
七 生成器
- Milo Yip
- 2016/12/20
本文是《从零开始的 JSON 库教程》的第七个单元。代码位于 json-tutorial/tutorial07。
1. JSON 生成器
我们在前 6 个单元实现了一个合乎标准的 JSON 解析器,它把 JSON 文本解析成一个树形数据结构,整个结构以 lept_value 的节点组成。
JSON 生成器(generator)负责相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
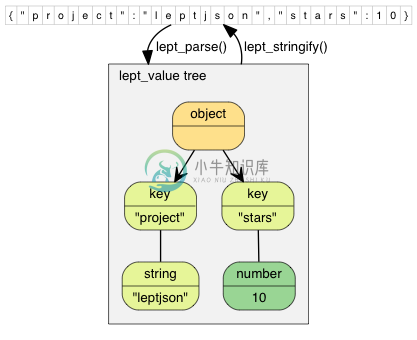
相对于解析器,通常生成器更容易实现,而且生成器几乎不会造成运行时错误。因此,生成器的 API 设计为以下形式,直接返回 JSON 的字符串:
char* lept_stringify(const lept_value* v, size_t* length);
length 参数是可选的,它会存储 JSON 的长度,传入 NULL 可忽略此参数。使用方需负责用 free() 释放内存。
为了简单起见,我们不做换行、缩进等美化(prettify)处理,因此它生成的 JSON 会是单行、无空白字符的最紧凑形式。
2. 再利用 lept_context 做动态数组
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
#ifndef LEPT_PARSE_STRINGIFY_INIT_SIZE#define LEPT_PARSE_STRINGIFY_INIT_SIZE 256#endifint lept_stringify(const lept_value* v, char** json, size_t* length) {lept_context c;int ret;assert(v != NULL);assert(json != NULL);c.stack = (char*)malloc(c.size = LEPT_PARSE_STRINGIFY_INIT_SIZE);c.top = 0;if ((ret = lept_stringify_value(&c, v)) != LEPT_STRINGIFY_OK) {free(c.stack);*json = NULL;return ret;}if (length)*length = c.top;PUTC(&c, '');*json = c.stack;return LEPT_STRINGIFY_OK;}
生成根节点的值之后,我需还需要加入一个空字符作结尾。
如前所述,此 API 还提供了 length 可选参数,当传入非空指针时,就能获得生成 JSON 的长度。或许读者会疑问,为什么需要获得长度,我们不是可以用 strlen() 获得么?是的,因为 JSON 不会含有空字符(若 JSON 字符串中含空字符,必须转义为 u0000),用 strlen() 是没有问题的。但这样做会带来不必要的性能消耗,理想地是避免调用方有额外消耗。
3. 生成 null、false 和 true
接下来,我们生成最简单的 JSON 类型,就是 3 种 JSON 字面值。为贯彻 TDD,先写测试:
#define TEST_ROUNDTRIP(json)do {lept_value v;char* json2;size_t length;lept_init(&v);EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, json));EXPECT_EQ_INT(LEPT_STRINGIFY_OK, lept_stringify(&v, &json2, &length));EXPECT_EQ_STRING(json, json2, length);lept_free(&v);free(json2);} while(0)static void test_stringify() {TEST_ROUNDTRIP("null");TEST_ROUNDTRIP("false");TEST_ROUNDTRIP("true");/* ... */}
这里我们采用一个最简单的测试方式,把一个 JSON 解析,然后再生成另一 JSON,逐字符比较两个 JSON 是否一模一样。这种测试可称为往返(roundtrip)测试。但需要注意,同一个 JSON 的内容可以有多种不同的表示方式,例如可以插入不定数量的空白字符,数字 1.0 和 1 也是等价的。所以另一种测试方式,是比较两次解析的结果(lept_value 的树)是否相同,此功能将会在下一单元讲解。
然后,我们实现 lept_stringify_value,加入一个 PUTS() 宏去输出字符串:
#define PUTS(c, s, len) memcpy(lept_context_push(c, len), s, len)static int lept_stringify_value(lept_context* c, const lept_value* v) {size_t i;int ret;switch (v->type) {case LEPT_NULL: PUTS(c, "null", 4); break;case LEPT_FALSE: PUTS(c, "false", 5); break;case LEPT_TRUE: PUTS(c, "true", 4); break;/* ... */}return LEPT_STRINGIFY_OK;}
4. 生成数字
为了简单起见,我们使用 sprintf("%.17g", ...) 来把浮点数转换成文本。"%.17g" 是足够把双精度浮点转换成可还原的文本。
最简单的实现方式可能是这样的:
case LEPT_NUMBER:{char buffer[32];int length = sprintf(buffer, "%.17g", v->u.n);PUTS(c, buffer, length);}break;
但这样需要在 PUTS() 中做一次 memcpy(),实际上我们可以避免这次复制,只需要生成的时候直接写进 c 里的推栈,然后再按实际长度调查 c->top:
case LEPT_NUMBER:{char* buffer = lept_context_push(c, 32);int length = sprintf(buffer, "%.17g", v->u.n);c->top -= 32 - length;}break;
因每个临时变量只用了一次,我们可以把代码压缩成一行:
case LEPT_NUMBER:c->top -= 32 - sprintf(lept_context_push(c, 32), "%.17g", v->u.n);break;
5. 总结与练习
我们在此单元中简介了 JSON 的生成功能和 leptjson 中的实现方式。
leptjson 重复利用了 lept_context 中的数据结构作为输出缓冲,可以节省代码量。
生成通常比解析简单(一个例外是 RapidJSON 自行实现了浮点数至字符串的算法),余下的 3 种 JSON 类型就当作练习吧:
由于有两个地方需要生成字符串(JSON 字符串和对象类型),所以先实现
lept_stringify_string()。注意,字符串的语法比较复杂,一些字符必须转义,其他少于0x20的字符需要转义为u00xx形式。直接在
lept_stringify_value()的switch内实现 JSON 数组和对象类型的生成。这些实现里都会递归调用lept_stringify_value()。在你的
lept_stringify_string()是否使用了多次PUTC()?如果是,它每次输出一个字符时,都要检测缓冲区是否有足够空间(不够时需扩展)。能否优化这部分的性能?这种优化有什么代价么?
如果你遇到问题,有不理解的地方,或是有建议,都欢迎在评论或 issue 中提出,让所有人一起讨论。