
C++ Eigen库计算矩阵特征值及特征向量

本文主要讲解利用Eigen库计算矩阵的特征值及特征向量并与Matlab计算结果进行比较。
C++Eigen库代码
#include <iostream>
#include <Eigen/Dense>
#include <Eigen/Eigenvalues>
using namespace Eigen;
using namespace std;
void Eig()
{
Matrix3d A;
A << 1, 2, 3, 4, 5, 6, 7, 8, 9;
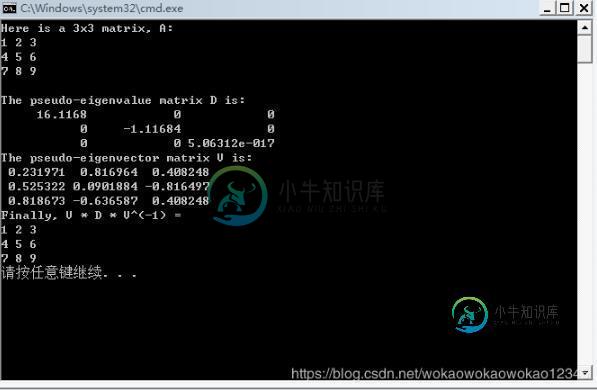
cout << "Here is a 3x3 matrix, A:" << endl << A << endl << endl;
EigenSolver<Matrix3d> es(A);
Matrix3d D = es.pseudoEigenvalueMatrix();
Matrix3d V = es.pseudoEigenvectors();
cout << "The pseudo-eigenvalue matrix D is:" << endl << D << endl;
cout << "The pseudo-eigenvector matrix V is:" << endl << V << endl;
cout << "Finally, V * D * V^(-1) = " << endl << V * D * V.inverse() << endl;
}
int main()
{
Eig();
}
计算结果:
最大最小特征值及其索引位置
//maxCoeff //minCoeff int col_index, row_index; cout << D.maxCoeff(&row_index, &col_index) << endl; cout << row_index << " " << col_index << endl;
Matlab 代码
clear all clc A = [1 2 3;4 5 6;7 8 9] [V,D] = eig(A)
Matlab计算结果

主成份分析以及许多应用时候,需要对特征值大小排列。
A = magic(6); [V,D] = eig(A) [D_S,index] = sort(diag(D),'descend') V_S = V(:,index)
结果
V = 0.4082 -0.2887 0.4082 0.1507 0.4714 -0.4769 0.4082 0.5774 0.4082 0.4110 0.4714 -0.4937 0.4082 -0.2887 0.4082 -0.2602 -0.2357 0.0864 0.4082 0.2887 -0.4082 0.4279 -0.4714 0.1435 0.4082 -0.5774 -0.4082 -0.7465 -0.4714 0.0338 0.4082 0.2887 -0.4082 0.0171 0.2357 0.7068 D = 111.0000 0 0 0 0 0 0 27.0000 0 0 0 0 0 0 -27.0000 0 0 0 0 0 0 9.7980 0 0 0 0 0 0 -0.0000 0 0 0 0 0 0 -9.7980 D_S = 111.0000 27.0000 9.7980 -0.0000 -9.7980 -27.0000 V_S = 0.4082 -0.2887 0.1507 0.4714 -0.4769 0.4082 0.4082 0.5774 0.4110 0.4714 -0.4937 0.4082 0.4082 -0.2887 -0.2602 -0.2357 0.0864 0.4082 0.4082 0.2887 0.4279 -0.4714 0.1435 -0.4082 0.4082 -0.5774 -0.7465 -0.4714 0.0338 -0.4082 0.4082 0.2887 0.0171 0.2357 0.7068 -0.4082
结语
本人是在实验中利用Eigen库求取最小特征值对应特征向量做PCA分析时使用,曾经再不知道有Eigen库的情况下自己写过矩阵相关运算的模板类,现在接触到Eigen库,就把困扰过自己的问题今天做一个小小总结。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍numpy.linalg.eig() 计算矩阵特征向量方式,包括了numpy.linalg.eig() 计算矩阵特征向量方式的使用技巧和注意事项,需要的朋友参考一下 在PCA中有遇到,在这里记录一下 计算矩阵的特征值个特征向量,下面给出几个示例代码: 在使用前需要单独import一下 官方文档链接:http://docs.scipy.org/doc/numpy/reference/g
-
特征值
-
将跟踪和跨度添加到Slf4J MDC,以便您可以从日志聚合器中的给定跟踪或跨度中提取所有日志。示例日志: 2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd
-
反缓存 anticache设置该选项后,它将删除可能引起服务器响应的Header(if-none-match和if-modified-since)304 not modified。当您要确保完全捕获HTTP交换时,这很有用。当您要确保服务器以完整的数据响应时,也经常在客户端重播期间使用它。 客户端重播 客户端重播可以做到:您提供了一个以前保存的HTTP对话,而mitmproxy则一个接一个地重播了
-
本文向大家介绍xgboost的特征重要性计算相关面试题,主要包含被问及xgboost的特征重要性计算时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Xgboost根据结构分数的增益情况计算出来选择哪个特征作为分割点,而某个特征的重要性就是它在所有树中出现的次数之和。
-
特征缩放是用来统一资料中的自变项或特征范围的方法,在资料处理中,通常会被使用在资料前处理这个步骤。 1 动机 因为在原始的资料中,各变数的范围大不相同。对于某些机器学习的算法,若没有做过标准化,目标函数会无法适当的运作。举例来说,多数的分类器利用两点间的距离计算两点的差异, 若其中一个特征具有非常广的范围,那两点间的差异就会被该特征左右,因此,所有的特征都该被标准化,这样才能大略的使各特征