
DeepFlow 是一款面向云原生开发者的高度自动化的可观测性平台。使用 eBPF、WASM、OpenTelemetry 等新技术,DeepFlow 创新地实现了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,极大的避免了埋点插码,显著的降低了后端数仓的资源开销。基于 DeepFlow 的可编程性和开放接口,开发者可以快速将其融入到自己的可观测性技术栈中。
主要特性
- 全栈:DeepFlow 使用 eBPF 和 cBPF 技术实现的 AutoMetrics 机制,可以自动采集任何应用的 RED(Request、Error、Delay)性能指标,精细至每一次应用调用,覆盖从应用到基础设施的所有软件技术栈。在云原生环境中,DeepFlow 的 AutoTagging 机制自动发现服务、实例、API 的属性信息,自动为每个观测数据注入丰富的标签,从而消除数据孤岛,并释放数据的下钻能力。
- 全链路:DeepFlow 使用 eBPF 技术创新的实现了 AutoTracing 机制,在云原生环境中自动追踪任意微服务、基础设施服务的分布式调用链。在此基础上,通过集成并自动关联来自 OpenTelemetry 的数据,DeepFlow 实现了完整的全栈、全链路分布式追踪,消除了所有盲点。
- 高性能:DeepFlow 创新的 SmartEncoding 标签注入机制,能够将数据存储性能提升 10 倍,从此告别高基数和采样的焦虑。DeepFlow 使用 Rust 实现 Agent,拥有极致处理性能的同时保证内存安全。DeepFlow 使用 Golang 实现 Server,重写了 Golang 的 map、pool 基础库,数据查询和内存 GC 均有近 10 倍的性能提升。
- 可编程:DeepFlow 目前支持了对 HTTP(S)、Dubbo、MySQL、PostgreSQL、Redis、Kafka、MQTT、DNS 协议的解析,并将保持迭代增加更多的应用协议支持。除此之外,DeepFlow 基于 WASM 技术提供了可编程接口,让开发者可以快速具备对私有协议的解析能力,并可用于构建特定场景的业务分析能力,例如 5GC 信令分析、金融交易分析、车机通信分析等。
- 开放接口:DeepFlow 拥抱开源社区,支持接收广泛的可观测数据源,并利用 AutoTagging 和 SmartEncoding 提供高性能、统一的标签注入能力。DeepFlow 支持插件式的数据库接口,开发者可自由增加和替换最合适的数据库。DeepFlow 为所有观测数据提供统一的标准 SQL 查询能力,便于使用者快速集成到自己的可观测性平台中。
- 易于维护:DeepFlow 的内核仅由 Agent、Server 两个组件构成,将复杂度隐藏在进程内部,将维护难度降低至极致。DeepFlow Server 集群可对多个 Kubernetes 集群、传统服务器集群、云服务器集群进行统一监控,且无需依赖任何外部组件即可实现水平扩展与负载均衡。
架构
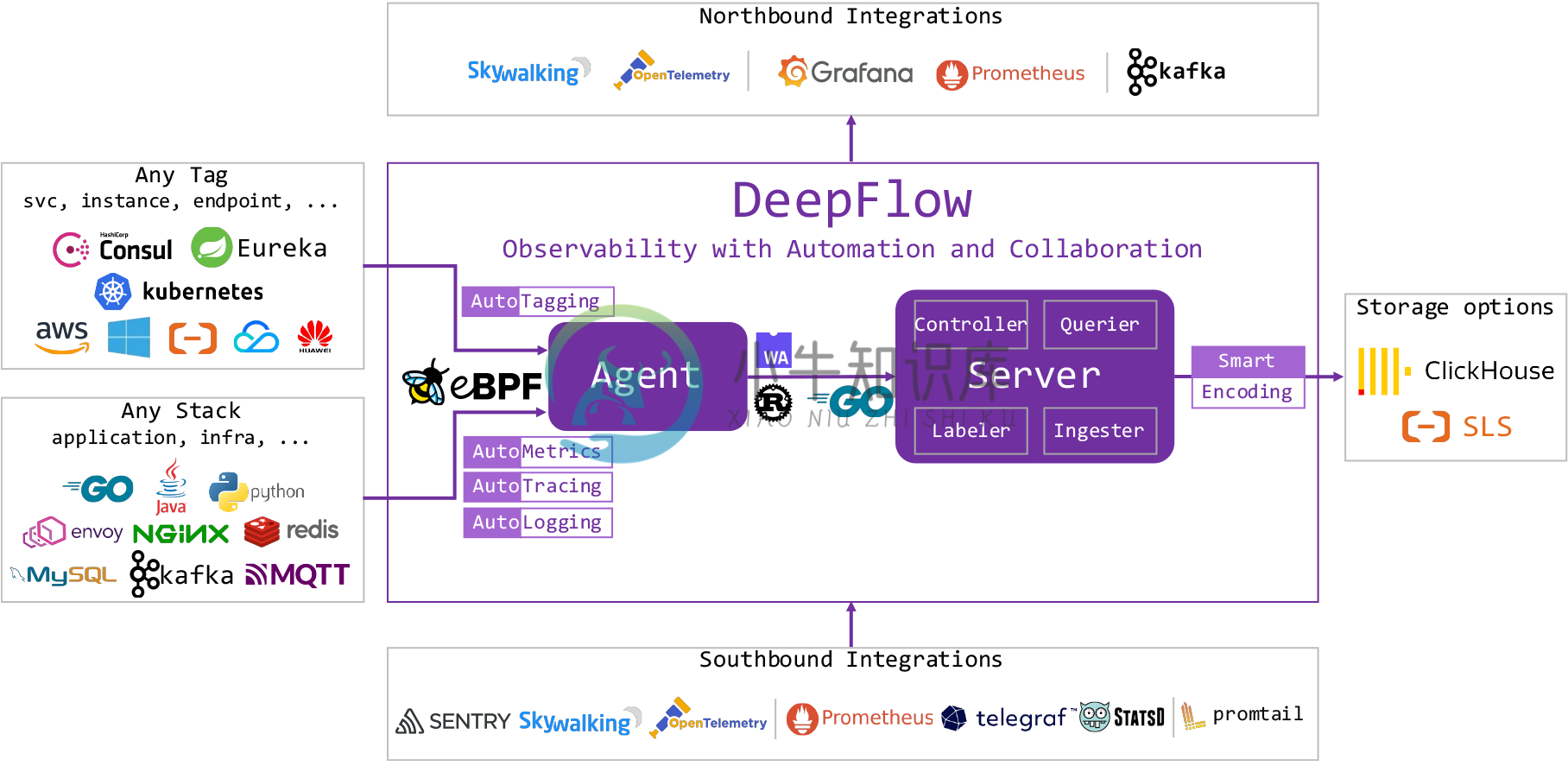
-
题目: DeepFlow: Deep Learning-Based Malware Detection by Mining Android Application for Abnormal Usage of Sensitive Data 单位:中国科技大学 摘要: Android的开放性允许应用程序开发人员充分利用系统。虽然这种灵活性给开发人员和用户带来了好处,但也可能带来与恶意应用程序相关的重大
-
B.恶意和良性的应用程序 我们对3000个良性应用程序和8000个恶意应用程序进行特征提取,其中良性应用程序是从 谷歌播放商店,涵盖了最受欢迎的应用程序在各种类别,后者包括来自恶意软件家族 Android恶意软件基因组计划[21]和VirusShare[17]濁 因为我们假设谷歌Play Store中流行的应用程序是合法的,所以我们认为从这些良性应用程序中提取的流构成了敏感数据的“正常”使用。相反
-
该篇文章的灵感来啊源于Brox &malik(2011)在变分光流法中引入描述子匹配用于计算大位移光流的一篇文章,我们的方法名为Deep flow,将匹配算法与变分方法相结合,应用于光流的计算,是一种适应光流问题的描述子匹配算法,可以提高光流法在快速运动的表现。匹配算法建立在具有6层,交错卷积和最大池的多层架构之上,这种结构类似于深度卷积网络。 使用密集采样,它允许有效地检索准密集对应,并且在描述
-
目前针对 DNS 监控的 Grafana Dashboard 并不多,使用率较高的 Grafana CoreDNS 只适用于 K8s 环境,对于云服务器、物理硬件模式下的 DNS 监控也并不通用;同时,对于应用研发人员想定位 DNS 查询异常或者时延问题时,CoreDNS 的 Dashboard 仅提供 DNS 服务端视角,无法从应用视角出发来分析问题,只能依赖自身代码增加了 DNS 日志。 明确
-
每次我认为我理解了可观测物,但我不太理解可观测物。所以考虑一下我在Angular 4应用程序中使用的代码: 我希望我对代码解释得足够好,所以它的本质是我不想在任何地方使用“订阅”。因为我使用异步管道,所以我希望可以一直观察到。但是,当我使用单(),然后我必须平面映射它,否则它给我一个错误,因为我不能返回可观察 如果我没有把我的问题说清楚,我很抱歉。我的场景是,我基本上需要一个配置设置,我的实际ht
-
导览 本小节主要介绍 Apache ShardingSphere 可观察性的相关功能 应用性能监控集成
-
我有一个带有http请求的服务,它返回我的标题的可观察到的内容 servise.ts 在我的组件中,我有一个函数从service get Request设置。看起来是这样的: 问题是,有时我接收到带有空标签的标题,不需要显示它们,所以我需要对其进行过滤,并对此标题发送.delete()请求。我尝试了类似的方法(想法是在之前添加,然后在另一个subscribe内部调用。)差不多吧 但不确定这是不是个
-
我有一个可观察的对象,它从数据库游标的快速流中生成数据。我希望以每秒x项的速度限制输出。到目前为止,我一直在使用文档中所述的调用堆栈阻塞: 这很好,但出于好奇,是否有更好的方法使用背压来处理此问题? Tks公司
-
5月15日15:30——16:00(30分钟)腾讯会议 自我介绍 对可观测岗位的理解 什么是链路追踪 MySQL外键,生产环境中用过吗 MySQL锁机制展开讲一讲 Redis的Key淘汰策略,讲一下LRU算法 寻找数组中第K大的数,不能使用Arrays.sort,考虑排序的稳定性、数组的长度,排序算法的时间复杂度,手写堆排序(寄) 三数之和(过)优化方法(寄) 反问: 实习结果什么时候出(一周)
-
楼主研一,但是误投了暑期实习,所以顺便就面了 1.在滴滴工作做的内容 2.做短视频后端的背景是什么?为什么要做? 3.这个项目做了哪些东西? 4.关注的表是怎么设计的?关注和被关注者关系存储在一行么?存储在一行又什么问题?不存在一行又有什么问题?(没搞懂什么意思)(回答的不好) 5.项目中rabbitmq用在哪些场景?(关注和点赞) 6.rabbitmq的架构说一下 7.rabbitmq是否有消息