
XWorld 是一个用于强化学习的 C ++ / Python 模拟器程序包,该存储库包含了用于强化学习研究的模拟器集合。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
XWorld 具有 teacher 基础架构,该基础架构被实现为多个有限状态机(Finite State Machines,FSM)的调度程序。这样的想法是,在给定环境的情况下,teacher 可以提出从任务集中抽样(通过一些启发式方法)的任务。制定为 FSM 的每个任务都有多个阶段,teacher 在不同阶段执行不同的任务。从一个阶段到另一个阶段的过渡取决于环境状态,例如,代理处于空闲状态还是它是否已实现目标。每个阶段都会返回几件事,包括下一阶段和 teacher 的动作。目前,该团队将语言(字符串)定义为 teacher 的唯一行为。但是,teacher 可以在每个阶段更改环境(例如,添加/删除对象,更改地图大小等)。
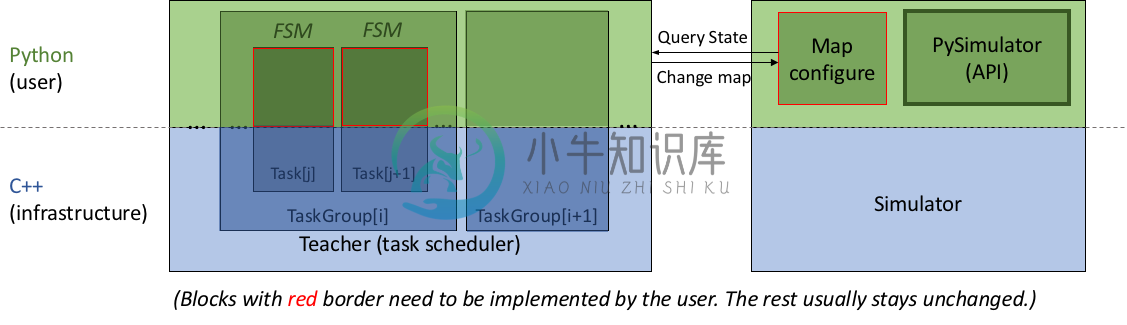
上图对架构进行了说明。其目的是让用户灵活地编写简单的 Python 脚本来配置环境映射和任务。
当前,该 teacher 仅合并到 XWorld2D 和 XWorld3D 中。
要求
- 编译器:GCC 4.8 或更高
- CMake:CMake 3.0 或以上
- Python:Python 2.7
依存关系
在构建 XWorld 之前,必须安装以下软件。
Boost, Glog, GFlags, GTest 和 Python
在 Ubuntu 14.04 和 16.04 中,您可以执行
sudo apt-get install libboost-all-dev libgflags-dev libgoogle-glog-dev libgtest-dev python-dev
-
主要内容 课程列表 基础知识 专项课程学习 参考书籍 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 MDP和RL介绍8 9 10 11 Berkeley 暂无 链接 MDP简介 暂无 Shaping and policy search in Reinforcement learning 链接 强化学习 UCL An Introduction to Reinforcement Lea
-
强化学习(Reinforcement Learning)的输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入/输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。 Deep Q Learning.
-
译者:平淡的天 作者: Adam Paszke 本教程将展示如何使用 PyTorch 在OpenAI Gym的任务集上训练一个深度Q学习 (DQN) 智能点。 任务 智能点需要决定两种动作:向左或向右来使其上的杆保持直立。你可以在 Gym website 找到一个有各种算法和可视化的官方排行榜。 当智能点观察环境的当前状态并选择动作时,环境将转换为新状态,并返回指示动作结果的奖励。在这项任务中,每
-
探索和利用。马尔科夫决策过程。Q 学习,策略学习和深度强化学习。 我刚刚吃了一些巧克力来完成最后这部分。 在监督学习中,训练数据带有来自神一般的“监督者”的答案。如果生活可以这样,该多好! 在强化学习(RL)中,没有这种答案,但是你的强化学习智能体仍然可以决定如何执行它的任务。在缺少现有训练数据的情况下,智能体从经验中学习。在它尝试任务的时候,它通过尝试和错误收集训练样本(这个动作非常好,或者非常
-
本文向大家介绍关于机器学习中的强化学习,什么是Q学习?,包括了关于机器学习中的强化学习,什么是Q学习?的使用技巧和注意事项,需要的朋友参考一下 Q学习是一种强化学习算法,其中包含一个“代理”,它采取达到最佳解决方案所需的行动。 强化学习是“半监督”机器学习算法的一部分。将输入数据集提供给强化学习算法时,它会从此类数据集学习,否则会从其经验和环境中学习。 当“强化代理人”执行某项操作时,将根据其是否
-
强化学习(RL)如今是机器学习的一大令人激动的领域,也是最老的领域之一。自从 1950 年被发明出来后,它被用于一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和机器控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,在多数游戏中,比人类玩的还好,它仅
-
强化学习(RL)如今是机器学习的一大令人激动的领域,当然之前也是。自从 1950 年被发明出来后,它在这些年产生了一些有趣的应用,尤其是在游戏(例如 TD-Gammon,一个西洋双陆棋程序)和及其控制领域,但是从未弄出什么大新闻。直到 2013 年一个革命性的发展:来自英国的研究者发起了一项 Deepmind 项目,这个项目可以学习去玩任何从头开始的 Atari 游戏,甚至多数比人类玩的还要好,它
-
在本章中,您将详细了解使用Python在AI中强化学习的概念。 强化学习的基础知识 这种类型的学习用于基于评论者信息来加强或加强网络。 也就是说,在强化学习下训练的网络从环境中接收一些反馈。 然而,反馈是有评价性的,而不是像监督学习那样具有指导性。 基于该反馈,网络执行权重的调整以在将来获得更好的批评信息。 这种学习过程类似于监督学习,但我们的信息可能非常少。 下图给出了强化学习的方框图 - 构建