
Sparser 是一个用于解析原始数据的解析引擎,由斯坦福大学开源,用于非结构化和半结构化的数据格式,例如 JSON、Avro 和 Parquet。
特性
用原始过滤器过滤后再解析,丢弃那些不需要用假阳性率解析的记录
用高效的优化器选择级联的原始过滤器
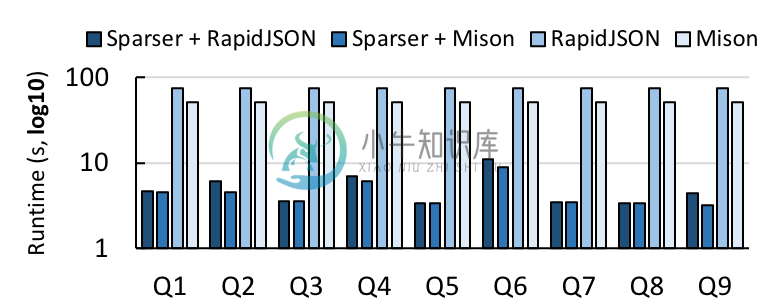
提供超过现有解析器 22 倍的加速度
Sparser 的独特之处在于它可利用 SIMD 加速过滤函数在解析之前过滤数据。在 JSON、Avro 和 Parquet 数据上,Sparser 的速度比最先进的解析器最多快 22 倍,并且能将 Apache Spark 中的端对端的查询运行时间最多提高 9 倍。
Sparser与现有技术的比较
-
主要内容:1.开源OLAP综述,2.开源数仓解决方案1.开源OLAP综述 如今的开源数据引擎多种多样,不同种类的引擎满足了我们不同的需求。现在ROLAP计算存储一体的数据仓库主要有三种,即StarRocks(DorisDB),ClickHouse和Apache Doris。应用最广的数据查询系统主要有Druid,Kylin和HBase。MPP引擎主要有Trino,PrestoDB和Impala。这些引擎在行业内有着广泛的应用。 在云资源层,主要有E
-
包括有以下 type: config _id 为 kibana5 的 version。内容主要是 defaultIndex,设置默认的 index_pattern. search _id 为 discover 上保存的搜索名称。内容主要是 title,column,sort,version,description,hits 和 kibanaSavedObjectMeta。kibanaSavedOb
-
在Seata1.3.0版本中,数据源自动代理和手动代理一定不能混合使用,否则会导致多层代理,从而导致以下问题: 单数据源情况下:导致分支事务提交时,undo_log本身也被代理,即为 undo_log 生成了 undo_log, 假设为undo_log2,此时undo_log将被当作分支事务来处理;分支事务回滚时,因为undo_log2生成的有问题,在undo_log对应的事务分支回滚时会将业务表
-
我有通过jndi名称从WebLogic获取数据源的应用程序。 我在应用程序中配置了jndi数据源名称。yml: 我在WebLogic服务器上配置了它,指定了特定的目标。我测试了这个数据源,WebLogic说测试成功了。但是当我尝试部署应用程序时,我收到以下错误: 我需要确定WebLogic的数据源配置中存在问题,或者在java代码中获取数据源时存在问题。我是否能够在不部署应用程序的情况下测试获取数
-
本文向大家介绍开源数据库,包括了开源数据库的使用技巧和注意事项,需要的朋友参考一下 开源数据库是具有开源代码的数据库,即任何人都可以查看,研究甚至修改代码。开源数据库可以是关系(SQL)或非关系(NoSQL)。 为什么要使用开源数据库? 为任何公司创建和维护数据库都非常昂贵。在软件总支出中,很大一部分用于处理数据库。因此,切换到低成本开源数据库是可行的。从长远来看,这可以为公司节省很多钱。 使用中
-
Entry conn.GetAsync() 返回的是一个 Entry 集合,Entry 对应 binlog 记录,它可能是事务标记也有可能是行数据变化,通过 Entry.EntryType 来区分,一般事务的标记在业务消费处理时不需要处理。 示例: var entries = await conn.GetAsync(1024); foreach (var entry in entries) {