
Perf-Tools 是基于 的Linux性能分析调优工具集。Perf-Tools 依赖库少,使用简单。
支持Linux 3.2 及以上内核版本。
结构图:
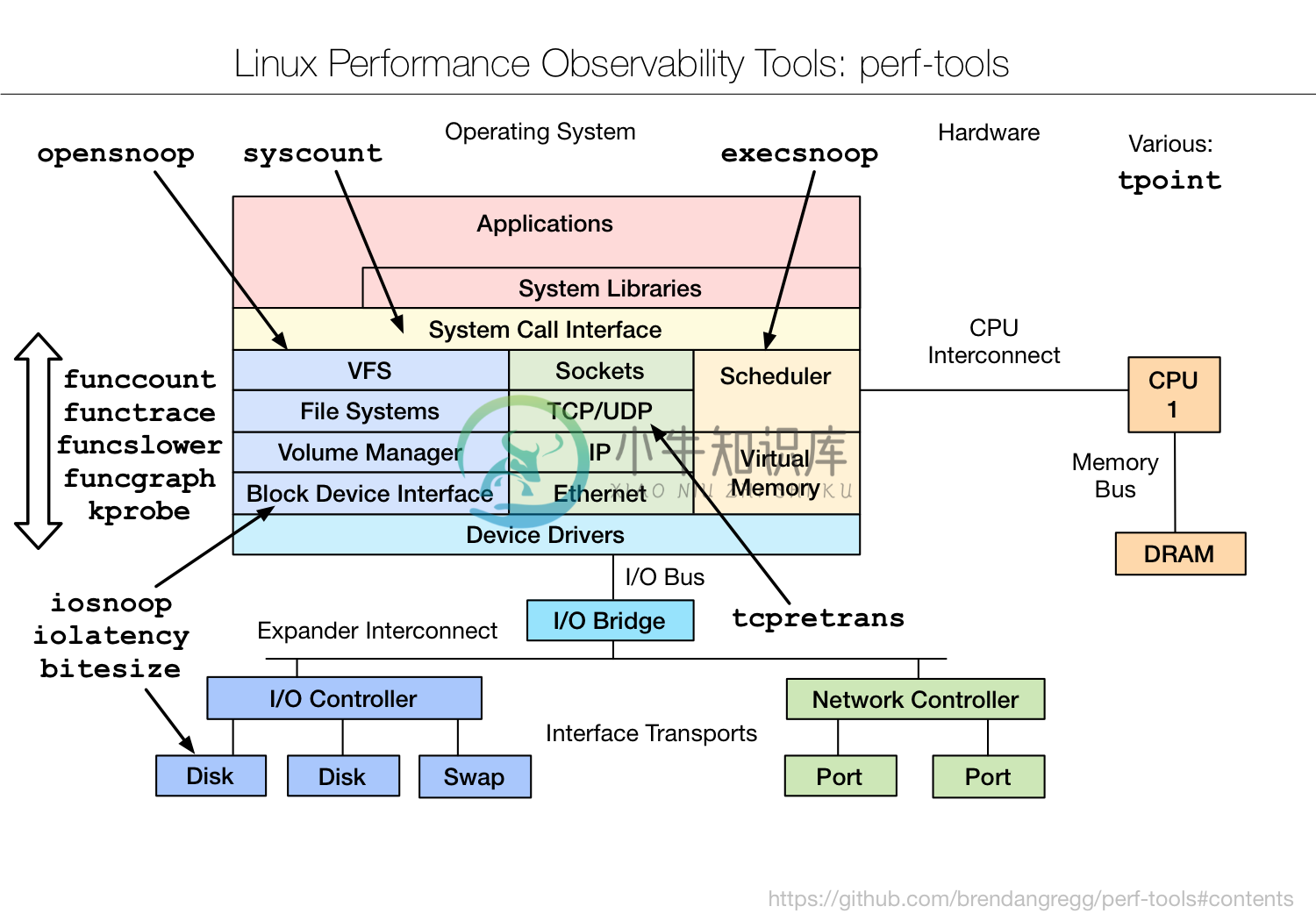
使用示例:
# ./execsnoop Tracing exec()s. Ctrl-C to end. PID PPID ARGS 22898 22004 man ls 22905 22898 preconv -e UTF-8 22908 22898 pager -s 22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8 22906 22898 tbl 22911 22910 locale charmap 22912 22907 groff -mtty-char -Tutf8 -mandoc -rLL=164n -rLT=164n 22913 22912 troff -mtty-char -mandoc -rLL=164n -rLT=164n -Tutf8 22914 22912 grotty
# ./tpoint -s block:block_rq_insert 'rwbs ~ "*R*"' cksum-11908 [000] d... 7269839.919098: block_rq_insert: 202,1 R 0 () 736560 + 136 [cksum] cksum-11908 [000] d... 7269839.919107: => __elv_add_request => blk_flush_plug_list => blk_finish_plug => __do_page_cache_readahead => ondemand_readahead => page_cache_async_readahead => generic_file_read_iter => new_sync_read => vfs_read => SyS_read => system_call_fastpath [...]
-
centos系统yum安装: sudo yum install perf 安装完成,键入perf查看可用选项。 但一般情况下,这样的安装完成后,普通用户下perf stat|top|record……并不能正常工作,提示 $ perf stat Error: You may not have permission to collect system-wide stats. Consider t
-
安装Perf 安装 perf 非常简单, 只要内核版本高于2.6.31的, perf已经被内核支持. 首先安装内核源码: apt-get install linux-source 那么在 /usr/src 目录下就已经下载好了内核源码, 我们对源码包进行解压, 然后进入 tools/perf 目录然后敲入下面两个命令即可: make make install 可能因为系统原因, 需要提前安装下
-
perf的使用场景 分析CPU cache、CPU迁移,分支预测、指令周期等各种硬件事件。 寻找程序运行过程中的热点函数,做性能分析,从而定位性能问题,具体的做法是对事件进行采样,然后再根据采样数,评估调用流程中各个函数的调用频率。 自定义追踪感兴趣的事件或者是函数。 限制:并不是所有/proc/kallsyms 内核符号中的函数都可以被跟踪!!! perf list 列出所有能够出发Perf采样
-
perf是由Linux Kernel提供的动态追踪调试工具,我们可以使用perf对运行时的程序进行分析 相比单纯依赖log,core进行离线排查,perf是一种在线的调试手段,可以在线上随时进行采样并进行分析,无需预先埋点,所带来的只是采样时间段内的一些性能损耗,这种特性使perf很适合于排查未知的问题 perf生成的运行时栈可以通过FlameGraph生成交互式的图表,可以更方便地分析热点 安
-
源码位置: kernel/tools/perf 配置内核以支持perf make xxx_defconfig make menuconfig 设置以下配置: CONFIG_HAVE_PERF_EVENTS=y CONFIG_PERF_USE_VMALLOC=y 编译perf工具 make CROSS_COMPILE=xxx ARCH=xxx defconfig make CROSS_COMPIL
-
perf是performance的简称,最常用的性能分析工具。一款随linux内核代码一同发布和维护的性能诊断工具。linux内核2.6.31加入performance Counter, 内核2.6.32改为performance Event。 跟随linux内核发布的perf是一个基于内核的子系统,它提供一个性能分析框架。其利用硬件(CPU、PMU(Perform
-
安装 通过编译安装 1. 源码在 kernel/tools/perf/ 目录下 2. make install 即可 3. perf top 验证一下 通过编译安装 vm工具 1. 源码在 kernel/tools/vm/ 目录下 2. make install 即可 3. slabtop 验证即可
-
如果经过之前章节的一系列优化之后,数据确实超过了集群能承载的能力,除了拆分集群以外,最后就只剩下一个办法了:清除废旧索引。 为了更加方便的做清除数据,合并 segment,备份恢复等管理任务,Elasticsearch 在提供相关 API 的同时,另外准备了一个命令行工具,叫 curator 。curator 是 Python 程序,可以直接通过 pypi 库安装: pip install ela
-
使用perf内核性能分析工具,可以分析出很多问题。具体参考perf命令的用法。 还有oprofile可以分析性能。mpstat查看cpu的使用分布。strace查看系统调用情况。参考:http://blog.csdn.net/win_lin/article/details/9377209
-
本文向大家介绍说一下 JVM 调优的工具?相关面试题,主要包含被问及说一下 JVM 调优的工具?时的应答技巧和注意事项,需要的朋友参考一下 JDK 自带了很多监控工具,都位于 JDK 的 bin 目录下,其中最常用的是 jconsole 和 jvisualvm 这两款视图监控工具。 jconsole:用于对 JVM 中的内存、线程和类等进行监控; jvisualvm:JDK 自带的全能分析工具,可
-
对于某些工作负载,可以在通过在内存中缓存数据或者打开一些实验选项来提高性能。 在内存中缓存数据 Spark SQL可以通过调用sqlContext.cacheTable("tableName")方法来缓存使用柱状格式的表。然后,Spark将会仅仅浏览需要的列并且自动地压缩数据以减少内存的使用以及垃圾回收的 压力。你可以通过调用sqlContext.uncacheTable("tableName")
-
集群中的Spark Streaming应用程序获得最好的性能需要一些调整。这章将介绍几个参数和配置,提高Spark Streaming应用程序的性能。你需要考虑两件事情: 高效地利用集群资源减少批数据的处理时间 设置正确的批容量(size),使数据的处理速度能够赶上数据的接收速度 减少批数据的执行时间 设置正确的批容量 内存调优
-
常用命令 1. 查看系统 CPU 总数 $ grep -c ^processor /proc/cpuinfo $ lscpu 2. 查看网卡信息,主机名 $ hostname $ ip addr show eth0 3. 查看系统上运行的服务 # systemctl list-units -t service | awk '$3=="active"' ** ** ** **
-
硬件因素 内存(RAM)的读写速度时普通 SSD 的 25 倍。MongoDB 中依赖 RAM 最多的操作包括:聚合、索引遍历、写操作、查询引擎、连接 Table 1. 常见存储的IOPS 类型 IOPS 7200 rpm SATA 75 - 100 15000 rpm SAS 175 - 210 SSD Intel X25-E(SLC) 5000 SSD Intel X25-M G2(MLC)
-
本文向大家介绍Hadoop性能调优?相关面试题,主要包含被问及Hadoop性能调优?时的应答技巧和注意事项,需要的朋友参考一下 调优可以通过系统配置、程序编写和作业调度算法来进行。 hdfs的block.size可以调到128/256(网络很好的情况下,默认为64) 调优的大头:mapred.map.tasks、mapred.reduce.tasks设置mr任务数(默认都是1) mapred.ta