
EnCodec 是一个基于深度学习的音频编解码器,由 AI 驱动,可以在音频质量没有损失的前提下,将音频压缩到比 MP3 格式还要小 10 倍的程度。
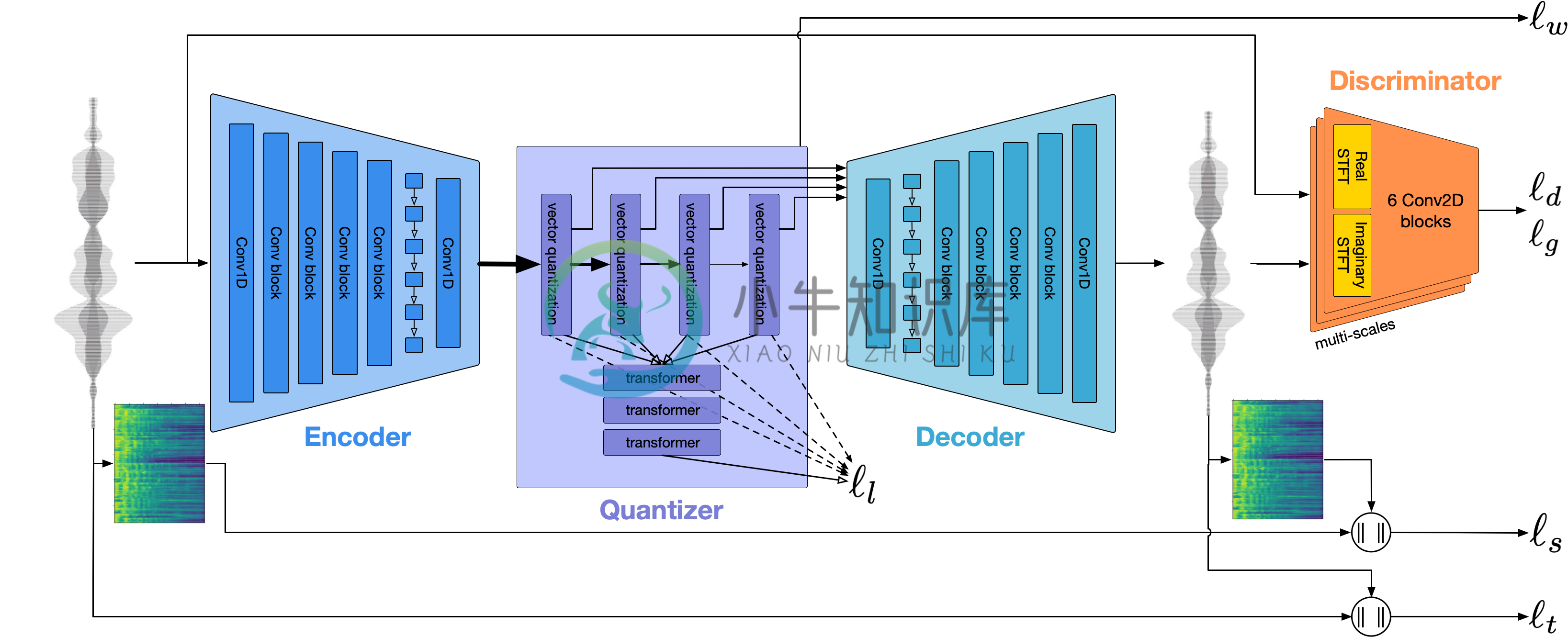
实现过程如下:
- 首先,编码器将未压缩的数据转换为较低帧率的 "latent space" 表示(representation);
- 然后,量化器将这个表示压缩到目标大小,同时跟踪最重要的信息,这些信息以后将被用于重建原始信号(这个压缩信号将通过网络发送或保存在磁盘上);
- 最后,解码器使用单个 CPU 上的神经网络将压缩的数据实时地转变回音频;
安装
EnCodec 需要 Python 3.8 和 PyTorch 1.11.0,要安装 EnCodec,可以运行:
pip install -U encodec # stable release pip install -U git+https://git@github.com/facebookresearch/encodec#egg=encodec # bleeding edge # of if you cloned the repo locally pip install .
使用
然后,可以使用 EnCodec 命令:
python3 -m encodec [...] # or encodec [...]
-
C++语言的url encode 的用法给你一段代码你就明白了 std::string UrlEncode(const std::string& szToEncode) { std::string src = szToEncode; char hex[] = "0123456789ABCDEF"; string dst; for (size_t i = 0; i < src.size(); ++i
-
源码 // // Created by oceanstar on 2021/8/13. // #ifndef OCEANSTAR_HTTP_ACL_HEX_CODE_H #define OCEANSTAR_HTTP_ACL_HEX_CODE_H namespace oceanstar{ /** * 将二进制数据进行编码,一个字节转换成两个字节后,从而转为文本字符串
-
用python的requests向数据库写入带中文的json数据时,出现如题所示错误,是因为编码问题 解决方法: 先编码成bytes(utf-8)格式再解码为latin1 data=data.encode(“utf-8”).decode(“latin1”)
-
中文乱码 UnicodeEncodeError: ‘latin-1‘ codec can‘t encode characters 中文字符.encode("gb18030").decode("latin-1")
-
Python 排错UnicodeEncodeError 'ascii' codec can't encode character 错误解决方法 参考文章: (1)Python 排错UnicodeEncodeError 'ascii' codec can't encode character 错误解决方法 (2)https://www.cnblogs.com/shouke/p/10157827.ht
-
PIL 往图片上写入中文报错UnicodeEncodeError: ‘latin-1’ codec can’t encode characters in position PIL 往图片上写入中文报错 UnicodeEncodeError: ‘latin-1’ codec can’t encode characters in position # 问题描述: PIL 往图片上写入中文报错 Unic
-
场景: ERROR: Exception: Traceback (most recent call last): File "/usr/lib/python3/dist-packages/pip/_internal/cli/base_command.py", line 186, in _main status = self.run(options, args) File "/usr
-
Python3 报错'latin-1' codec can't encode character 解决方案 参考文章: (1)Python3 报错'latin-1' codec can't encode character 解决方案 (2)https://www.cnblogs.com/shitou6/p/8990162.html 备忘一下。
-
问题描述 使用datetime.strftime转换时间按格式报如下错误: UnicodeEncodeError: 'locale' codec can't encode character '\u5e74' in position 2: encoding error 是由于存在中文字符的原因。 解决办法 在代码中加入中文的支持。 import locale locale.setlocale(lo
-
错误信息:UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\u2764’ in position 98779: illegal multibyte sequence 原因:print()函数自身有限制,不能完全打印所有的unicode字符。 解决方案 import io sys.stdout = io.TextIOWrapper(sy
-
Keras 是一个高层神经网络 API,Keras 由纯 Python 编写而成并基 Tensorflow、Theano 以及 CNTK 后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择 Keras: 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性) 支持 CNN 和 RNN,或二者的结合 无缝 CPU 和 GPU 切换 Kera
-
停止更新通知 Hi all,十分感谢大家对keras-cn的支持,本文档从我读书的时候开始维护,到现在已经快两年了。这个过程中我通过翻译文档,为同学们debug和答疑学到了很多东西,也很开心能帮到一些同学。 从2017年我工作以后,由于工作比较繁忙,更新频率有所下降。到今年早期的时候这种情况更加严重,加之我了解到,keras官方已经出了中文文档,更觉本份文档似乎应该已经基本完成了其历史使命,该到了
-
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
-
相关专题 《深度学习》整理 CNN 专题 RNN 专题 优化算法专题 随机梯度下降 动量算法 自适应学习率算法 基于二阶梯度的优化算法 《深度学习》 5.2 容量、过拟合和欠拟合 欠拟合指模型不能在训练集上获得足够低的训练误差; 过拟合指模型的训练误差与测试误差(泛化误差)之间差距过大; 反映在评价指标上,就是模型在训练集上表现良好,但是在测试集和新数据上表现一般(泛化能力差); 降低过拟合风险的
-
这就是Keras Keras是一个高层神经网络库,Keras由纯Python编写而成并基Tensorflow或Theano。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择Keras: 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性) 支持CNN和RNN,或二者的结合 支持任意的链接方案(包括多输入和多输出训练) 无缝CPU和GPU切换
-
主要内容 课程列表 专项课程学习 辅助课程 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 卷积神经网络视觉识别 Stanford 暂无 链接 神经网络 Tweet 暂无 链接 深度学习用于自然语言处理 Stanford 暂无 链接 自然语言处理 Speech and Language Processing 链接 专项课程学习 下述的课程都是公认的最好的在线学习资料,侧重点不同,但推
-
Google Cloud Platform 推出了一个 Learn TensorFlow and deep learning, without a Ph.D. 的教程,介绍了如何基于 Tensorflow 实现 CNN 和 RNN,链接在 这里。 Youtube Slide1 Slide2 Sample Code
-
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。