
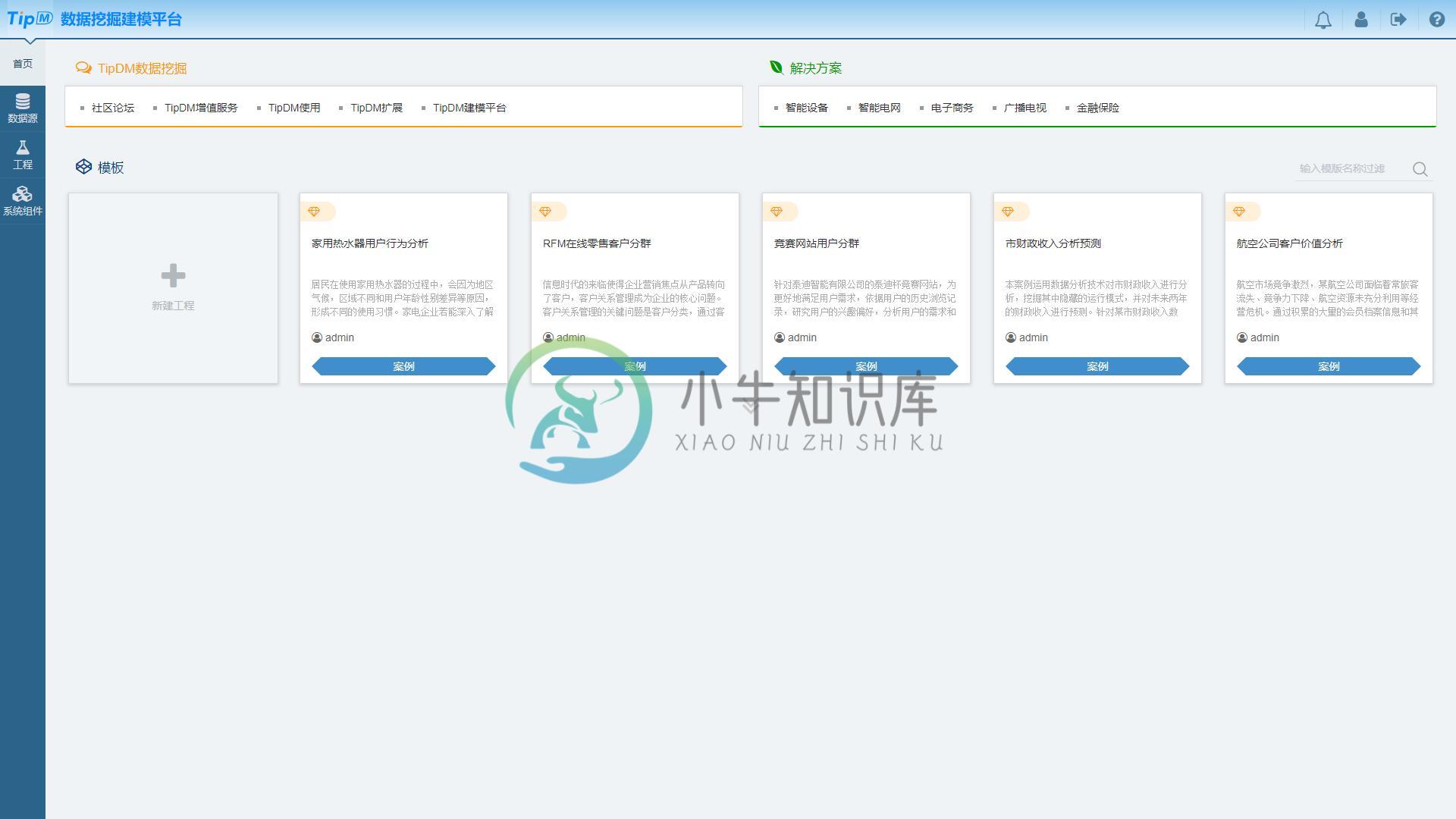
TipDM数据挖掘建模平台是基于Python引擎、用于数据挖掘建模的开源平台。平台提供数量丰富的数据分析与挖掘建模组件,用户可在没有编程基础的情况下,通过拖拽的方式进行操作,将数据输入输出、数据预处理、挖掘建模、模型评估等环节通过流程化的方式进行连接,帮助用户快速建立数据挖掘工程,提升数据处理的效能。平台的界面如图1所示。
主要特性:
- 基于Python,用于数据挖掘建模。
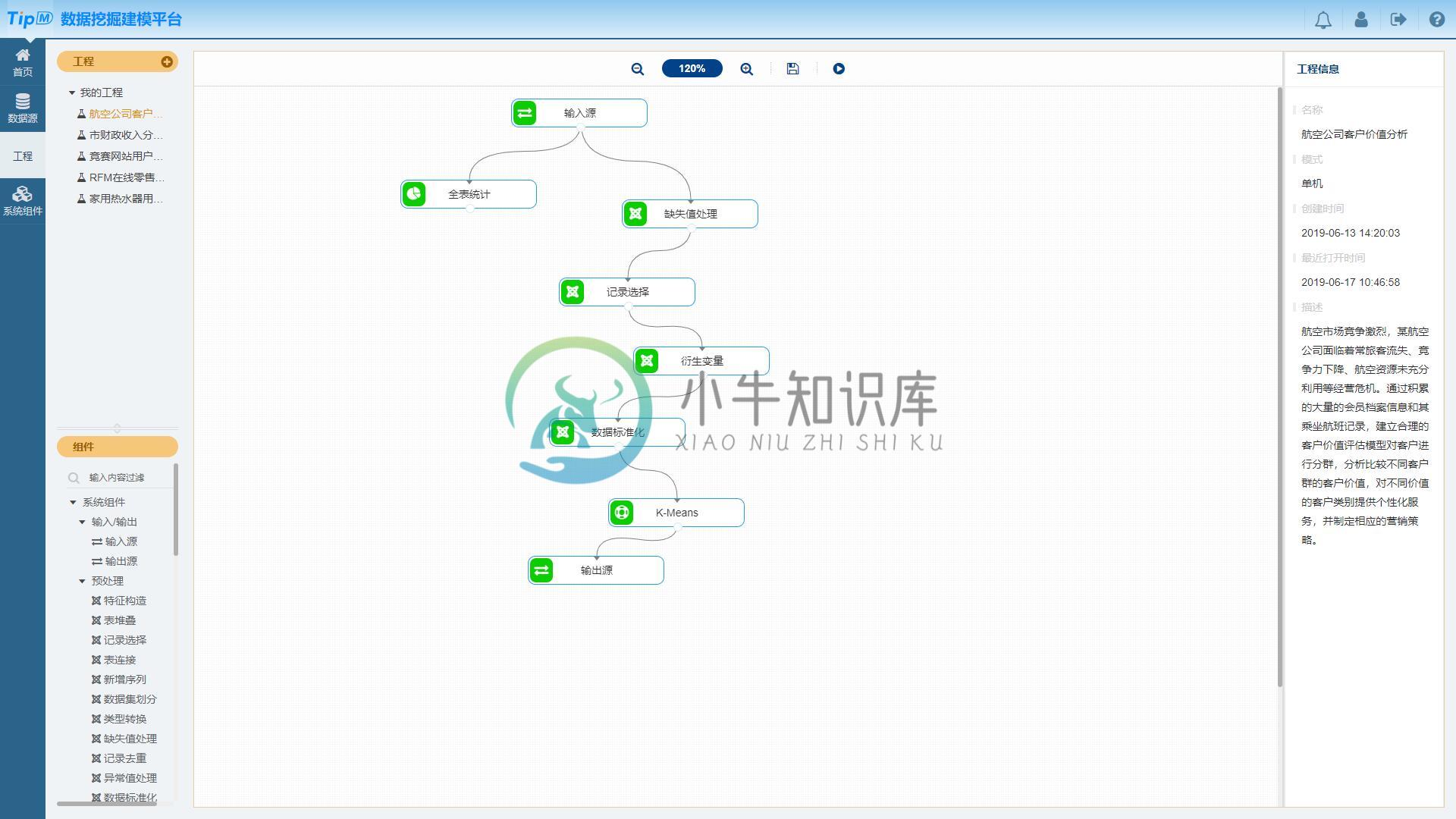
- 使用直观的拖放式图形界面构建数据挖掘工作流程,无需编程。
- 支持多种数据源,包括CSV文件和关系型数据库。
- 支持挖掘流程每个节点的结果在线预览。
- 提供5大类共40种算法组件,包括数据预处理、分类、聚类等数据挖掘算法。
- 支持新增/编辑算法组件,自定义程度高。
- 提供众多公开可用的数据挖掘示例工程,一键创建,快速运行。
- 提供完善的交流社区,提供数据挖掘相关的学习资源(数据、代码和模型等)。
Screenshot
-
数据挖掘 18 大算法实现以及其他相关经典 DM 算法,BIRCH 算法本身上属于一种聚类算法,不过他克服了一些 K-Means 算法的缺点。
-
一位挖掘专家 tom khabaza 提出了挖掘九律,挺好的东西,特别是九这个数字,深得中华文化精髓,有点独孤九剑的意思: 第一,目标律。 数据挖掘是一个业务过程,必须得有业务目标。无目的,无过程。 第二,知识律。 业务知识贯穿在挖掘这个业务过程的各环节。 第三,准备律。 数据获取、数据准备等数据处理耗时占整个挖掘过程的一半。 第四,NFL律。 NFL,没有免费的午餐。没有一个固定的算法适用所有的
-
字节跳动 (1h) 1.自我面试 2.挑一个你认为比较成功的项目进行介绍? 3.介绍你做过的特征工程 4.你都有过哪些算法?介绍下随机森林、XGB、GBDT的差异 5.对模型进行评估时候选取的方法 携程控股(45min) 1.自我介绍 2.选择一个项目进行介绍 3.你建模的时候都用到哪些方法 4.项目细节 5.模型评估 腾讯科技(1个小时) 1.自我介绍 2.直接问项目 3.解释下随机森林和GBD
-
硕士研究cv 可能和数据挖掘不是那么匹配~ 大华一面(1h): 1、增量学习的科研项目(问了具体的细节 以及为什么) 2、语义分割的发展 3、UNet中的跳跃连接的作用 4、残差网络的shortcut连接的作用,数学方面证明残差网络可以避免梯度消失,并且问了一个关于残差网络的改进问题(面试官看最新的论文看到的,我没有理解他所说的问题) 5、宫颈肿瘤分割和pcr预测的项目(细节也问的很详细) 6、预
-
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
-
1.1 KNN 1.1.1 思想 计算离待分类点距离最近的 K 个已分类点,K 个点中出现最多点种类为待分类点的种类。 1.1.2 距离 常见距离有欧式距离和余弦距离。余弦距离可以消除量纲的影响。相关系数 2. 聚类算法 2.1 K-means 2.1.1 思想 2.1.1.1 模型训练 根据类别个数 N,初始化 N 个点,作为该类别的中点。 遍历其他点,计算距离最近的中心点,该中心点的类别为当前
-
2道编程共40分,5道问答110分,共两个半小时,没做多久就退出来,哎。。。 有一道编程题用例过了,一提交通过0个用例,麻了 大佬给看看: 题目是车牌号识别准确率计算 输入N个车牌号,第一个字母是颜色,最后5个是号码,中间是地区号 每一行一个识别出的号码,一个真实标签 #我的秋招日记##网易雷火笔试##23届秋招笔面经#
-
时间过去有点久了,纯凭回忆,可能有些遗漏 一面 (1小时多吧) 机器学习基础知识 Bagging & Boosting 常用的聚类算法 Kmeans和DBSCAN的原理和区别 逻辑回归的原理 怎么处理离散数据 支持向量机原理 SVM怎么处理非线性 常用的回归模型 Attention原理 RNN和LSTM的区别 什么是梯度爆炸/梯度消失,什么情况下会出现 梯度渐进的原理 手撕算法 判断是否是回文 找