
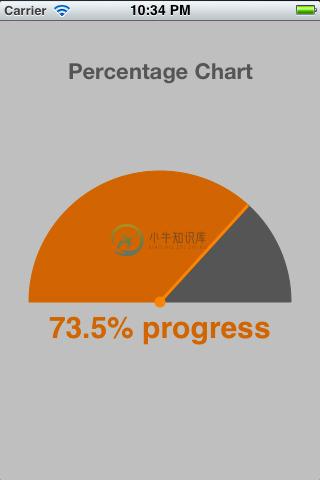
PercentageChart 使用动画的效果显示百分比的数据
-
引用 <script src="Scripts/jquery-1.8.2.min.js"></script> <script type="text/javascript" src="highcharts.js"></script> 先后顺序不能反 在body里给三个div分别给上id 饼图 $(function () { $("#container").highcharts(
-
1.Chart writing 1.1Step to incoporate charts informatin into writing (1) Make sure you understand every detailed information in the chart (2)Provide an appropriate introdution (the contents of the cha
-
I like the previous answer, but I felt it was lacking in code clarity and it didn't really cover how to utilize labels. I moved the values into a data object array for easy declaration. Other values,
-
I collected all the supported chart in openpyxl in one script, please check it. But the chart which openpyxl created seems not beautiful as manual created in excel. from openpyxl import Workbook, load
-
""" openpyxl_chart_type_demos.py (openpyxl四:图表类型) 使用: 图表类型: #AreaChart面积图表、BarChartm条形图/柱形图/成交量图、BubbleChart气泡图、 #LineChart折线图/LineChart3D折线图、 #ScatterChart散点图、PieChart饼图/PieChart3D饼图/ProjectedPieC
-
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
百分数由一个数字和一个百分号组成,数字和百分号之间,不允许出现空格。百分数可以是整数或小数,可以是正数或负数。如果数字为0,则可以省略百分号。 百分比的值几乎总是相对于另一个值(如长度单位)计算得到的。每一个允许使用百分比单位的属性,都要定义百分比的参考值。大多数情况下,百分比的参考值都是元素本身的字体大小,即 font-size 属性的值。如: div { font-size: 14p
-
问题内容: 我有4个项目MySQL数据库:(数值),和。 在我的报告中,我需要通过“调查”中的数字来计算已参加调查的“雇员”的百分比。 这是我现在的声明: 表格如下: 我想按参加调查的人数来计算谁所占的百分比。即,如以上数据所示,分别为0%和95%。 问题答案: 尝试这个 在这里演示
-
我有一个包含4个项的MySQL数据库:(数值)、、和。 在我的中,我需要根据“surveys”中的数字来计算接受调查的“employees”的百分比。 这就是我现在的说法: 下面是表格的原样: 我想根据中的数字计算参加调查的的百分比。即,如上面的数据所示,将为0%,将为95%。
-
我正在使用Elasticsearch 1.7.3为分析报告积累数据。 我有一个保存文档的索引,其中每个文档都有一个名为“duration”(请求花费了多少毫秒)的数字字段和一个名为“component”的字符串字段。可能有许多文档具有相同的组件名称。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总数占所有文档总持续时间的百分比。在我的例子中 每个组件的文档占总
-
SWIG文档对这两个指令解释如下: > :“SWIG提供了另一个带有指令的文件包含指令。的目的是从另一个SWIG接口文件或头文件收集某些信息,而不实际生成任何包装代码。此类信息通常包括类型声明(例如,typedef)以及可能用作接口中类声明基类的C类。" 我的问题是这两个指令之间有什么区别,使用它们的利弊是什么? 顺便说一下,我只是想了解一些背景信息。我有一个简单的C-python扩展,当我使用上
-
问题内容: 假设我要按第10到20个百分点内的某个字段过滤文档。我想知道是否可以通过一些简单的查询(例如)进行查询。 说我有这些文件: 我需要按(升序) 从前10位到第10位进行过滤,然后按降序对结果进行排序,然后进行分页(如第2页,第10页)每页的项目)。 想到的一种解决方案是: 获取文件总数。 将文档按排序,取对应的限制 写最终查询,像 但是缺点也很明显: 如果我们谈论的是亚秒级延迟,则似乎效
-
问题内容: 我有这个查询: 它给了我每一行的计数。现在,我想添加第三列,这将给我带来帮助。 我怎样才能做到这一点? 问题答案: 您可以使用子查询来做到这一点: 或带有变量: 在两个示例中,我都将count(*)转换为实数,以避免整数除法类型问题。 希望这对约翰有帮助