
用 YOLOv3 模型在一个开源的人手检测数据集 oxford hand 上做人手检测,并在此基础上做模型剪枝。对于该数据集,对 YOLOv3 进行 channel pruning 之后,模型的参数量、模型大小减少 80% ,FLOPs 降低 70%,前向推断的速度可以达到原来的 200%,同时可以保持 mAP 基本不变(这个效果只是针对该数据集的,不一定能保证在其他数据集上也有同样的效果,之后有时间的话会在其他数据集上进行测试)。
环境
Python3.6, Pytorch 1.0及以上
YOLOv3 的实现参考了 eriklindernoren 的 PyTorch-YOLOv3 ,因此代码的依赖环境也可以参考其 repo
目前部分代码(如prune_utils.py文件)还在修改和完善,最近比较忙,待整理好再发出来
数据集准备
- 下载数据集,得到压缩文件
- 将压缩文件解压到 data 目录,得到 hand_dataset 文件夹
- 在 data 目录下执行 converter.py,生成 images、labels 文件夹和 train.txt、valid.txt 文件。训练集中一共有 4087 张图 片,测试集中一共有 821 张图片
正常训练(Baseline)
python train.py --model_def config/yolov3-hand.cfg
剪枝算法介绍
本代码基于论文 Learning Efficient Convolutional Networks Through Network Slimming (ICCV 2017) 进行改进实现的 channel pruning算法,类似的代码实现还有这个 yolov3-network-slimming。原始论文中的算法是针对分类模型的,基于 BN 层的 gamma 系数进行剪枝的。本项目用到的剪枝算法不限于 YOLOv3 模型,稍作改进理论上也是可以移植到其他目标检测模型的。
剪枝算法的步骤
-
进行稀疏化训练
python train.py --model_def config/yolov3-hand.cfg -sr --s 0.01
-
基于 test_prune.py 文件进行剪枝(通过设定合理的剪枝规则),得到剪枝后的模型
-
对剪枝后的模型进行微调(本项目对原算法进行了改进,实验过程中发现即使不经过微调也能达到较高的 mAP)
python train.py --model_def config/prune_yolov3-hand.cfg -pre checkpoints/prune_yolov3_ckpt.pth
稀疏训练过程的可视化
-
所有 BN 的 gamma 系数的五个五分位点随时间的变化图:
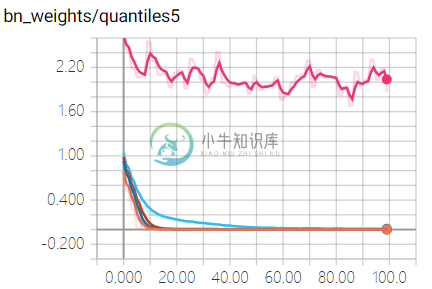
经过 10 次迭代后,60%的 gamma 系数已趋向于 0,40 次迭代后 80% 的 gamma 系数已趋向于 0
-
YOLOv3中第一个 BN 层的 gamma 系数随迭代次数的变化情况:
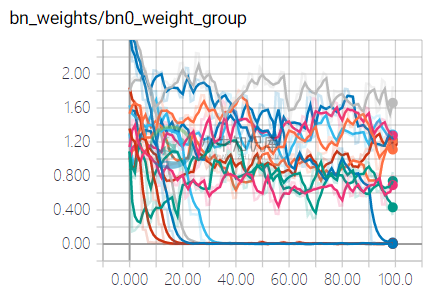
随着模型的更新,部分 gamma 系数逐步趋向于 0(表明其重要性逐渐削弱),而部分 gamma 系数能够保持其权重(表明其对网络的输出有一定的重要性)
-
所有 BN 的 gamma 系数的分布随迭代次数的变化:
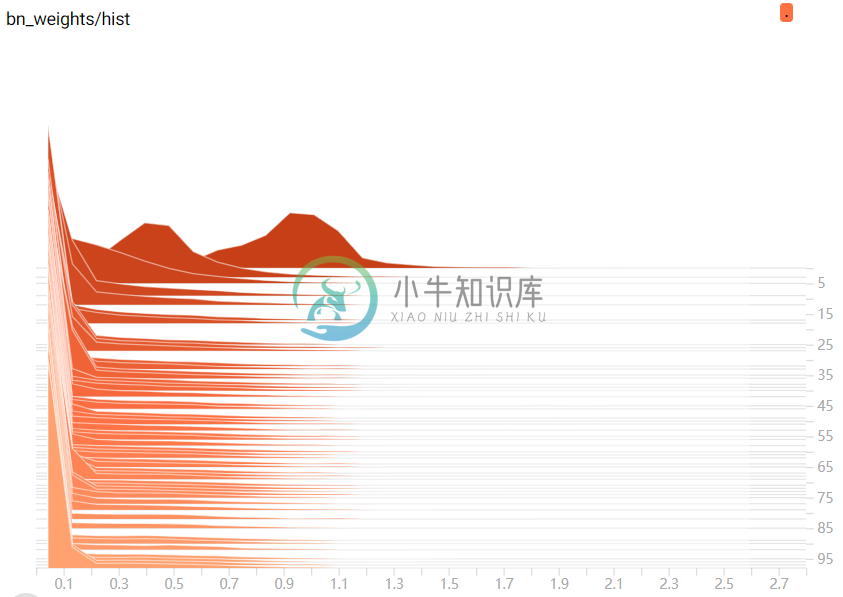
分布的重心逐渐向 0 靠近,但并没有全部衰减为 0,表明 gamma 系数逐渐变得稀疏
剪枝前后的对比
-
下图为对部分卷积层进行剪枝前后通道数的变化:
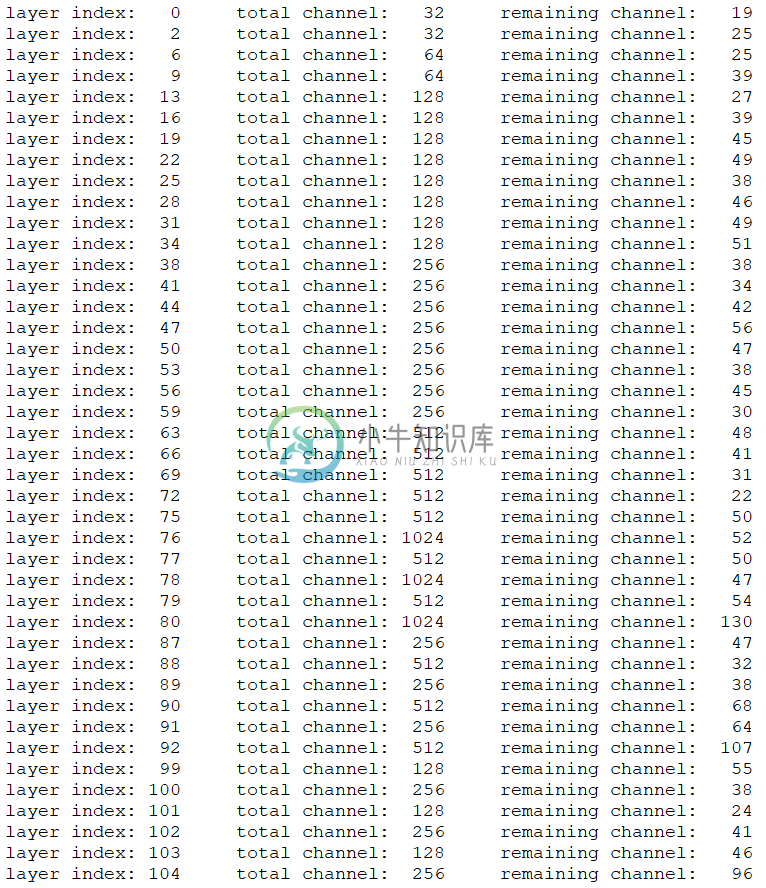
部分卷积层的通道数大幅度减少
-
剪枝前后指标对比:
参数数量 模型体积 Flops 前向推断耗时(2070 TI) mAP Baseline (416) 61.5M 246.4MB 32.8B 15.0 ms 0.7692 Prune (416) 10.9M 43.6MB 9.6B 7.7 ms 0.7722 Finetune (416) 同上 同上 同上 同上 0.7750 加入稀疏正则项之后,mAP 反而更高了(在实验过程中发现,其实 mAP上下波动 0.02 是正常现象),因此可以认为稀疏训练得到的 mAP 与正常训练几乎一致。将 prune 后得到的模型进行 finetune 并没有明显的提升,因此剪枝三步可以直接简化成两步。剪枝前后模型的参数量、模型大小降为原来的 1/6 ,FLOPs 降为原来的 1/3,前向推断的速度可以达到原来的 2 倍,同时可以保持 mAP 基本不变。需要明确的是,上面表格中剪枝的效果是只是针对该数据集的,不一定能保证在其他数据集上也有同样的效果
-
1. 获得最佳训练效果的建议 在大多数情况下,只要数据集足够大且标记良好,无需更改模型或训练设置即可获得良好的结果。如果一开始没有得到好的结果,可以采取一些步骤来改进,但官方总是建议用户在考虑任何更改之前首先使用所有默认设置进行训练。这有助于建立基本标准并找出需要改进的地方。 结果图(训练损失、val 损失、P、R、mAP)、PR 曲线、混淆矩阵、训练马赛克,测试结果和数据集统计图像都位于proj
-
pruning 几点思考: 参考的项目是这个: https://github.com/tanluren/yolov3-channel-and-layer-pruning 参考的论文很有指导意义,在bn层加了scale factor(实际上是对bn层的gamma系数进行压缩),这个值越小,说明对网络不重要,就是可以剪枝的 scale factor范围的确定:在目标函数中加了个正则项,在训练过程中自动
-
YOLOv5介绍 YOLOv5为兼顾速度与性能的目标检测算法。笔者将在近期更新一系列YOLOv5的代码导读博客。YOLOv5为2021.1.5日发布的4.0版本。 YOLOv5开源项目github网址 源代码导读汇总网址 本博客导读的代码为utils文件夹下的torch_utils.py文件,更新日期为2021.1.10. torch_utils.py 该文件为基于pytorch的一些实用工具的编
-
本文参考: https://github.com/Lam1360/YOLOv3-model-pruning https://mp.weixin.qq.com/s/qk2hWDSeYq36AeR9_GrOlw 这个版本的yolov3需要: numpy torch>=1.0 torchvision matplotlib tensorflow tensorboard terminalta
-
This repository represents Ultralytics open-source research into future object detection methods, and incorporates lessons learned and best practices evolved over thousands of hours of training and
-
MobileNetV2-YOLOv3-Nano的Darknet实现:移动终端设计的目标检测网络,计算量0.5BFlops!支持NCNN及MNN部署,华为P40在MNN开启ARM82情况下320分辨率输入,4核运算单次推理时间只有6ms!!!模型大小只有3MB
-
1.接口描述 对照片中的人脸进行检测,返回人脸数目和每张人脸的位置信息 图片要求 格式为 JPG(JPEG),BMP,PNG,GIF,TIFF 宽和高大于 8px,小于等于4000px 小于等于 5 MB 请求方式: POST 请求URL: https://cloudapi.linkface.cn/face/face_detect 2.请求参数 字段 类型 必需 描述 api_id string
-
问题内容: 我正在尝试在android上进行人脸检测,并且正在遵循指南http://www.richardnichols.net/2011/01/java- facial-recognition-haar-cascade-with-jjil- guide/ 但是在android上。当我做 尽管确切的代码使用netbeans代码返回了2张面孔,但pushAndReturn似乎只从Android图像上
-
调用人脸检测接口,返回人脸检测的结果 requestsyntax image = Image(uri="fds://cnbj2.fds.api.xiaomi.com/vision-test/test_img.jpg") detect_faces_request = DetectFacesRequest(image) faces_list = vision_client.analysis_faces