
背景
当前比较流行的hdfs间数据迁移工具有hadoop默认提供的distcp,阿里开源的DataX,这些工具能够满足常规的大部分需求,但是当时碰到hadoop版本不一致、keberos授权等场景时就行不通了。针对这些特殊的应用场景和实际需求我就构思并实现了HdfsDataExchanger这种实现方案。通过在一台可以访问两边hadoop集群的中转机上部署HdfsDataExchanger就可以实现将一个集群的数据迁移到另一个集群。HdfsDataExchanger提供单机多线程数据迁移,不支持分布式并行执行。
功能介绍
不同版本的hdfs间文件迁移。
本地文件系统与hdfs间文件迁移。

原理说明
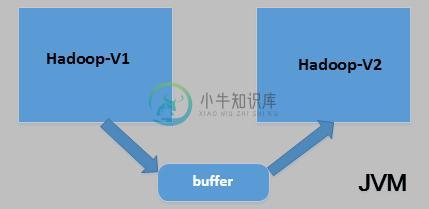
抽象一套hdfs文件操作接口。
使用源集群和目标集群对应版本的hadoop分别实现接口。
使用jetty的WebAppClassLoader分别加载两套(源和目标)hdfs相关的jar,并创建对应的FileSystem。
使用源FileSystem读取数据到缓冲区,然后使用目标FileSystem将缓冲区的数据写入到目标文件。

使用说明
data-exchanger目录下包含完整的部署目录
h1为hadoop1的配置(conf)和相关的jar包(jars)
h2为hadoop2的配置(conf)和相关的jar包(jars)
main为主程序相关的配置(conf)、相关的jar包(jars)和启动脚本(bin)
配置说明
参数名 说明 thread.count 并行进行迁移数据的线程数量 buffer.size 读取数据缓冲区大小 src/dest.hdfs.resource.path 源/目标hdfs的jar包目录 src/dest.filesystem.implement 源/目标针对抽象出的hdfs接口(com.sebastian.fdx.fs.api.BaseFileSystem)的实现类,WebAppClassLoader根据此配置加载对应的实现 src/dest.hdfs.conf.path 源/目标对应的core-site.xml和hdfs-site.xml h1和h2的jars目录下应该包含依赖的所有hadoop jar包,当前只包含了fdx-hadoopX-filesystem-1.0-SNAPSHOT.jar,用户在使用时需根据实际的hadoop版本自行编译,并将依赖的jar和编译出来的jar一并放到对应的目录下。
main/jars目录放fdx-executor和fdx-filesystem-api编译出的jar以及依赖的所有jar。
main/conf/parameter.xml
执行
bin/run.sh src_path1 src_path2 ... dest_path 将src_pathX下的所有文件、目录复制到dest_path下
-
如有任何帮助,不胜感激。
-
根据最近的一篇文章,Kafka可以在复制配置下删除已确认的消息: https://aphyr.com/posts/293-call-me-maybe-kafka 如果必须绝对确定消息已发送给消费者,此解决方案是否在所有情况下都有效: 建立两个主题,一个用于发送,一个用于接收 即使在丢弃消息的情况下也能工作吗?这个图案有名字吗?
-
我有一个问题,在java中找到两个数组之间的区别,我的例子就像假设我们有两个数组。数组和数组。我想有两个结果第一个结果是一个数组,它从数组“A”中找到丢失的对象,第二个结果是一个数组,它在数组“B”中找到添加的对象。第一个结果应类似于,第二个结果类似于。 感谢您的评论。
-
问题内容: 我对SQL(Server2008)的较低层次的了解是有限的,现在我们的DBA对此提出了挑战。让我解释一下这种情况:(我已经提到一些明显的陈述,希望我是对的,但是如果您发现有问题,请告诉我)。 我们有一张桌子,上面放着人们的“法院命令”。创建表(名称:CourtOrder)时,我的创建方式如下: 然后,我将非聚集索引应用于主键(以提高效率)。我的理由是,这是一个唯一字段(主键),应该像我
-
我在第一个elasticsearch/logstash/kibana节点中配置了集群,并在该节点中重新启动了ELK。它是成功的。但是,一旦我在第二个ELK节点中配置了集群,第一个节点logstash将自动停止,出现以下错误 和Im使用elasticsearch输出插件,我在其中添加了集群节点,如下所示。 我在第一个节点elasticsearch.yml和logstash output.conf文件
-
Cluster Cluster.EdsClusterConfig Cluster.OutlierDetection Cluster.LbSubsetConfig Cluster.LbSubsetConfig.LbSubsetSelector Cluster.LbSubsetConfig.LbSubsetFallbackPolicy (Enum) Cluster.RingHashLbConfig C
-
我们有没有可能在Spark中先按一列分区,然后再按另一列聚类? 在我的例子中,我在一个有数百万行的表中有一个< code>month列和一个< code>cust_id列。我可以说,当我将数据帧保存到hive表中,以便根据月份将该表分区,并按< code>cust_id将该表聚类成50个文件吗? 忽略按< code>cust_id的聚类,这里有三个不同的选项 第一种情况和最后一种情况在 Spark
-
我目前正在一个小型集群(3个节点,32个CPU和128 GB Ram)上使用线性回归(Spark ML)中的基准测试来评估Spark 2.1.0。我只测量了参数计算的时间(不包括启动、数据加载、……)并识别了以下行为。对于小的数据集,0.1MIO-3MIO数据点,测量的时间并没有真正增加,停留在大约40秒。只有对于较大的数据集,如300个Mio数据点,处理时间才会达到200秒。因此,集群似乎根本无