
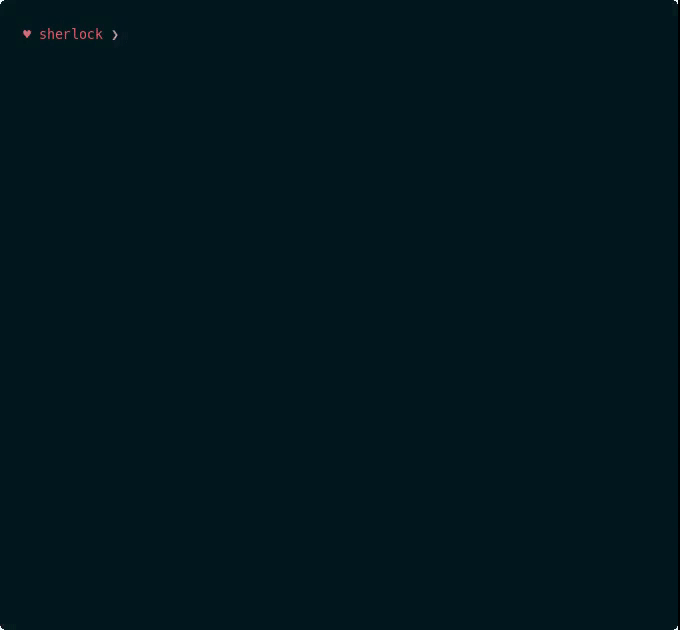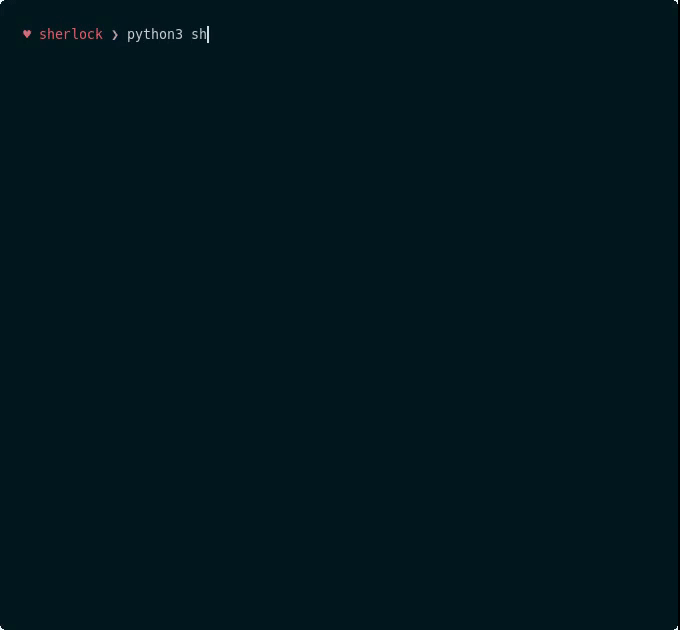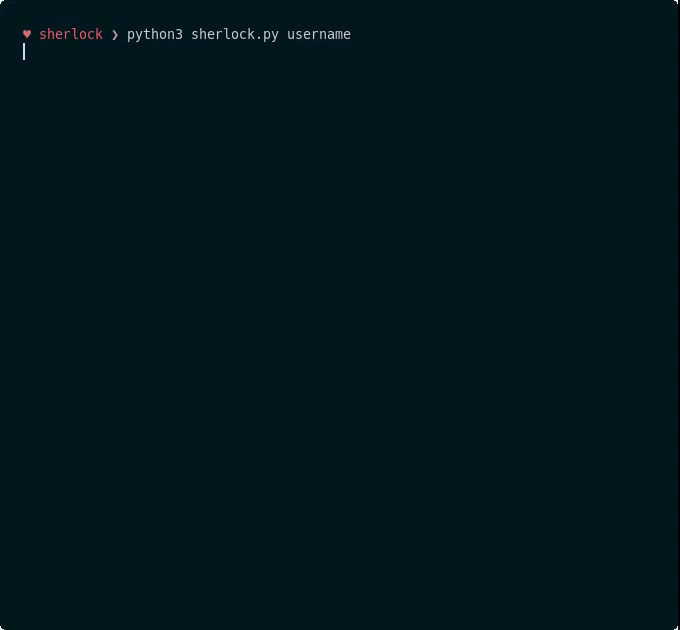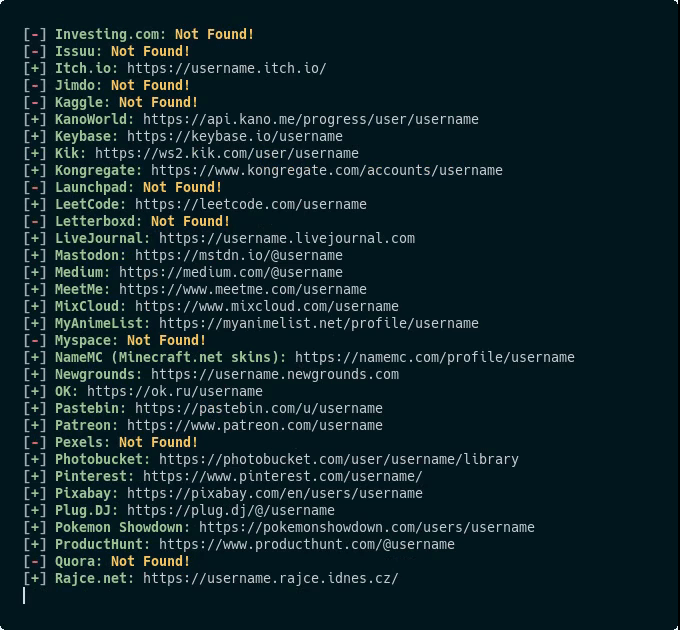
Sherlock 是一款网络爬虫工具,可根据输入的用户名爬取对应的社交帐号,目前支持 300 多个不同社交平台。
用法
$ python3 sherlock --help
usage: sherlock [-h] [--version] [--verbose] [--folderoutput FOLDEROUTPUT]
[--output OUTPUT] [--tor] [--unique-tor] [--csv]
[--site SITE_NAME] [--proxy PROXY_URL] [--json JSON_FILE]
[--timeout TIMEOUT] [--print-all] [--print-found] [--no-color]
[--browse] [--local]
USERNAMES [USERNAMES ...]
Sherlock: Find Usernames Across Social Networks (Version 0.14.0)
positional arguments:
USERNAMES One or more usernames to check with social networks.
optional arguments:
-h, --help show this help message and exit
--version Display version information and dependencies.
--verbose, -v, -d, --debug
Display extra debugging information and metrics.
--folderoutput FOLDEROUTPUT, -fo FOLDEROUTPUT
If using multiple usernames, the output of the results
will be saved to this folder.
--output OUTPUT, -o OUTPUT
If using single username, the output of the result
will be saved to this file.
--tor, -t Make requests over Tor; increases runtime; requires
Tor to be installed and in system path.
--unique-tor, -u Make requests over Tor with new Tor circuit after each
request; increases runtime; requires Tor to be
installed and in system path.
--csv Create Comma-Separated Values (CSV) File.
--site SITE_NAME Limit analysis to just the listed sites. Add multiple
options to specify more than one site.
--proxy PROXY_URL, -p PROXY_URL
Make requests over a proxy. e.g.
socks5://127.0.0.1:1080
--json JSON_FILE, -j JSON_FILE
Load data from a JSON file or an online, valid, JSON
file.
--timeout TIMEOUT Time (in seconds) to wait for response to requests.
Default timeout is infinity. A longer timeout will be
more likely to get results from slow sites. On the
other hand, this may cause a long delay to gather all
results.
--print-all Output sites where the username was not found.
--print-found Output sites where the username was found.
--no-color Don't color terminal output
--browse, -b Browse to all results on default browser.
--local, -l Force the use of the local data.json file.-
社交网络的一大特征就是用户间的相互关注,从而形成朋友圈或媒体圈,实现便捷的信息分享和传播。GitHub支持项目级别及用户级别的关注。 关注一个项目很简单,只需点击项目名称右侧的“Watch”按钮。 图2-27:项目的关注按钮 添加对项目的关注后,点击页面左上角的“github”文字图标进入仪表板(Dashboard)页面,如图2-28所示。 图2-28:关注项目在仪表板页的显示 仪表板页面的左侧显
-
在本章中,让我们研究一下Drupal中的Social Networking 。 社交媒体现在变得非常重要,Drupal为此目的有许多社交媒体模块。 我们以ShareThis模块为例,您可以选择其他任何选择。 以下是用于安装ShareThis模块的简单步骤。 Step 1 - 单击ShareThis以访问ShareThis模块页面,然后单击Version ,如以下屏幕所示。 Step 2 - 复制模
-
我的状态帖子有以下数据库设置。对于每一篇文章,用户可以喜欢这篇文章,评论这篇文章,甚至可以由作者在原始文章中添加标签。 我试图设置我的足智多谋的控制器后带回所有的数据通过JSON对象,但我不能正确地找到评论,喜欢或标记用户名。如果有区别的话,我会用哨兵2进行认证。 以下是数据库设置: 我的Post控制器,我只是有一个简单的页面,可以显示所有内容。我不想循环查看文件中的任何内容,我只想返回json完
-
本文向大家介绍WordPress 启用最受欢迎的社交网络,包括了WordPress 启用最受欢迎的社交网络的使用技巧和注意事项,需要的朋友参考一下 示例 您将在仪表板中获得以下文件: 这就是您在代码中检索它的方式
-
主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
案例:爬取百度新闻首页的新闻标题信息 url地址:http://news.baidu.com/ 具体实现步骤: 导入urlib库和re正则 使用urllib.request.Request()创建request请求对象 使用urllib.request.urlopen执行信息爬取,并返回Response对象 使用read()读取信息,使用decode()执行解码 使用re正则解析结果 遍历输出结果
-
5.1 网络爬虫概述: 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下集中类型: 通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。 聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。 增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费
-
图片来源于网络 1. 爬虫的定义 网络爬虫(又称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。—— 百度百科定义 详细定义参照 慕课网注解: 爬虫其实是一种自动化信息采集程序或脚本,可以方便的帮助大家获得自己想要的特定信息。比如说,像百度,谷歌等搜索引擎