
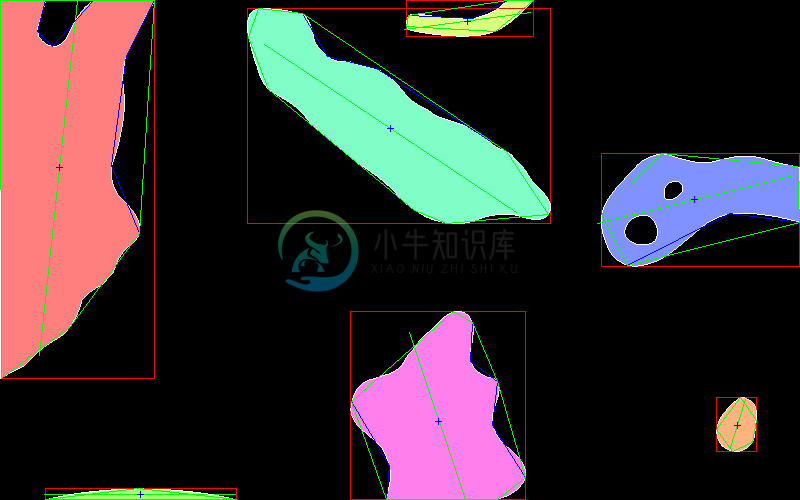
cvBlob 是计算机视觉应用中在二值图像里寻找连通域的库.能够执行连通域分析与特征提取.
-
注意事项 1)添加命名空间 using namespace cvb; 2) // unique_ptr<IplImage, void(*)(IplImage*)> labelImg(cvCreateImage(cvSize(width, height), IPL_DEPTH_LABEL, 1), // [](IplImage* p){ cvReleaseImage(&p);
-
OpenCV的cvBlobsLib库的作用类似于matlab中的regionprops函数。 cvBlobsLib库的编译: 首先从http://opencv.willowgarage.com/wiki/cvBlobsLib#Blobextractionlibrary下载最新的v8.3版本的源代码,其次机子上要装有OpenCV1.0的环境,从http://www.opencv.org.cn/ind
-
场景 由于编译的时候,代码生成的运行库选择MDd,但是看到在堆中释放资源的时候,开始出错,并且是在dll中释放资源出错,初步怀疑是在不同的模块中申请和释放资源导致的问题,问题是在所有的dll中生成都是使用MDd,原则应该没有什么问题。预计将cvBlob的代码拷贝到测试例子中,而不是作为静态库加载看看是否会避免崩溃的问题 ntdll.dll!00000000775c9e51() [下
-
在机器学习中,灰度图像的特征提取是一个难题。 我有一个灰色的图像,是用这个从彩色图像转换而来的。 我实际上需要从这张灰色图片中提取特征,因为下一部分将训练一个具有该特征的模型,以预测图像的彩色形式。 我们不能使用任何深度学习库 有一些方法,如快速筛选球。。。但我真的不知道如何才能为我的目标提取特征。 以上代码的输出就是真的。 有什么解决方案或想法吗?我该怎么办?
-
Spark特征提取(Extracting)的3种算法(TF-IDF、Word2Vec以及CountVectorizer)结合Demo进行一下理解 TF-IDF算法介绍: 词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。 词语由t表示,文档由d表示,语料库由D表示。词频TF(t,,d)是词语t在文档d中出现的次数。文件频率D
-
校验者: @if only 翻译者: @片刻 模块 sklearn.feature_extraction 可用于提取符合机器学习算法支持的特征,比如文本和图片。 Note 特征特征提取与 特征选择 有很大的不同:前者包括将任意数据(如文本或图像)转换为可用于机器学习的数值特征。后者是将这些特征应用到机器学习中。 4.2.1. 从字典类型加载特征 类 DictVectorizer 可用于将标准的Py
-
卷积神经网络包括主要特征,提取。以下步骤用于实现卷积神经网络的特征提取。 第1步 导入相应的模型以使用“PyTorch”创建特征提取模型。 第2步 创建一类特征提取器,可以在需要时调用。
-
本文向大家介绍opencv2基于SURF特征提取实现两张图像拼接融合,包括了opencv2基于SURF特征提取实现两张图像拼接融合的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了opencv2实现两张图像拼接融合的具体代码,供大家参考,具体内容如下 要用到两个文件,estimate.cpp和matcher.h(在有关鲁棒匹配这篇博文中有) estimate.cpp的头文件也需要添加一
-
分类变量的特征提取 比如城市作为一个特征,那么就是一系列散列的城市标记,这类特征我们用二进制编码来表示,是这个城市为1,不是这个城市为0 比如有三个城市:北京、天津、上海,我们用scikit-learn的DictVector做特征提取,如下: # coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) from