
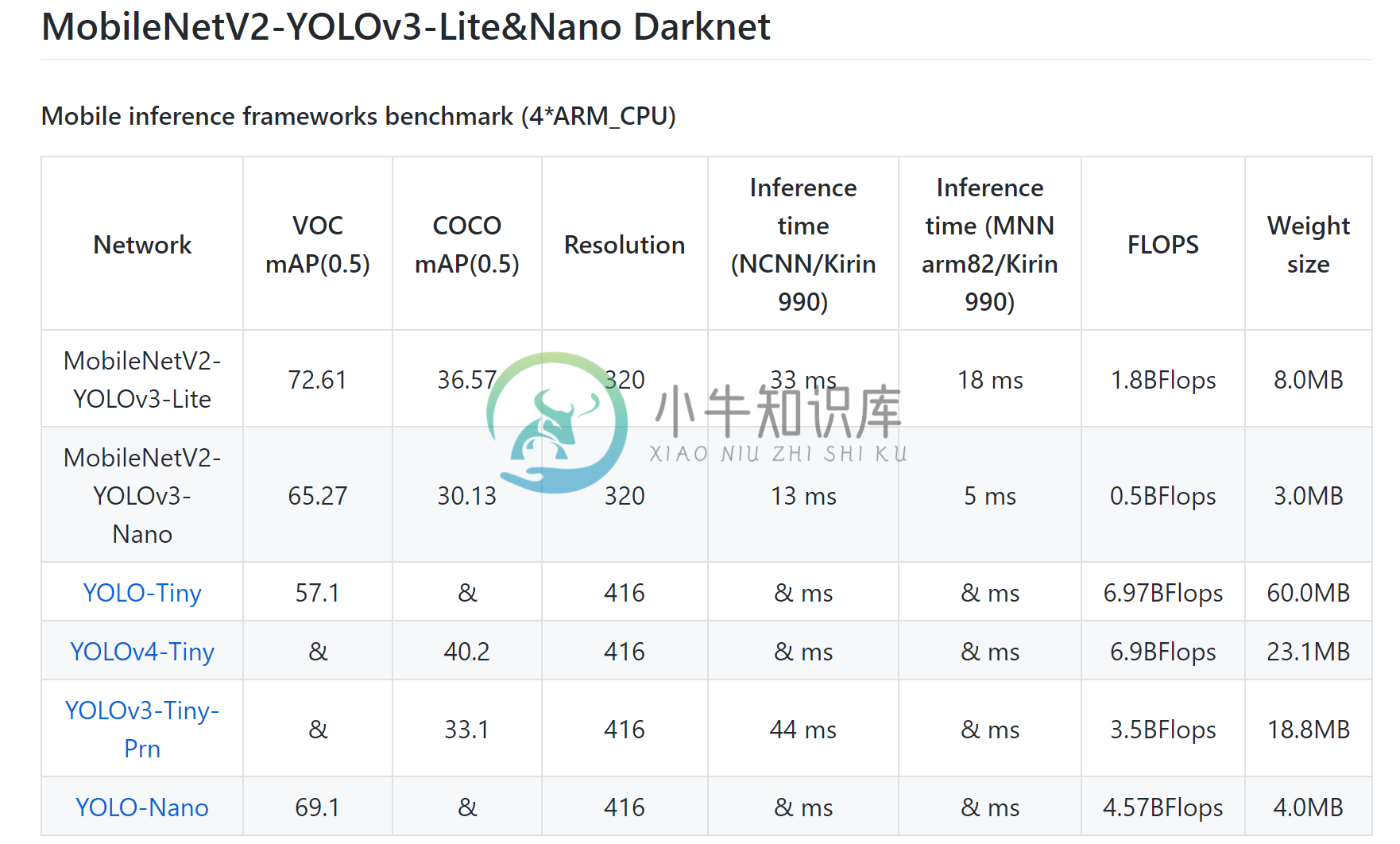
MobileNetV2-YOLOv3-Nano的Darknet实现:移动终端设计的目标检测网络,计算量0.5BFlops!支持NCNN及MNN部署,华为P40在MNN开启ARM82情况下320分辨率输入,4核运算单次推理时间只有6ms!!!模型大小只有3MB
-
编译&安装 # a fresh start $ sudo apt-get update $ sudo apt-get upgrade # install dependencies $ sudo apt-get install cmake wget $ sudo apt-get install libprotobuf-dev protobuf-compiler libvulkan-dev # dow
-
引言 这篇文档会介绍如何用 darknet 训练一个 YOLOv2 目标检测模型,看完这篇文档会发现:模型训练和预测都非常简单,最花时间的精力的往往是训练集的数据预处理。 这里先简单介绍一下 目标分类 (Classification) 和 目标检测 (Detection) 的区别?什么是 YOLO?以及什么是 darknet? 下面这张图很清晰地说明了目标分类: 一张图片作为输入,然后模型就会告诉
-
@subpage tutorial_py_face_detection_cn 人脸识别 使用 haar-cascades
-
在“锚框”一节中,我们在实验中以输入图像的每个像素为中心生成多个锚框。这些锚框是对输入图像不同区域的采样。然而,如果以图像每个像素为中心都生成锚框,很容易生成过多锚框而造成计算量过大。举个例子,假设输入图像的高和宽分别为561像素和728像素,如果以每个像素为中心生成5个不同形状的锚框,那么一张图像上则需要标注并预测200多万个锚框($561 \times 728 \times 5$)。 减少锚框
-
问题内容: 我有一个根视图控制器,没有将其设置为故事板上的任何视图控制器的自定义类。相反,我所有的视图控制器都将此类子类化。 但是,当在视图控制器上按下tabbaritem时,我似乎正在做某事,该控件是rootviewcontroller的子类,即消息未打印。 问题答案: 您不希望视图控制器的基类是UITabBarDelegate。如果要这样做,则所有视图控制器子类都将是标签栏委托。我认为您想要做
-
在前面的一些章节中,我们介绍了诸多用于图像分类的模型。在图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。 目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到