
ASRT 是一个基于深度学习的中文语音识别系统,全称为 Auto Speech Recognition Tool。此项目使用 Keras、TensorFlow,基于深度卷积神经网络和长短时记忆神经网络、注意力机制以及 CTC 实现。
ASRT 项目的声学模型通过采用卷积神经网络(CNN)和连接性时序分类(CTC)方法,使用大量中文语音数据集进行训练,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本。
系统运行流程
- 特征提取:将普通的wav语音信号通过分帧加窗等操作转换为神经网络需要的二维频谱图像信号,即语谱图。

- 声学模型:基于Keras和TensorFlow框架,使用这种参考了VGG的深层的卷积神经网络作为网络模型,并训练。

- CTC解码:在语音识别系统的声学模型的输出中,往往包含了大量连续重复的符号,因此,我们需要将连续相同的符合合并为同一个符号,然后再去除静音分隔标记符,得到最终实际的语音拼音符号序列。
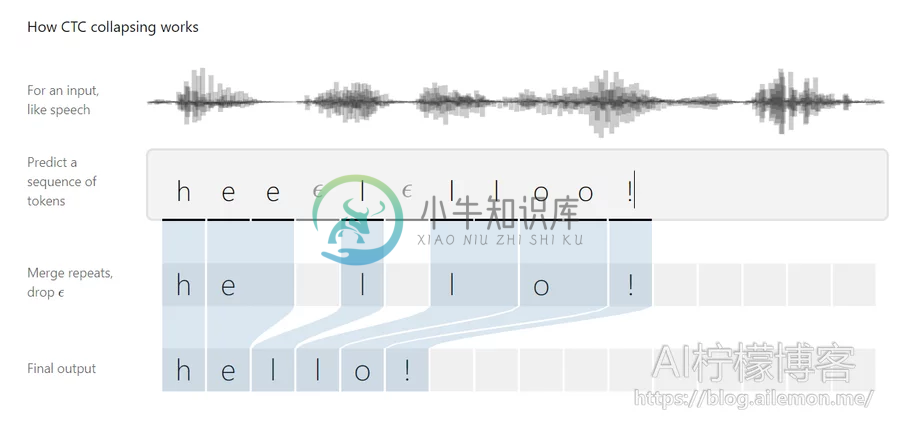
- 语言模型:使用统计语言模型,将拼音转换为最终的识别文本并输出。拼音转文本的本质被建模为一条隐含马尔可夫链,这种模型有着很高的准确率。(其原理请看:https://blog.ailemon.net/2017/04/27/statistical-language-model-chinese-pinyin-to-words/)
-
ASRT语音识别系统部署及模型训练笔记 前言 ASRT是一个中文语音识别系统,由AI柠檬博主开源在GitHub上。 GitHub地址:ASRT_SpeechRecognition 国内Gitee镜像地址:ASRT_SpeechRecognition 文档地址:ASRT语音识别工具文档 本文主要是记录一下我在参考文章:教你如何使用ASRT训练中文语音识别模型 并完成部署和训练过程中的操作步骤。文章作
-
请记住标红的永远是最重要的,就够了,这两个版本不对类似也白搭, python版本是3.6 conda env list conda create -n voice conda activate voice conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda conf
-
ASRT_SpeechRecognition 基于深度学习的语音识别系统 Introduction 简介 本项目使用Keras、TensorFlow基于长短时记忆神经网络和卷积神经网络以及CTC进行制作。 This project uses keras, TensorFlow based on LSTM, CNN and CTC to implement. 本项目目前已经可以正常进行训练了。 通过
-
######DeepSpeech(tensorflow)###### pip3 install deepspeech wget https://github.com/mozilla/DeepSpeech/releases/download/v0.9.3/deepspeech-0.9.3-models-zh-CN.pbmm wget https://github.com/mozilla/DeepSp
-
SpeechModel251_p.py if(__name__=='__main__'): import tensorflow as tf from keras.backend.tensorflow_backend import set_session #os.environ["CUDA_VISIBLE_DEVICES"] = "0,1" #进行配置,
-
测试代码 #!/usr/bin/env python3 # -*- coding: utf-8 -*- # # Copyright 2016-2099 Ailemon.net # # This file is part of ASRT Speech Recognition Tool. # # ASRT is free software: you can redistribute it and/
-
demo整合了AI柠檬的SDK例程和golang 调用winmm.dll 实现windows系统下录音的例程;该例程提供了windows系统下录音到访问ASRT 服务器实现语音识别的思路。 注:golang 调用winmm.dll 的例程 ,也参考了AI柠檬作者C# 例程“C#基于winmm实现录音功能” package main import ( "fmt" "log" "syscall
-
我想构建一个android应用程序,它可以识别我的声音,将其转换为文本,并显示我刚才在祝酒词中所说的内容。我可以通过使用一个按钮来完成这项工作,该按钮将为我启动语音识别器。但现在我想让它只在我的声音的基础上工作。 应用程序应触发语音识别器,仅当我开始说话时才开始听我说话,当它感觉到沉默时应停止听我说话。就像会说话的tom应用程序的功能一样。它记录了声音,但我想用语音识别器识别它。像这样的事情: 主
-
使用慧编程的机器学习功能可以实现人脸识别,当识别到“女士”,广播消息“笑”并等待,光环板接收到广播消息,露出笑脸,否则,广播消息“生气”并等待,光环板亮红灯。此功能可应用于智能家居系统,当识别到主人回家时,大门自动打开,当识别到陌生人时,开启警铃。 训练模型 1. 选择“角色”,点击积木区下方的“+”,添加扩展“机器学习”。 2. 选中机器学习积木,点击“训练模型”,在训练模型界面点击“新建模型”
-
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
-
本文向大家介绍除了GMM-HMM,你了解深度学习在语音识别中的应用吗?相关面试题,主要包含被问及除了GMM-HMM,你了解深度学习在语音识别中的应用吗?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 讲了我用的过DNN-HMM,以及与GMM-HMM的联系与区别;然后RNN+CTC,这里我只是了解,大概讲了一下CTC损失的原理;然后提了一下CNN+LSTM。
-
我想在phonegap中创建应用程序,在Android和IOS中使用连续语音识别。我的应用程序应该等待用户的声音,当他/她说“下一步”时,应用程序应该更新屏幕并执行一些操作。 我发现这个插件:https://github.com/macdonst/SpeechRecognitionPlugin而且它工作得非常快。但在语音识别启动几秒钟后,语音识别器停止工作,但并没有语音。是否有任何方法或标志,如i
-
Keras 是一个高层神经网络 API,Keras 由纯 Python 编写而成并基 Tensorflow、Theano 以及 CNTK 后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择 Keras: 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性) 支持 CNN 和 RNN,或二者的结合 无缝 CPU 和 GPU 切换 Kera
-
停止更新通知 Hi all,十分感谢大家对keras-cn的支持,本文档从我读书的时候开始维护,到现在已经快两年了。这个过程中我通过翻译文档,为同学们debug和答疑学到了很多东西,也很开心能帮到一些同学。 从2017年我工作以后,由于工作比较繁忙,更新频率有所下降。到今年早期的时候这种情况更加严重,加之我了解到,keras官方已经出了中文文档,更觉本份文档似乎应该已经基本完成了其历史使命,该到了
-
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。