
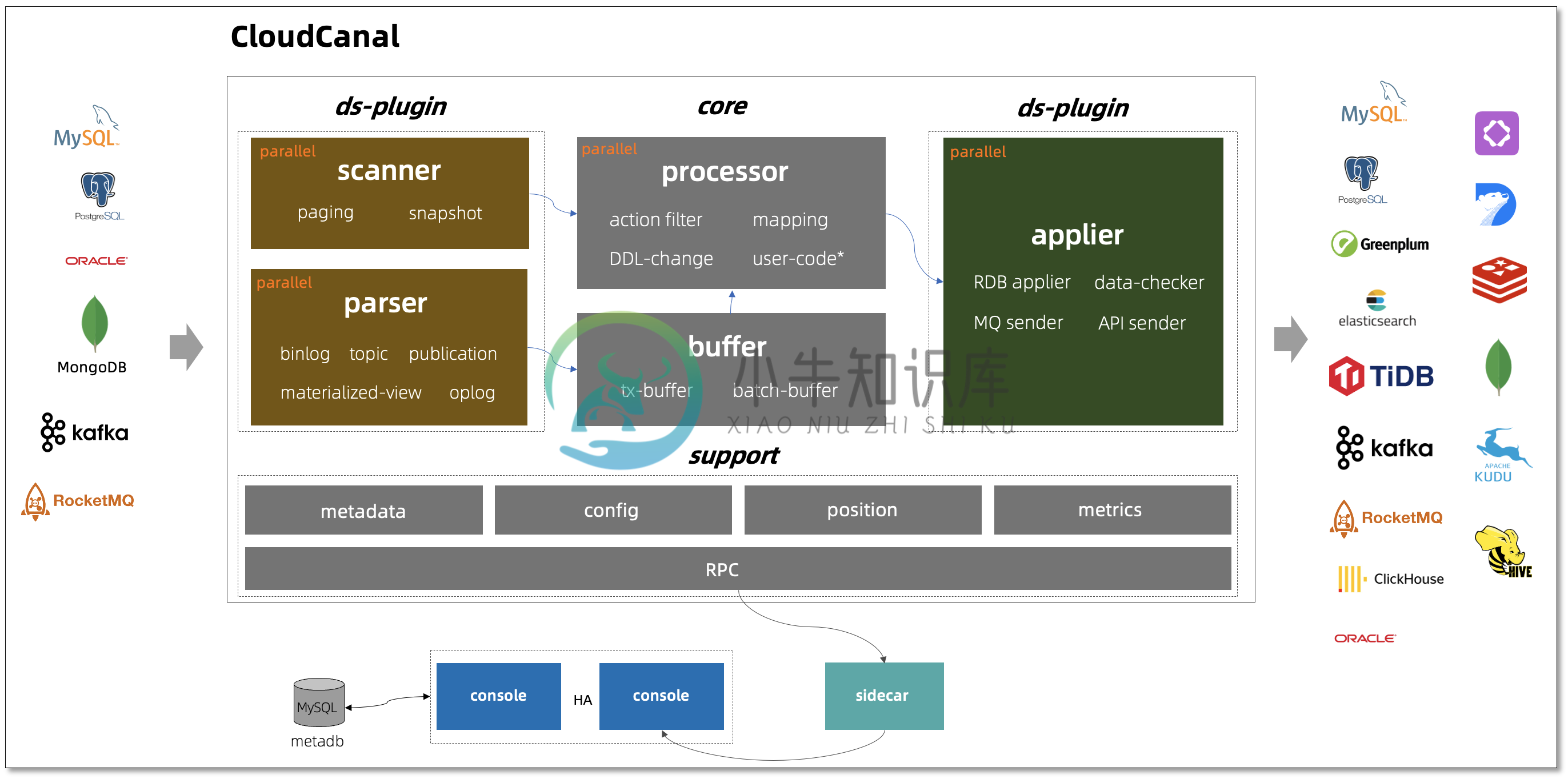
CloudCanal Data Process 是一款针对 CloudCanal SDK 的开源数据处理器,原生官方 SDK 只有一些说明文档。
本项目是由官方人员发起并与社区共同推进的自定义代码处理器,本工程汇集了 CloudCanal 数据处理插件,以达成数据自定义 transformation 目标。
插件说明
- wide-table : 打宽表数据处理插件,主要包括事实表和单维表组合处理
- data-transform : 数据通用转换插件,比如做操作变幻、额外加字段、清洗回填数据
- data-gather : 数据汇聚插件,将分库分表、垂直拆分、异地数据进行实时汇聚
- data-compare : 数据对比插件,根据源端数据变化进行业务对账
- business-alert : 业务告警插件,根据数据变化趋势做出相应告警
使用说明
- 安装 CloudCanal 并创建数据迁移同步任务
- 将需要使用的 CloudCanalProcessor 实现类(如:WideTableProcessorV2_simple)进行适配性改造
- 子工程下 src/main/resources/META-INF/cloudcanal/plugin.properties 中修改为需要使用的类
- 子工程下
mvn -Dtest -DfailIfNoTests=false -Dmaven.javadoc.skip=true -Dmaven.compile.fork=true clean package打包 - CloudCanal 控制台创建任务(参考案例文章),并上传子工程 target 下 jar 包(如:wide-table-1.0.0-SNAPSHOT.jar)
CloudCanal
相关资源
- 官方原始文档 https://www.clougence.com/cc-doc/operation/custom_processor
-
官方产品文档 https://www.clougence.com/cc-doc/intro/product_intro
-
数据处理 可将字段的值进行处理得到最终结果 html标签过滤 内容替换 批量替换 关键词过滤 条件判断 截取字符串 翻译 工具箱 将文本链接标记为图片链接:如果字段的值是完整的url链接(非<img>标签内的链接),可将链接识别为图片 使用函数 调用接口
-
我遇到了一些数据,我想用许多不同的方式对它进行排序,例如按购买最多的最便宜的产品进行排序。我想一行一行地对文档进行分组,因为每行包含另一个“项目”。我附上了一张图片供参考。我更喜欢使用Java,但如果有必要,我会学习R。我是否手动将每行编码为数组?有400个项目,如果这是唯一的方法,我可以将其分成几天。 样品
-
Data Preparation You must pre-process your raw data before you model your problem. The specific preparation may depend on the data that you have available and the machine learning algorithms you want
-
在输入的JSON数据中,v的值越高,粒子越亮,并且它们从出发国家到目的国家的运行越快。 (请查阅Michael Chang的文章来 了解他是如何提出这个想法的)。Gio.js库会自动缩放输入数据的范围以便于更好的数据可视化。作为开发人员,您还可以定义自己的预处理数据的方式。
-
随着数据获取的便捷,GIS数据已不再成为GIS分析的瓶颈,但对海量数据的加载却又成了GIS相关软件的难题。LocaSpaceViewer对数据的加载进行了大量的优化,极大的加快了数据的加载速度。同时经过各种摸索,不断的改进算法与数据的存储和读取方式,研究出了能够加载速度更快的数据结构。 LocaSpaceViewer提供了数据影像处理功能,可以把多个影像或者地形数据进行
-
坐标地址批处理工具 功能介绍 地理编码指将结构化内容转换为经纬度坐标,逆地理编码指将经纬度坐标转换成结构化地址。使用该功能模块,可以快速批量把Excel文件内的大量地址转换为经纬度信息,或者实现反查。 当前功能模块使用高德接口。由于地理编码与逆地理编码需要使用高德API接口,而API接口日请求次数有限,公共API KEY无法满足大批量请求,使用自己申请的高德KEY可以解
-
本文向大家介绍python数据预处理 :数据共线性处理详解,包括了python数据预处理 :数据共线性处理详解的使用技巧和注意事项,需要的朋友参考一下 何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度。共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺
-
问题内容: 我用来并行化一些繁重的计算。 目标函数返回大量数据(庞大的列表)。我的RAM用完了。 如果不使用,我只需将生成的元素依次计算出来,就将目标函数更改为生成器。 我了解多处理不支持生成器- 它等待整个输出并立即返回,对吗?没有屈服。有没有一种方法可以使工作人员在数据可用时立即产生数据,而无需在RAM中构造整个结果数组? 简单的例子: 这是Python 2.7。 问题答案: 这听起来像是队列