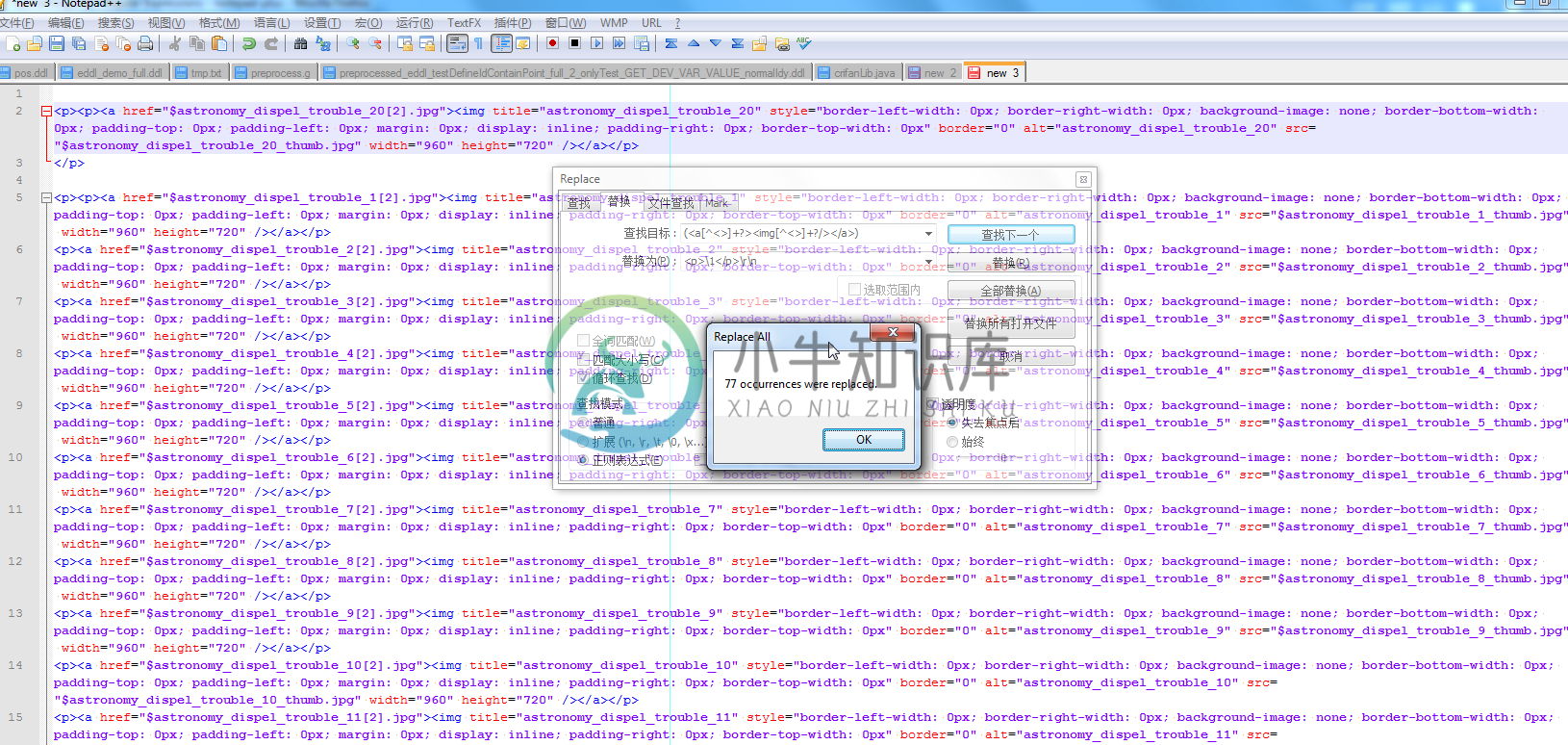 |
如此,高效的解决了问题。
例 3.13. Notepad++正则表达式替换举例:给sect2添加xml:id和title
背景是,为crosstool_ng写docbook的xml,然后想要对于之前的itemizedlist,改为sect2,已经手动替换itemizedlist为sect2了。
剩下的,还需要给sect2添加对应的xml:id和title,所以,就去Notepad++中写替换的正则
<sect2>(.+)$
<sect2 xml:id=""><title>\1</title>
将:
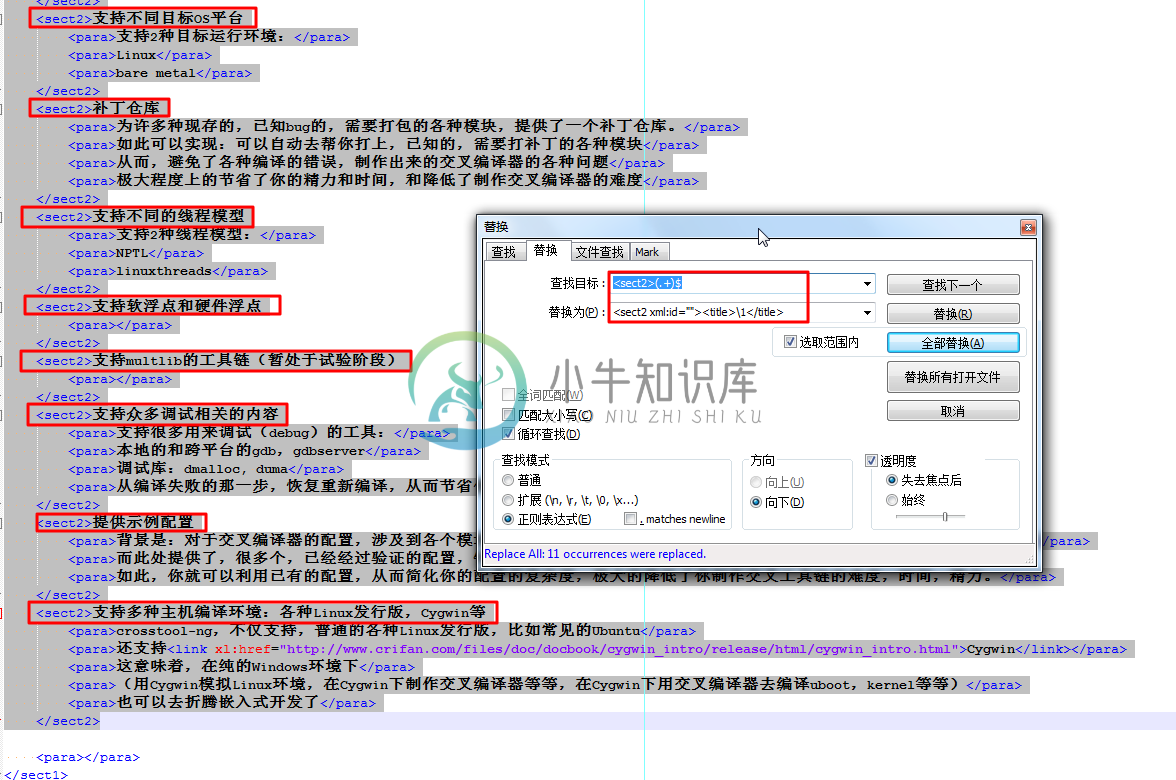 |
替换为:
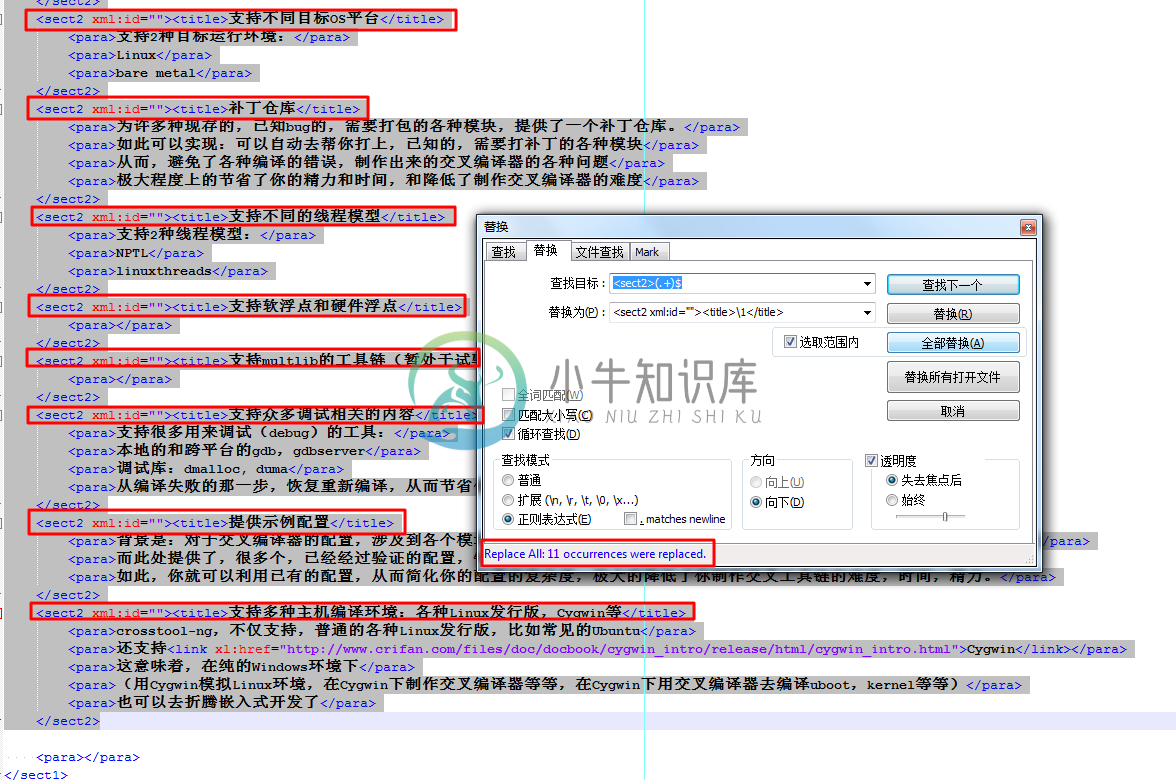 |
如此,省去了几十次的,手动输入xml:id和title,以及复制和粘贴的繁琐工作。
简直就是一秒变格格的节奏啊,^_^
例 3.14. Notepad++正则表达式替换举例:保持sect2和title添加xml:id
在写Python教程的book的xml时,需要编辑对应的xml,涉及到处理sect2:
用正则:
<sect1><title>([^:]+:\s*)([a-zA-Z]+)</title>
<sect1 xml:id="\2"><title>\1\2</title>
将:
 |
替换为:
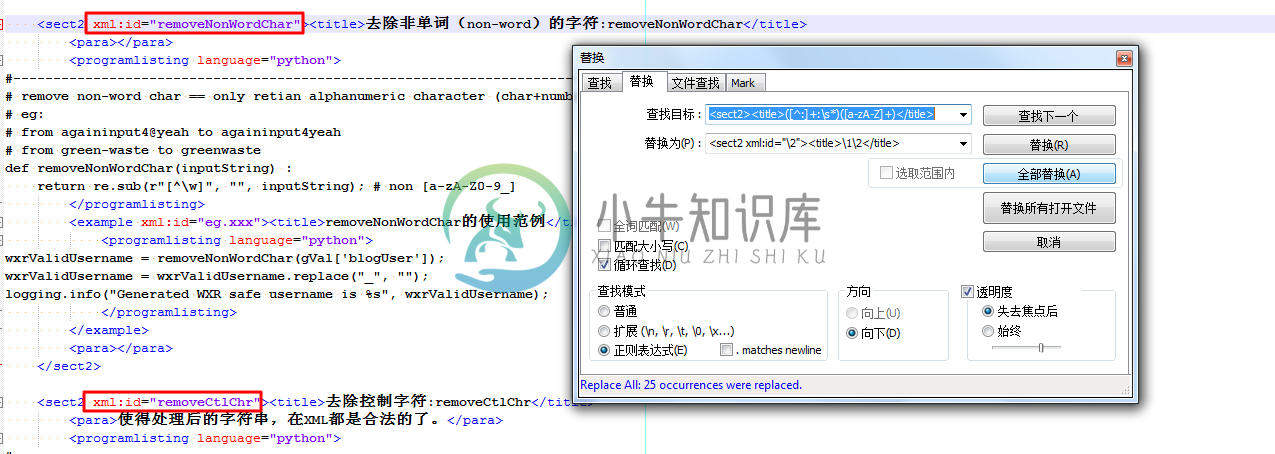 |
又省去很多复杂的手动的复制粘贴的体力活了。
例 3.15. Notepad++正则表达式替换举例:去除单引号变成antlr的token
在折腾antlr的grammar时,将原先rule中有的literal都处理为token,所以去把部分单引号,都去掉,变成对应的token:
用正则:
'(\w+)'
\1
将:
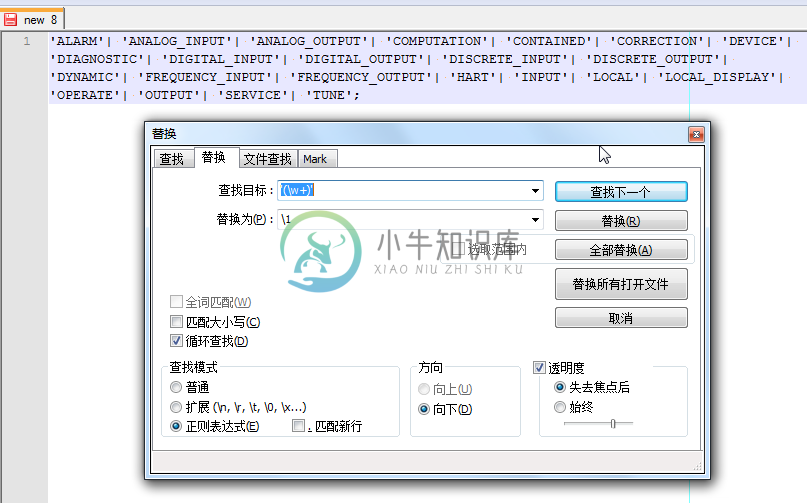 |
替换为:
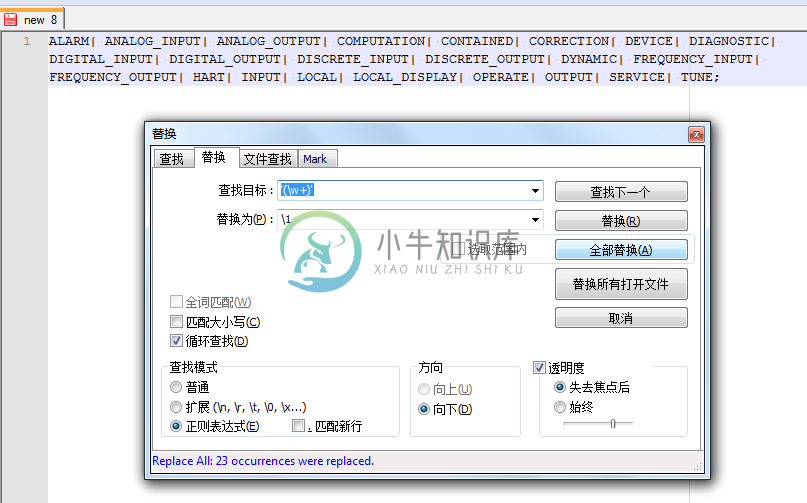 |
不用自己手动的去除对应的单引号了。
例 3.16. Notepad++正则表达式替换举例:将单引号加ID变成antlr的token的定义
在折腾antlr的grammar时,将原先单引号加上id的写法,直接变成对应的token的定义,并且加上对应的换行:
用正则:
'(\w+)'\s*\|?\s*
\1\t:\t'\1';\r\n
将:
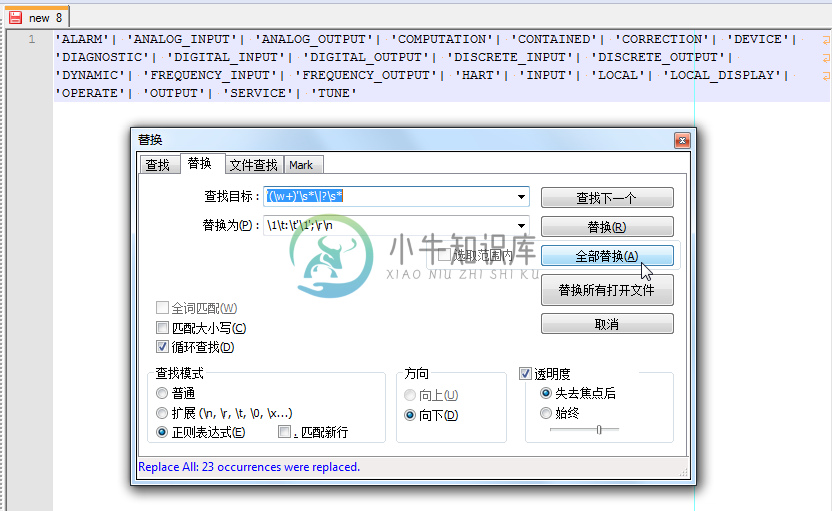 |
替换为:
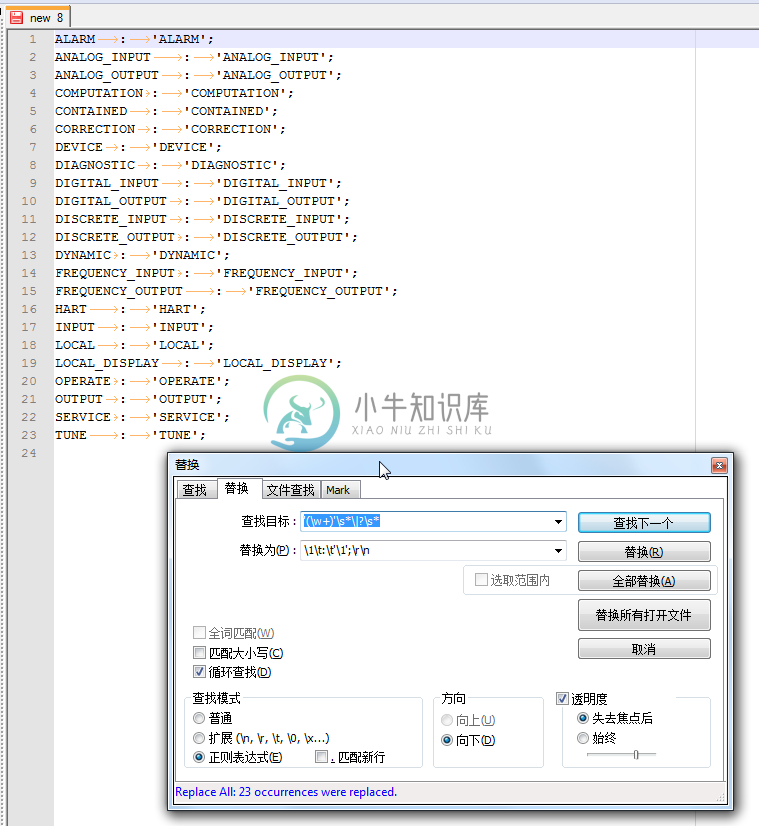 |
很明显,还是很帅的,一次性搞定去除引号,加上对应的token的定义,再加上对应的回车换行。
正则,就是高效率啊。
例 3.17. Notepad++正则表达式替换举例:dd宏定义中去除多国语言字符串
在折腾HART的EDDL文件时,将宏定义中多国语言字符串去除掉:
用正则:
("[^"]+")\s*"\|\w{2}\|""[^"]+"\1
将:
 |
替换为:
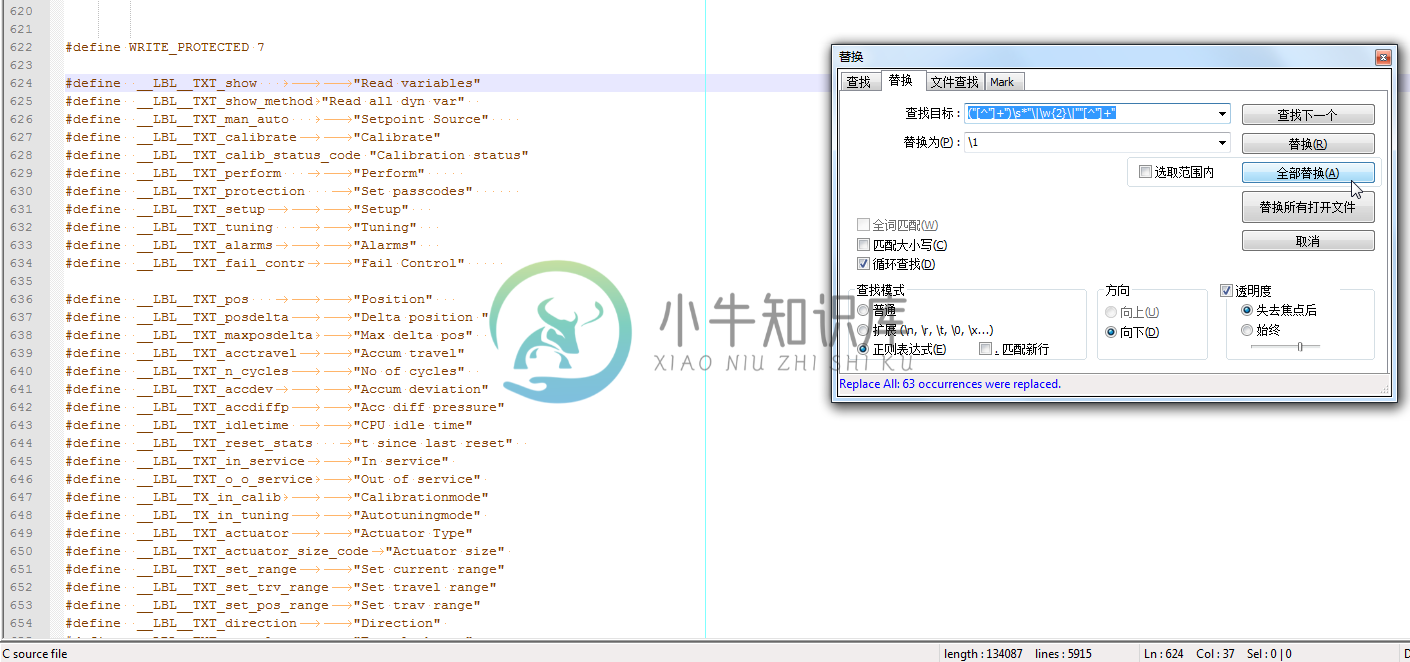 |
如此,省去了,一点点选择和删除对应的内容了。
例 3.18. Notepad++正则表达式替换举例:C宏定义转java变量定义
在折腾
【记录】给usb-serial-for-android中的Silicon Labs的CP2102中添加RTS和DTR的支持
时,将C语言中的宏定义,转换为对应的Java中的变量定义:
用正则:
#define\s+(\w+)\s+(0x\d+)
private static final int \1 = \2;
将:
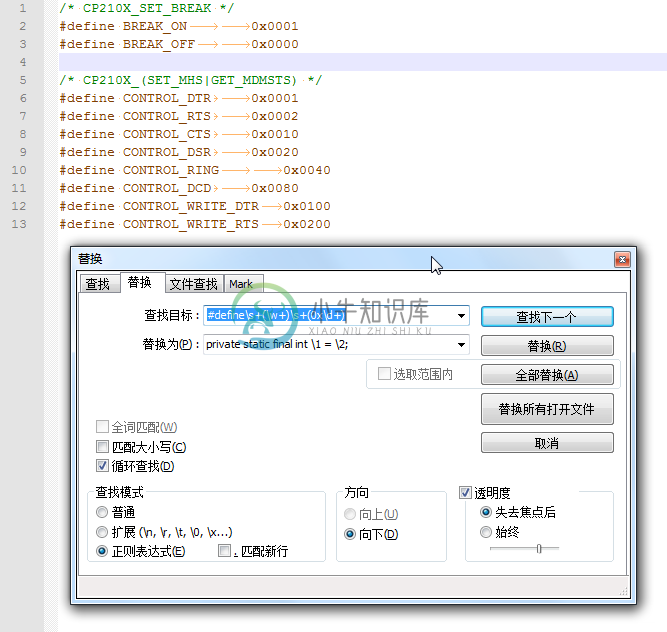 |
替换为:
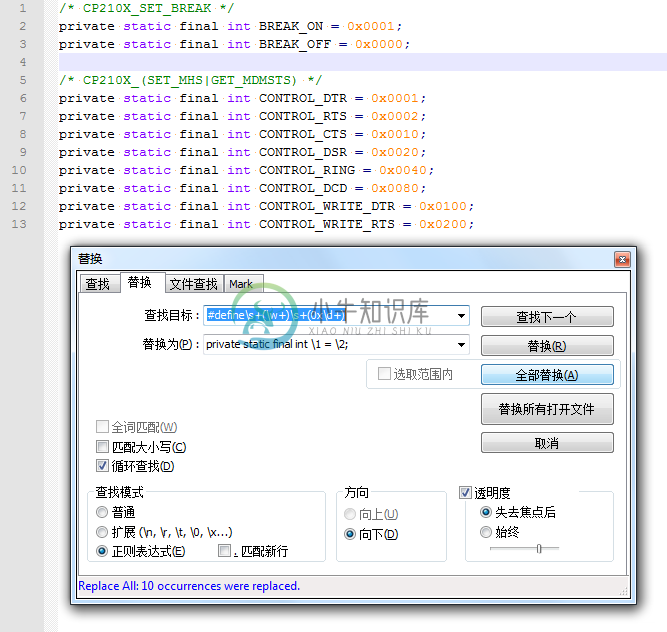 |
很是方便好用,不用自己一点点改代码了。
例 3.19. Notepad++正则表达式替换举例:docbook的link变bibliomixed
在写
ANTLR教程
时,将别的某个docbook的xml中已有的帖子链接,都是link形式的,去转换为bibliomixed的形式。
本来都是手动一点点复制粘贴,然后再修改ref的xml:id的值的,很是麻烦,现在去用正则,一次性处理:
.+(<link\s+xl:href="http://.+?/([\w_]+)/?">[^<>]+?</link>).+
<bibliomixed xml:id="ref.\2">\r\n <bibliosource>\1</bibliosource>\r\n <author>xnip Li</author>\r\n</bibliomixed>
将:
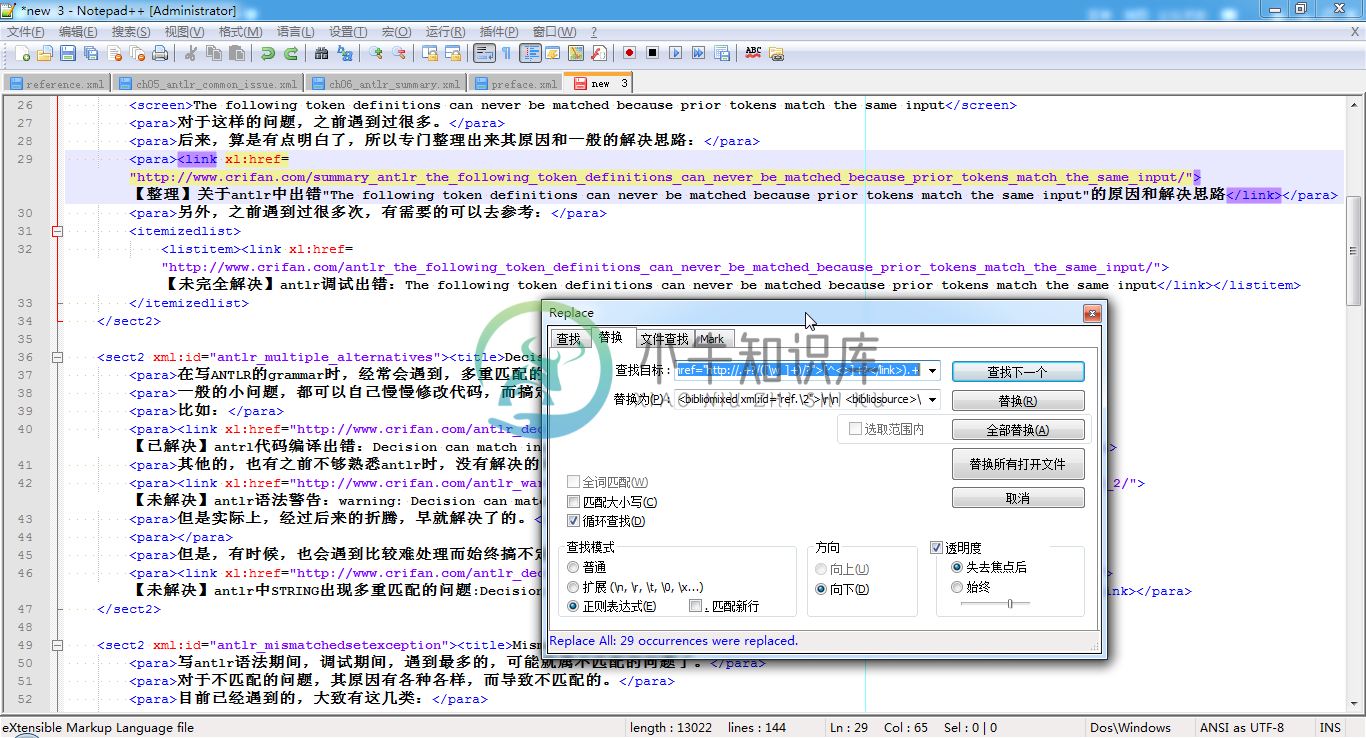 |
替换为:
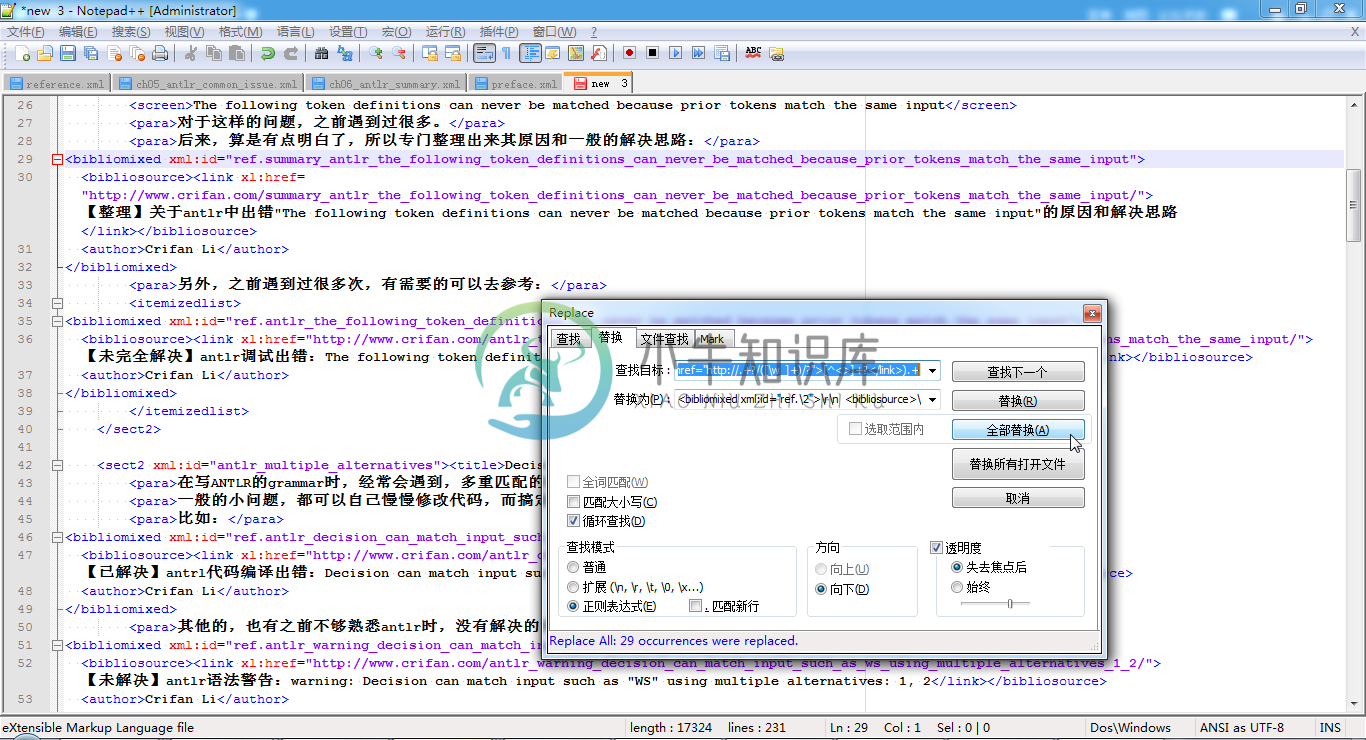 |
就可以免去手动的麻烦了。
对应的,就是把之前的link内容:
<para><link xl:href="https://www.xnip.cn/summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input/">【整理】关于antlr中出错"The following token definitions can never be matched because prior tokens match the same input"的原因和解决思路</link></para>
就变成了:
<bibliomixed xml:id="ref.summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input">
<bibliosource><link xl:href="https://www.xnip.cn/summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input/">【整理】关于antlr中出错"The following token definitions can never be matched because prior tokens match the same input"的原因和解决思路</link></bibliosource>
<author>xnip Li</author>
</bibliomixed>
之后,就可以直接拷贝bibliomixed的内容,到对应的docbook的book中的reference.xml中的bibliography中去了。