
AutoTiKV 是一个用于对 TiKV 数据库进行自动调优的工具
整个调优过程大致如下图:
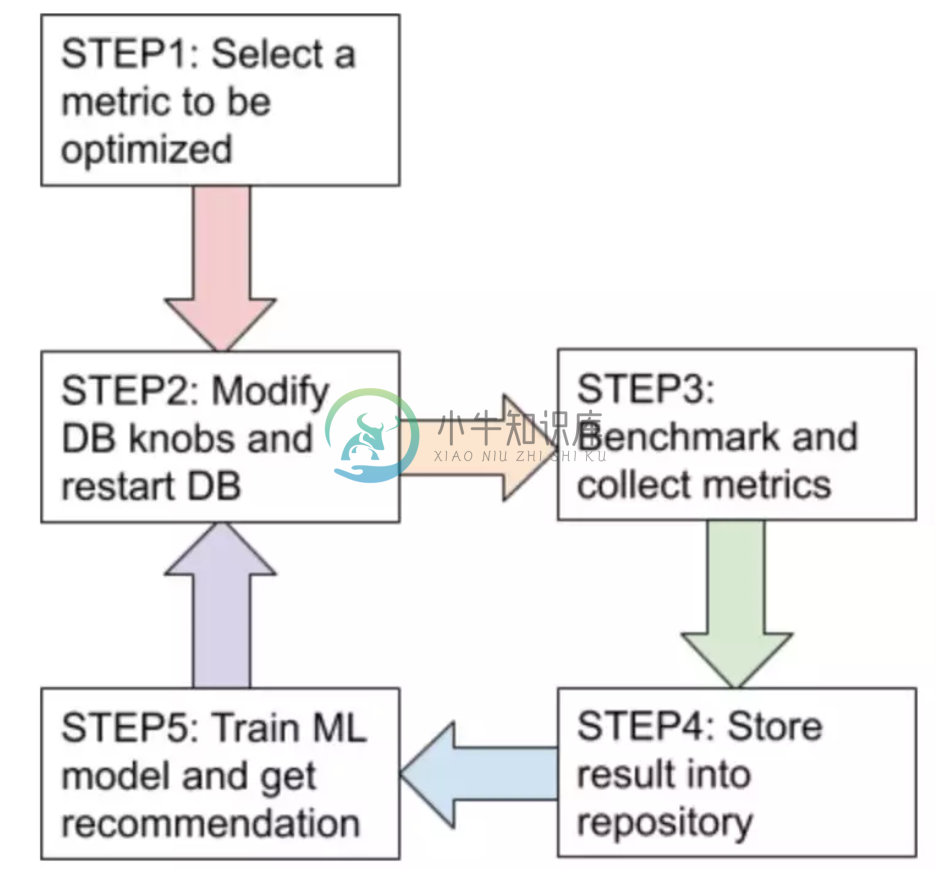
AutoTiKV 支持在修改参数之后重启 TiKV(如果不需要也可以选择不重启)。需要调节的参数和需要查看的 metric 可以在 controller.py 里声明。
一开始的 10 轮(具体大小可以调节)是用随机生成的 knob 去 benchmark,以便收集初始数据集。之后的都是用 ML 模型推荐的参数去 benchmark。
AutoTiKV 使用了和 OtterTune 一样的高斯过程回归(Gaussian Process Regression,以下简称 GP)来推荐新的 knob[1],它是基于高斯分布的一种非参数模型。高斯过程回归的好处是:
1. 和神经网络之类的方法相比,GP 属于无参数模型,算法计算量相对较低,而且在训练样本很少的情况下表现比 NN 更好。
2. 它能估计样本的分布情况,即 X 的均值 m(X) 和标准差 s(X)。若 X 周围的数据不多,则它被估计出的标准差 s(X) 会偏大(表示这个样本 X 和其他数据点的差异大)。直观的理解是若数据不多,则不确定性会大,体现在标准差偏大。反之,数据足够时,不确定性减少,标准差会偏小。这个特性后面会用到。
但 GP 本身其实只能估计样本的分布,为了得到最终的预测值,我们需要把它应用到贝叶斯优化(Bayesian Optimization)中。贝叶斯优化算法大致可分为两步:
1. 通过 GP 估计出函数的分布情况。
2. 通过采集函数(Acquisition Function)指导下一步的采样(也就是给出推荐值)。
采集函数(Acquisition Function)的作用是:在寻找新的推荐值的时候,平衡探索(exploration)和利用(exploitation)两个性质:
-
exploration:在目前数据量较少的未知区域探索新的点。
-
exploitation:对于数据量足够多的已知区域,利用这些数据训练模型进行估计,找出最优值。
在推荐的过程中,需要平衡上述两种指标。exploitation 过多会导致结果陷入局部最优值(重复推荐目前已知的最好的点,但可能还有更好的点没被发现),而 exploration 过多又会导致搜索效率太低(一直在探索新区域,而没有对当前比较好的区域进行深入尝试)。而平衡二者的核心思想是:当数据足够多时,利用现有的数据推荐;当缺少数据时,我们在点最少的区域进行探索,探索最未知的区域能给我们最大的信息量。
贝叶斯优化的第二步就可以帮我们实现这一思想。前面提到 GP 可以帮我们估计 X 的均值 m(X) 和标准差 s(X),其中均值 m(x) 可以作为 exploitation 的表征值,而标准差 s(x) 可以作为 exploration 的表征值。这样就可以用贝叶斯优化方法来求解了。
使用置信区间上界(Upper Confidence Bound)作为采集函数。假设我们需要找 X 使 Y 值尽可能大,则 U(X) = m(X) + k*s(X),其中 k > 0 是可调的系数。我们只要找 X 使 U(X) 尽可能大即可。
-
若
U(X)大,则可能m(X)大,也可能s(X)大。 -
若
s(X)大,则说明X周围数据不多,需要探索未知区域新的点。 -
若
m(X)大,说明估计的Y值均值大, 则需要利用已知数据找到效果好的点。 -
其中系数
k影响着探索和利用的比例,k越大,越鼓励探索新的区域。
在具体实现中,一开始随机生成若干个 candidate knobs,然后用上述模型计算出它们的 U(X),找出 U(X) 最大的那一个作为本次推荐的结果。
更详细介绍请看文章。
-
偏差与方差 《机器学习》 2.5 偏差与方差 - 周志华 偏差与方差分别是用于衡量一个模型泛化误差的两个方面; 模型的偏差,指的是模型预测的期望值与真实值之间的差; 模型的方差,指的是模型预测的期望值与预测值之间的差平方和; 在监督学习中,模型的泛化误差可分解为偏差、方差与噪声之和。 偏差用于描述模型的拟合能力; 方差用于描述模型的稳定性。 导致偏差和方差的原因 偏差通常是由于我们对学习算法做了错
-
机器学习 概述 机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及
-
机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。
-
本文向大家介绍基于Python和Scikit-Learn的机器学习探索,包括了基于Python和Scikit-Learn的机器学习探索的使用技巧和注意事项,需要的朋友参考一下 你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎。我同时在为一家俄罗斯移动运营商开发大数据产品。这是我第一次在网上写文章,不喜勿喷。 现在,很多人想开发高效的算法以及参加机器学习的竞赛。所以他
-
随着 AlphaGo 在人机大战中一举成名,关于机器学习的研究开始广受关注,数据科学家也一跃成为 21世纪最性感的职业。关于机器学习和神经网络的广泛应用虽然兴起不久,但是对这两个密切关联的领域的研究其实已经持续了好几十年,早已形成了系统化的知识体系。对于想要踏入机器学习领域的初学者而言,理论知识的获取并非难事。
-
Kubernetes 在大数据与机器学习中的实践案例。
-
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
-
机器学习即Machine Learning,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。目的是让计算机模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断完善自身的性能。简单来讲,机器学习就是人们通过提供大量的相关数据来训练机器。