
Android开发之利用jsoup解析HTML页面的方法

本文实例讲述了Android利用jsoup解析HTML页面的方法。分享给大家供大家参考,具体如下:
这节主要是讲解jsoup解析HTML页面。由于在android开发过程中,不可避免的涉及到web页面的抓取,解析,展示等等,所以,在这里我主要展示下利用jsoup jar包来抓取cnbeta.com网站的话题分类的实例。
下面是主要的代码,由于使用及其简单,我这里就不再多说了:
package com.android.web;
import java.io.BufferedInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.http.util.ByteArrayBuffer;
import org.apache.http.util.EncodingUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import android.app.Activity;
import android.os.Bundle;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.ListView;
import android.widget.SimpleAdapter;
public class _GetWebResoureActivity extends Activity {
Document doc;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
findViewById(R.id.button1).setOnClickListener(new OnClickListener() {
@Override
public void onClick(View v) {
load();
}
});
}
protected void load() {
try {
doc = Jsoup.parse(new URL("http://www.cnbeta.com"), 5000);
} catch (MalformedURLException e1) {
e1.printStackTrace();
} catch (IOException e1) {
e1.printStackTrace();
}
List<Map<String, String>> list = new ArrayList<Map<String, String>>();
Elements es = doc.getElementsByClass("main_navi");
for (Element e : es) {
Map<String, String> map = new HashMap<String, String>();
map.put("title", e.getElementsByTag("a").text());
map.put("href", "http://www.cnbeta.com"
+ e.getElementsByTag("a").attr("href"));
list.add(map);
}
ListView listView = (ListView) findViewById(R.id.listView1);
listView.setAdapter(new SimpleAdapter(this, list, android.R.layout.simple_list_item_2,
new String[] { "title","href" }, new int[] {
android.R.id.text1,android.R.id.text2
}));
}
/**
* @param urlString
* @return
*/
public String getHtmlString(String urlString) {
try {
URL url = null;
url = new URL(urlString);
URLConnection ucon = null;
ucon = url.openConnection();
InputStream instr = null;
instr = ucon.getInputStream();
BufferedInputStream bis = new BufferedInputStream(instr);
ByteArrayBuffer baf = new ByteArrayBuffer(500);
int current = 0;
while ((current = bis.read()) != -1) {
baf.append((byte) current);
}
return EncodingUtils.getString(baf.toByteArray(), "gbk");
} catch (Exception e) {
return "";
}
}
}
注意代码:Elements es = doc.getElementsByClass("main_navi");一定要找对位置,才能得到正确的结果。下面就是主要的预览效果:
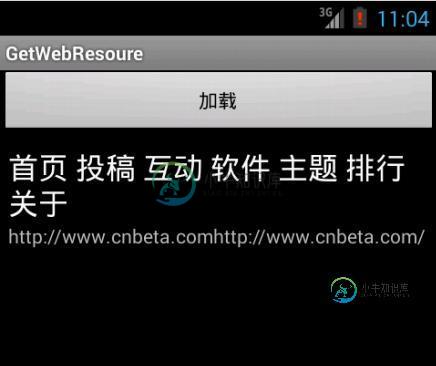
更多关于Android相关内容感兴趣的读者可查看本站专题:《Android调试技巧与常见问题解决方法汇总》、《Android开发入门与进阶教程》、《Android多媒体操作技巧汇总(音频,视频,录音等)》、《Android基本组件用法总结》、《Android视图View技巧总结》、《Android布局layout技巧总结》及《Android控件用法总结》
希望本文所述对大家Android程序设计有所帮助。
-
我需要的是在第二个中获取第二个 的文本,并对表中的每一组 标记执行此操作。
-
本文向大家介绍Android使用Jsoup解析Html表格的方法,包括了Android使用Jsoup解析Html表格的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Android使用Jsoup解析Html表格的方法。分享给大家供大家参考,具体如下: 看代码吧,可解析表中的label text button 自己根据需要再添加,呵呵 希望本文所述对大家Android程序设计有所帮助。
-
我想解析出这个Nasa页面上的描述,页面底部的文字 我该怎么做?
-
主要内容:Jsoup 使用DOM解析HTML 语法,Jsoup 使用DOM解析HTML 说明,Jsoup 使用DOM解析HTML 示例以下示例将展示在将 HTML 字符串解析为 Document 对象后如何使用类似 DOM 的方法。 Jsoup 使用DOM解析HTML 语法 document : 文档对象代表 HTML DOM。 Jsoup : 解析给定 HTML 字符串的主类。 html : HTML 字符串。 sampleDiv : 元素对象表示由 id“sampleDiv”标识的 html
-
http://www.argenteam.net/movie/40749/American.Reunion.%282012%29 我正在尝试使用JSOUP获得该页面上的所有类似于这样的链接: 问题是我无法获得这种链接。做了一些极端的事情,我尝试了下面的代码来获得页面上的所有链接,但是这个“a[href]”再次出现在列表中。 最终编辑与解决方案: 该网站请求一个cookie来显示我需要的链接,因为这
-
主要内容:Jsoup 解析HTML正文 语法,Jsoup 解析HTML正文 说明,Jsoup 解析HTML正文 示例以下示例将展示将 HTML 片段字符串解析为 Element 对象作为 html 正文。 Jsoup 解析HTML正文 语法 document : 文档对象代表 HTML DOM。 Jsoup : 解析给定 HTML 字符串的主类。 html : HTML 片段字符串。 body : 表示文档正文元素的子元素,等效于 document.getElementsByTag("body"