
去年,做了几个JFinal项目,大量使用了Java爬虫去全网抓取数据,清洗筛选后入库,成为本地结构化数据。
Java中JSOUP做HTML解析是最好的工具,没有之一。
之前听过一句话,大体意思就是
我们所能访问的网页本身就是一个数据宝藏,天然的对外数据接口。
只要我们能拿到网页的Html代码,就可以拿到网站的公开数据。
利用JSoup针对直接加载显示数据的网页,也可以轻松拿到Html代码,后面的操作类似JQuery的API,有这类似的DOM操作形式。
还可以扩展爬虫的能力,分布式,多线程,异步,定时任务执行,总之,了解和核心使用方法,剩下的都是怎么玩儿的事儿了!
项目视频演示地址:
https://www.bilibili.com/video/av54760586
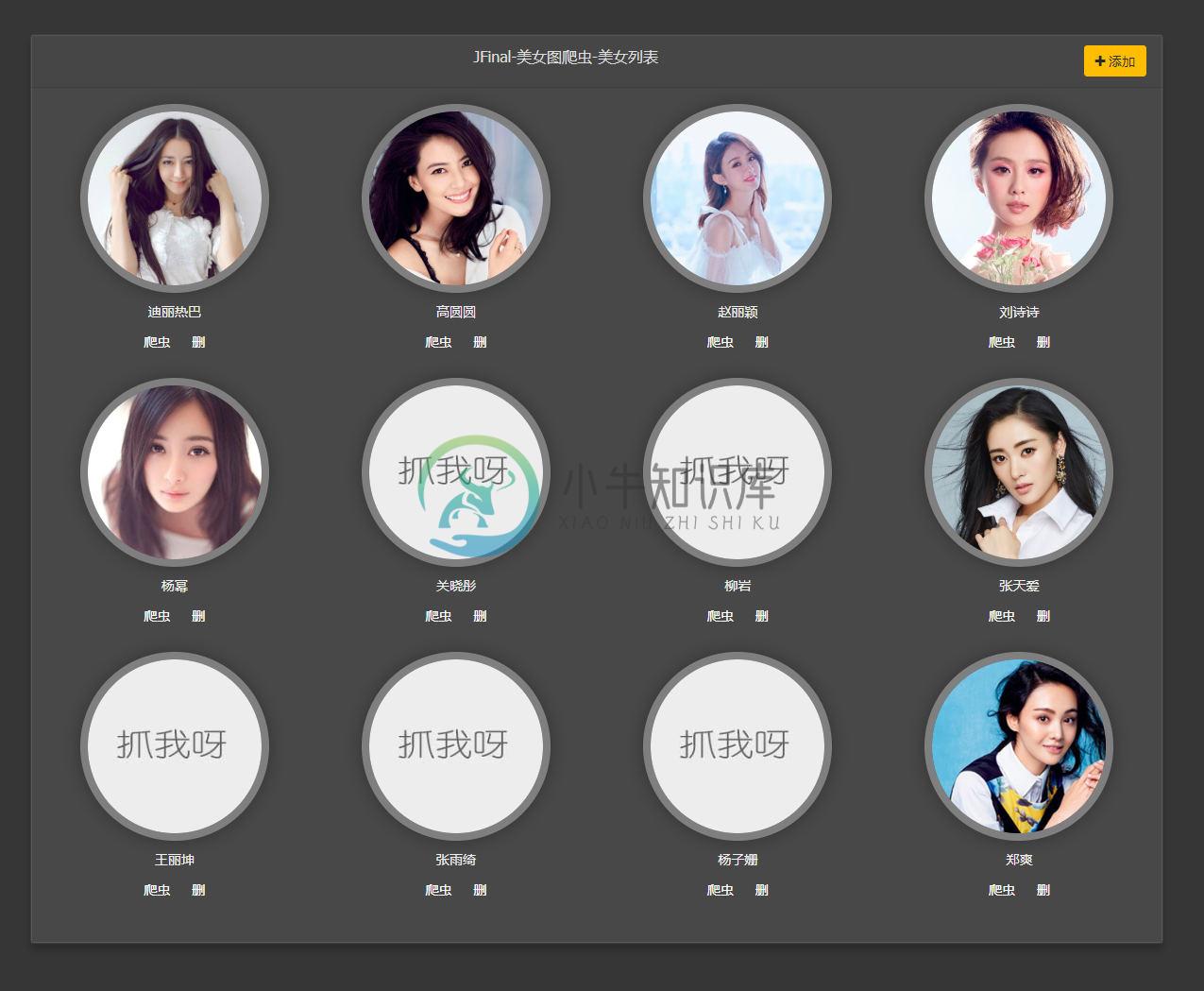
项目截图:
1、首页
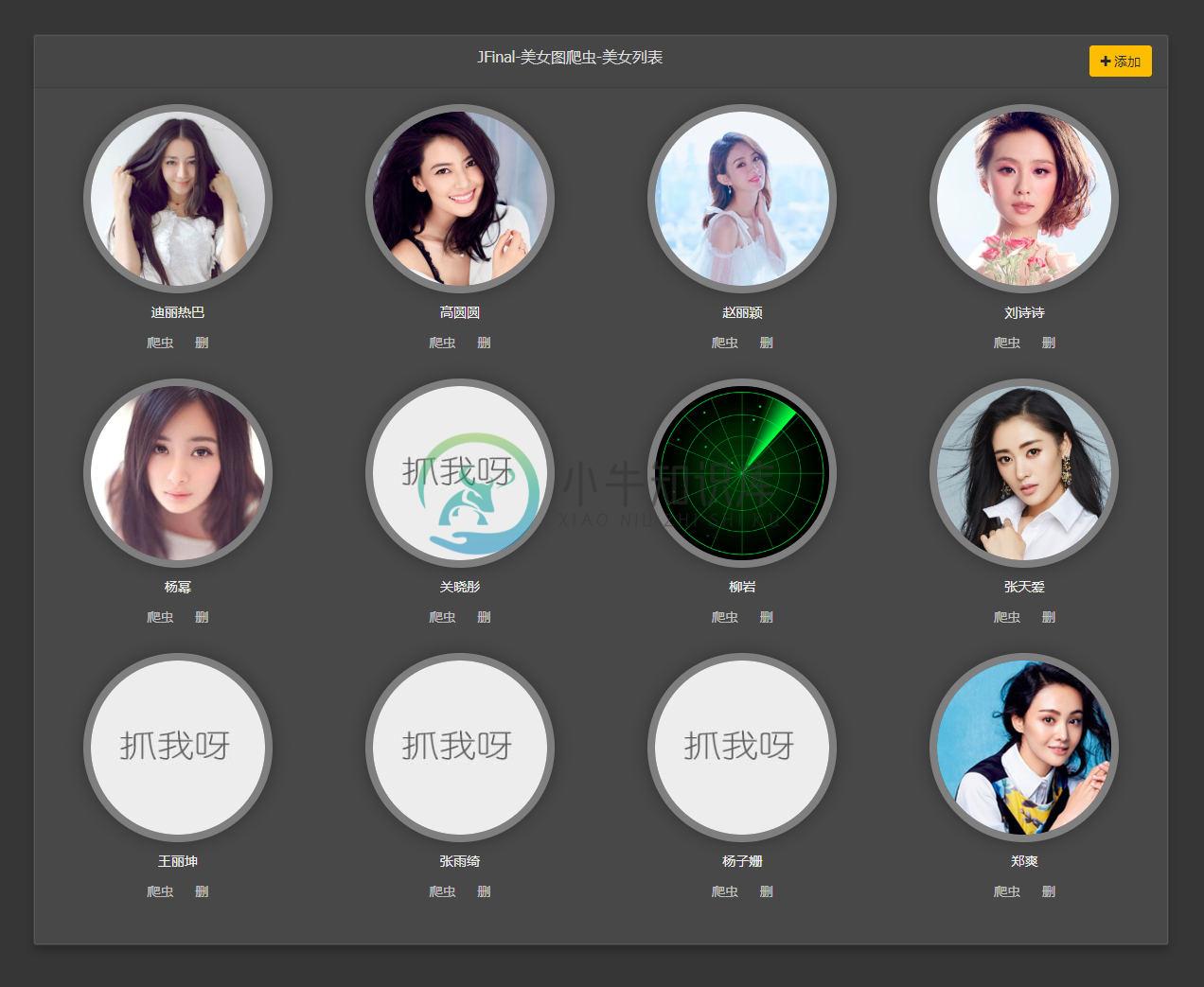
2、启动爬虫,雷达扫描
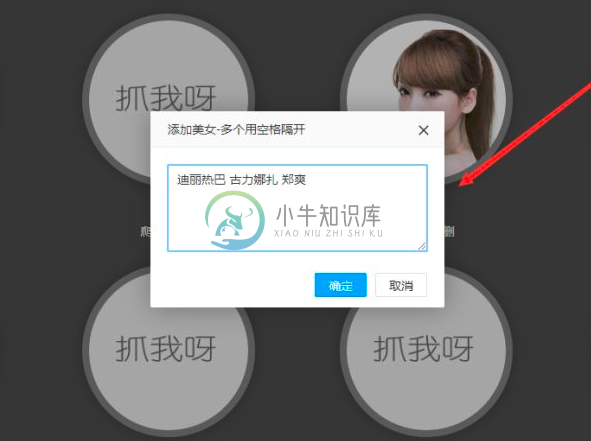
3、添加明星
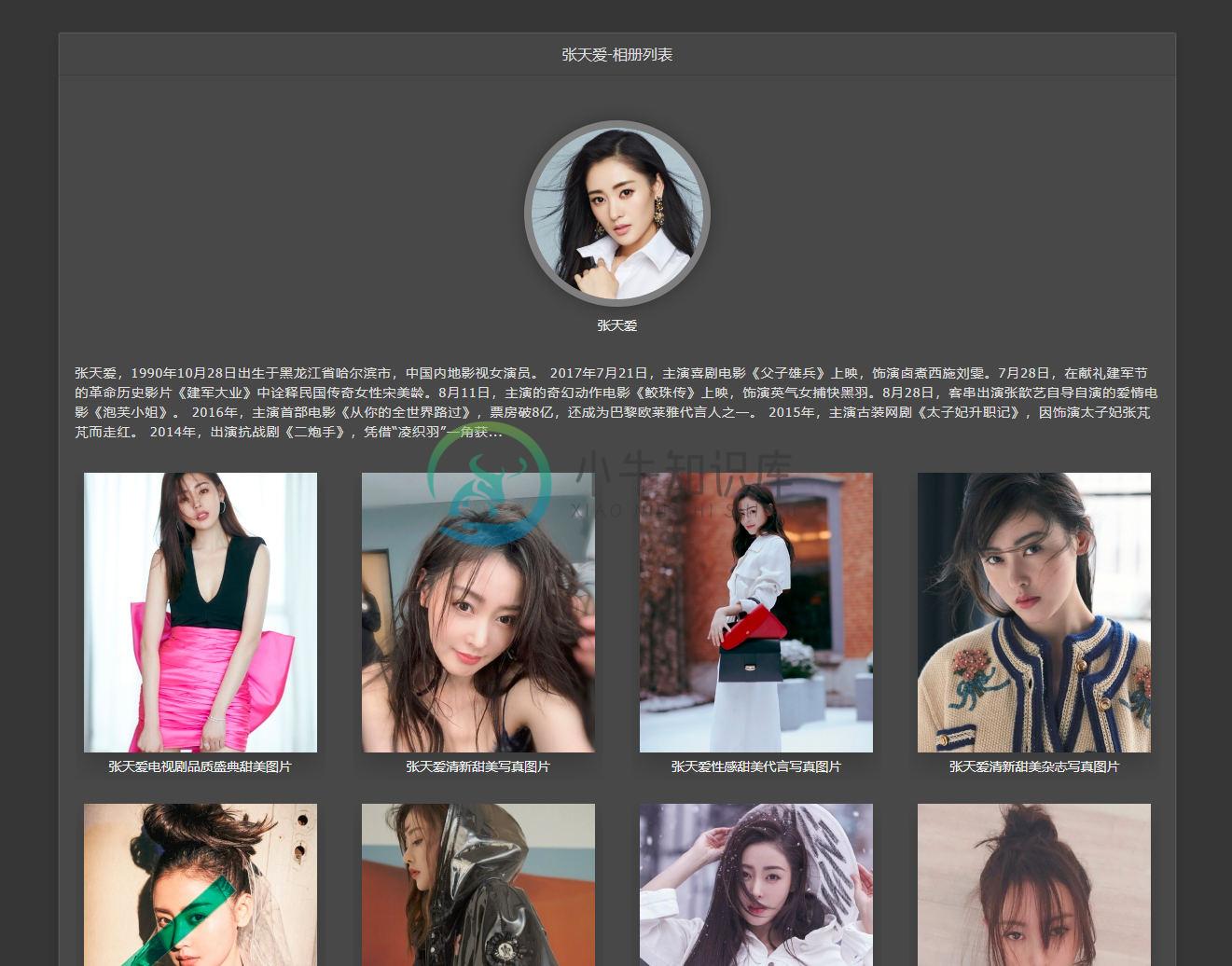
4、相册主页
5、相册里的照片
6、幻灯片播放

7、大图单页

代码使用技术
-
package jousp; import java.io.ByteArrayOutputStream; import java.io.File; import java.io.FileOutputStream; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; import
-
for(Blog blog:blogList){ List<String> imagesList=blog.getImagesList(); String blogInfo=blog.getContent(); Document doc=Jsoup.parse(blogInfo); Elements jpgs=doc.select("img[src$=.jpg]"); //
-
JSOUP乱码情况产生 这几天我用 JSOUP 多线程的方式,爬取了200 多万数据,数据为各地的地名相关。结果有小部分数据,不到 1 万乱码。我先检查了我的编码为UTF-8 ,觉得应该没有问题。代码基本如下如下: try{ doc = Jsoup.connect(url) .header("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64
-
前言 最近在写爬虫玩,爬虫写完后整理了如下笔记,以后说不定用到上。 其实java.net包下的也可以用,但是为了简单,而且有封装好的Jsoup库库用,效率更高。 一、工具 1.Jsoup jsoup is a Java library for working with real-world HTML. It provides a very convenient API for fetching U
-
jsoup 是一款基于Java 的HTML解析器,可直接解析某个URL地址或HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。 jsoup的强大在于它对文档元素的检索,Select方法将返回一个Elements集合,并提供一组方法来抽取和处理结果,要掌握Jsoup首先要熟悉它的选择器语法。 1、Selector选择器基本语法 ta
-
本文向大家介绍Java 爬虫工具Jsoup详解,包括了Java 爬虫工具Jsoup详解的使用技巧和注意事项,需要的朋友参考一下 Java 爬虫工具Jsoup详解 Jsoup是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。 jsoup 的主要功能如
-
本文向大家介绍php实现简单爬虫的开发,包括了php实现简单爬虫的开发的使用技巧和注意事项,需要的朋友参考一下 有时候因为工作、自身的需求,我们都会去浏览不同网站去获取我们需要的数据,于是爬虫应运而生,下面是我在开发一个简单爬虫的经过与遇到的问题。 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照
-
前面的学习中我们已经简单了解了一些爬虫所需的知识,这节课我们就来做一个小爬虫来实践下我们前面所学习的知识,这节课我们会爬取慕课网首页所有的课程名称: 1. 爬取慕课网首页所有课程名称 我们第一个爬虫程序,是来爬取慕课网的首页的所有课程信息的名字。下面的代码锁使用到的技术有的我们并没有涉及到,后面的学习中我们会一一讲解。这里只是让大家对爬虫程序有个大概的了解,熟悉最基本的爬虫流程,以及对爬虫处理有一
-
Xpath( XML Path Language, XML路径语言),是一种在 XML 数据中查找信息的语言,现在,我们也可以使用它在 HTML 中查找需要的信息。 既然谈到 Xpath 是一门语言,当然它就会有自己的一些特定的语法。我们这里罗列一些经常使用的语法,熟悉下面的基本语法之后,就能满足我们日常的爬虫开发所用。 本小节主要内容: Xpath的基本概念 Xpath的基本语法 Xpath实战
-
本文向大家介绍Java爬虫Jsoup+httpclient获取动态生成的数据,包括了Java爬虫Jsoup+httpclient获取动态生成的数据的使用技巧和注意事项,需要的朋友参考一下 Java爬虫Jsoup+httpclient获取动态生成的数据 前面我们详细讲了一下Jsoup发现这玩意其实也就那样,只要是可以访问到的静态资源页面都可以直接用他来获取你所需要的数据,详情情跳转-Jsoup爬虫详
-
本文向大家介绍使用 Node.js 开发资讯爬虫流程,包括了使用 Node.js 开发资讯爬虫流程的使用技巧和注意事项,需要的朋友参考一下 最近项目需要一些资讯,因为项目是用 Node.js 来写的,所以就自然地用 Node.js 来写爬虫了 项目地址:github.com/mrtanweijie… ,项目里面爬取了 Readhub 、 开源中国 、 开发者头条 、 36Kr 这几个网站的资讯内容
-
Im很难通过HTTPS获得java提交POST请求 编辑: 当服务器通过HTTPS获得一个POST时,似乎涉及到302重定向(这在http上不会发生),我如何使用jsoup存储与302一起发送到下一页的cookie呢?
-
本文向大家介绍PHP+HTML+JavaScript+Css实现简单爬虫开发,包括了PHP+HTML+JavaScript+Css实现简单爬虫开发的使用技巧和注意事项,需要的朋友参考一下 开发一个爬虫,首先你要知道你的这个爬虫是要用来做什么的。我是要用来去不同网站找特定关键字的文章,并获取它的链接,以便我快速阅读。 按照个人习惯,我首先要写一个界面,理清下思路。 1、去不同网站。那么我们需