
DeepSpeed 是一个深度学习优化库,它可以使分布式训练变得容易、高效和有效。
- 10x 更大的模型
- 5x 更快地训练
- 最小的代码更改
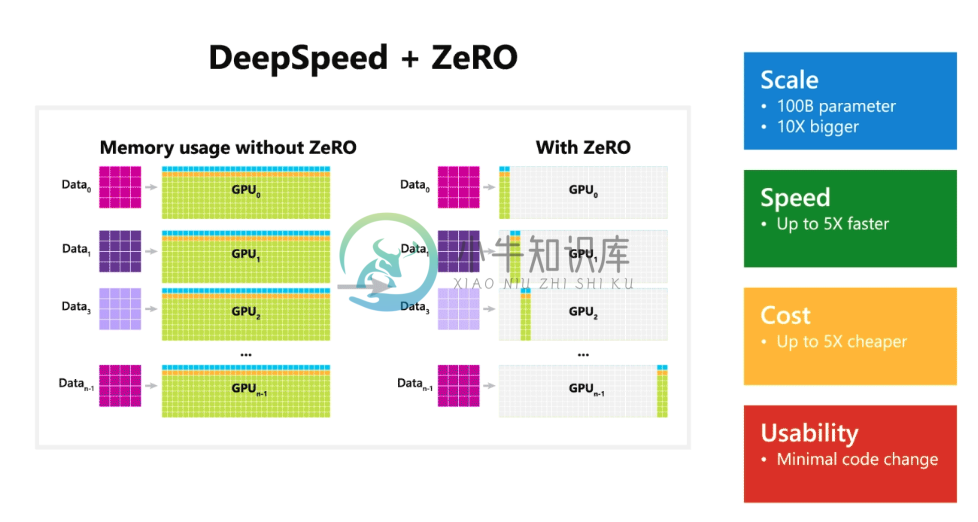
DeepSpeed 可以在当前一代的 GPU 集群上训练具有超过千亿个参数的 DL 模型,而与最新技术相比,其系统性能可以提高 5 倍以上。DeepSpeed 的早期采用者已经生产出一种语言模型(LM, Language Model),它具有超过 170 亿个参数,称为 Turing-NLG(Turing Natural Language Generation,图灵自然语言生成),成为 LM 类别中的新 SOTA。
DeepSpeed API 是在 PyTorch 上进行的轻量级封装,这意味着开发者可以使用 PyTorch 中的一切,而无需学习新平台。此外,DeepSpeed 管理着所有样板化的 SOTA 训练技术,例如分布式训练、混合精度、梯度累积和检查点,开发者可以专注于模型开发。同时,开发者仅需对 PyTorch 模型进行几行代码的更改,就可以利用 DeepSpeed 独特的效率和效益优势来提高速度和规模。
-
本文为DeepSpeed的入门介绍,通过以下维度帮助各位看官了解什么是DeepSpeed: What: DeepSpeed是什么? Why: DeepSpeed解决了什么痛点? How: DeepSpeed是怎么解决这个痛点问题的?(这个下周更) 近年来机器学习一直是 一个很热门的话题,它在视觉,自然语言,语音等领域突不断突破,达到新的高度。之所以有不断有新的成果涌现,我理解大厂们开源的机器学习框
-
DeepSpeedExamples/applications/DeepSpeed-Chat at master · microsoft/DeepSpeedExamples · GitHub �� DeepSpeed-Chat:简单,快速和负担得起的RLHF训练的类chatgpt模型 �� 一个快速、经济、可扩展和开放的系统框架,用于实现端到端的强化学习人类反馈(RLHF)训练体验,以在所有尺度上生
-
Megatron-Deepspeed 预训练 GPT-小白踩坑与解决 记录在使用 megatron deepspeed 训练大模型 gpt 时,遇到的坑 1. 成功运行的最终步骤 1.1 配置分布式环境: 1.1.1 硬件配置: 3090 单机四卡 root@xxxx:/workspace# nvidia-smi -L GPU 0: NVIDIA GeForce RTX 3090 (UUID: G
-
Windows 系统来做一些前沿开发,估计连微软自家的孩子们也都鄙视,在Win 11下搭建Deepspeed 环境,遇到 PS C:\WINDOWS\system32> pip install deepspeed Collecting deepspeed Downloading deepspeed-0.9.0.tar.gz (764 kB) --------------------
-
相关博客 【深度学习】【分布式训练】Collective通信操作及Pytorch示例 【自然语言处理】【分布式训练及推理】推理工具DeepSpeed-Inference 【自然语言处理】【chatGPT系列】大语言模型可以自我改进 【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答 【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
-
本文展示了如何使用 1760 亿 (176B) 参数的 BLOOM 模型[1] 生成文本时如何获得超快的词吞吐 (per token throughput)。 因为在使用 bf16 (bfloat16) 权重时该模型内存占用为 352 GB (176*2),所以最高效的硬件配置是使用 8x80GB 的 A100 GPU。也可使用 2x8x40GB 的 A100 或者 2x8x48GB 的 A600
-
虚拟环境Python版本建议安装3.8版本 首先克隆github中的DeepSpeed文件 git clone https://github.com/microsoft/DeepSpeed.git 文件下载完毕后进入DeepSpeed文件夹 cd DeepSpeed 进入DeepSpeed文件夹后 ./install.sh 耐心等待安装结束。 安装完成之后输入 ds_report 如果全部的都显
-
多台docker宿主机网络配置 https://docs.docker.com/network/overlay/ 这里需要创建overlay网络是多台宿主机的容器可以通过网络连接 创建集群 docker swarm init 另一台机器加入集群 docker swarm join --token SWMTKN-1-1nnq6klpq7z93lqmshd4rqvk44x1qyyen4wacuei1
-
本节将讨论优化与深度学习的关系,以及优化在深度学习中的挑战。在一个深度学习问题中,我们通常会预先定义一个损失函数。有了损失函数以后,我们就可以使用优化算法试图将其最小化。在优化中,这样的损失函数通常被称作优化问题的目标函数(objective function)。依据惯例,优化算法通常只考虑最小化目标函数。其实,任何最大化问题都可以很容易地转化为最小化问题,只需令目标函数的相反数为新的目标函数即可
-
Keras 是一个高层神经网络 API,Keras 由纯 Python 编写而成并基 Tensorflow、Theano 以及 CNTK 后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择 Keras: 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性) 支持 CNN 和 RNN,或二者的结合 无缝 CPU 和 GPU 切换 Kera
-
停止更新通知 Hi all,十分感谢大家对keras-cn的支持,本文档从我读书的时候开始维护,到现在已经快两年了。这个过程中我通过翻译文档,为同学们debug和答疑学到了很多东西,也很开心能帮到一些同学。 从2017年我工作以后,由于工作比较繁忙,更新频率有所下降。到今年早期的时候这种情况更加严重,加之我了解到,keras官方已经出了中文文档,更觉本份文档似乎应该已经基本完成了其历史使命,该到了
-
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
-
相关专题 《深度学习》整理 CNN 专题 RNN 专题 优化算法专题 随机梯度下降 动量算法 自适应学习率算法 基于二阶梯度的优化算法 《深度学习》 5.2 容量、过拟合和欠拟合 欠拟合指模型不能在训练集上获得足够低的训练误差; 过拟合指模型的训练误差与测试误差(泛化误差)之间差距过大; 反映在评价指标上,就是模型在训练集上表现良好,但是在测试集和新数据上表现一般(泛化能力差); 降低过拟合风险的
-
译者:bdqfork 作者: Robert Guthrie 深度学习构建模块:仿射映射, 非线性函数以及目标函数 深度学习表现为使用更高级的方法将线性函数和非线性函数进行组合。非线性函数的引入使得训练出来的模型更加强大。在本节中,我们将学习这些核心组件,建立目标函数,并理解模型是如何构建的。 仿射映射 深度学习的核心组件之一是仿射映射,仿射映射是一个关于矩阵A和向量x,b的*f(x)*函数,如下所
-
这就是Keras Keras是一个高层神经网络库,Keras由纯Python编写而成并基Tensorflow或Theano。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果,如果你有如下需求,请选择Keras: 简易和快速的原型设计(keras具有高度模块化,极简,和可扩充特性) 支持CNN和RNN,或二者的结合 支持任意的链接方案(包括多输入和多输出训练) 无缝CPU和GPU切换
-
译者 bruce1408 作者: Robert Guthrie 本文带您进入pytorch框架进行深度学习编程的核心思想。Pytorch的很多概念(比如计算图抽象和自动求导)并非它所独有的,和其他深度学习框架相关。 我写这篇教程是专门针对那些从未用任何深度学习框架(例如:Tensorflow, Theano, Keras, Dynet)编写代码而从事NLP领域的人。我假设你已经知道NLP领域要解决