
JVM Profiler 是 Uber Engineering 团队开源的一个分布式探查器,用于收集性能和资源使用率指标为进一步分析提供服务。尽管它是为 Spark 应用而构建的, 但它的通用实现使其适用于任何基于 JVM 的服务或应用。
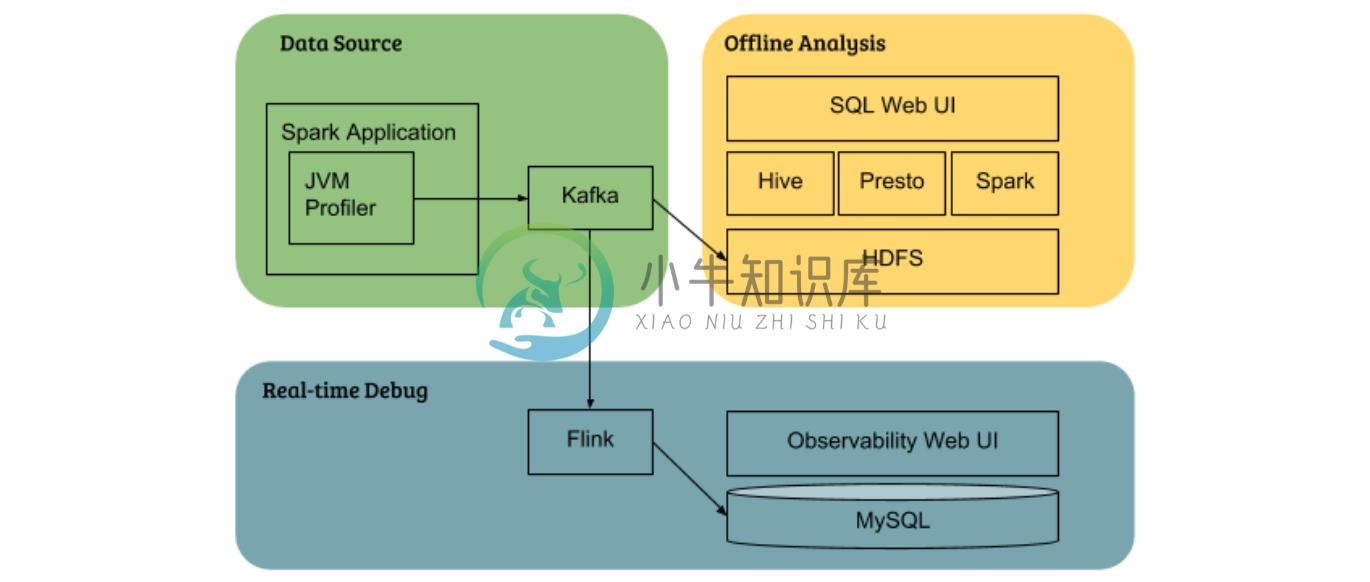
JVM Profiler 由三项主要功能组成, 它使收集性能和资源使用率指标变得更容易, 然后可以将这些指标 (如 Apache Kafka) 提供给其他系统进行进一步分析:
代理功能 ( java agent ) : 支持用户以分布式的方式收集各种指标 (例如如 CPU/内存利用率) ,用于 JVM 进程的堆栈跟踪。
高级分析功能(Advanced profiling capabilities): 支持跟踪任意 Java 方法和用户代码中的参数, 而不进行任何实际的代码更改。此功能可用于跟踪 Spark 应用的 HDFS NameNode RPC 调用延迟, 并标识慢速方法调用。它还可以跟踪每个 Spark 应用读取或写入的 HDFS 文件路径, 用以识别热文件后进一步优化。
数据分析报告( Data analytics reporting ): 使用 JVM Profile 可以将指标数据推送给 Kafka topics 和 Apache Hive tables , 提高数据分析的速度和灵活性。
典型用例
JVM Profiler 支持各种用例, 最典型的是能够检测任意 Java 代码。基于简单的配置, JVM Profiler 就可以附加到 Spark 应用中的每个执行者(executor)收集 Java 方法运行时度量。下面, 我们对其中的一些用例进行讨论:
Right-size executor : JVM Profiler 中的内存度量支持跟踪每个执行者的实际内存使用情况。借此 可以在 Spark 应用中 ”executor-memory” 设置最优参数。
监视 HDFS NameNode RPC 延迟: 例如在 Spark 应用中对类 org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB 的方法进行了分析并确定 NameNode 调用的延迟。Uber 每天都要监控5万多个 Spark 应用, 其中有数以亿计的这种 RPC 调用。
监视驱动程序丢弃的事件: 例如监视 org.apache.spark.scheduler.LiveListenerBus.onDropEvent, 跟踪 Spark 驱动程序事件队列太长、队列删除事件。
跟踪数据沿袭: 例如分析 Java 方法上的文件路径参数 ( org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getBlockLocations , org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.addBlock ) , 可以跟踪哪些文件是由 Spark 应用读取和写入的。
介绍来源:RiboseYim
-
背景 uber jvm profiler是用于在分布式监控收集jvm 相关指标,如:cpu/memory/io/gc信息等 安装 确保安装了maven和JDK>=8前提下,直接mvn clean package java application 说明 直接以java agent的部署就可以使用 使用 java -javaagent:jvm-profiler-1.0.0.jar=reporter=c
-
在文章开头,我想先做几点说明: 1、本文的内容来自我对Yarn的相应功能的理解和实践。而我对该部分功能的理解主要来自对Hadoop的开发者之前相应言论的分析,并且我也将我的分析发给了Hadoop community, 并得到了Yarn的创始人兼架构师Arun Murthy的肯定回复。 2、本文中uber的配置部分,主要参考之前Hadoop开发者的言论。但是我当初看该言论的时候对一些细节有所疑惑,因
-
原文 http://blog.csdn.net/samhacker/article/details/15692003 yarn-site.xml 主要是这几个参数 - mapreduce.job.ubertask.enable | (false) | 是否启用user功能。如果启用了该功能,则会将一个“小的application”的所有子task在同一个JVM里面执行,达到JVM重用的目的。这个
-
修改IDEA的NVM内存配置中的内存大小及垃圾回收算法 配置文件位置为idea安装目录下的bin文件夹中的…vmoptions文件,64位系统用的是文件名包含64的。 原配置如下: -Xms128m -Xmx750m -XX:ReservedCodeCacheSize=240m -XX:+UseConcMarkSweepGC -XX:SoftRefLRUPolicyMSPerMB=50 -ea -
-
Hadoop 1.x中的JVM重用功能 简单回顾一下Hadoop 1.x中的JVM重用功能 用户可以通过更改配置,来指定TaskTracker在同一个JVM里面最多可以累积执行的Task的数量(默认是1)。这样的好处是减少JVM启动、退出的次数,从而达到提高任务执行效率的目的。 配置的方法 通过设置mapred-site.xml里面参数mapred.job.reuse.jvm.num.tasks的
-
JVM调优情况十分复杂,各种情况都可能导致垃圾回收不能够达到预想的效果。对于场景问题,可以从如下几个大方向进行设计: 大访问压力下,MGC 频繁一些是正常的,只要MGC 延迟不导致停顿时间过长或者引发FGC ,那可以适当的增大Eden 空间大小,降低频繁程度,同时要保证,空间增大对垃圾回收产生的停顿时间增长是可以接受的。 如果MinorGC 频繁,且容易引发 Full GC。需要从如下几个角度进行
-
我们根据JVM参数以-X开头或-XX开头将JVM参数分成三个部分: 1、以-开头的是标准VM选项,VM规范的选项; 2、以-X开头的都是非标准的(这些参数并不能保证在所有的JVM上都被实现),而且如果在新版本有什么改动也不会发布通知。 3、以-XX开头的都是不稳定的并且不推荐在生产环境中使用。这些参数的改动也不会发布通知。 Bool型参数选项:-XX:+ 打开, -XX:- 关闭。(比如-XX:+
-
virtualVM是我几年前用过的jdk自带的监控工具,能监控内存,堆栈,线程等粗略的统计信息; JProfiler是最近用的,比virtualVM要更详细,更专业,基本上覆盖了virtualVM的功能点,还有一些更细致的功能,精确到代码某一行,是个单进程java分析利器。 yourkit没有用过,大体功能和JProflier类似 JVM profiler是个好东西,可以分析spark
-
在maven的一些文档中我们会发现 "uber-jar"这个术语,许多人看到后感到困惑。其实在很多编程语言中会把super叫做uber (因为suber可能是关键字), 这是上世纪80年代开始流行的,比如管superman叫uberman。所以uber-jar从字面上理解就是super-jar,这样的jar不但包含自己代码中的class ,也会包含一些第三方依赖的jar,也就是把自身的代码和其依赖
-
在Git中‘追踪分支’是用与联系本地分支和远程分支的. 如果你在’追踪分支'(Tracking Branches)上执行推送(push)或拉取(pull)时, 它会自动推送(push)或拉取(pull)到关联的远程分支上. 如果你经常要从远程仓库里拉取(pull)分支到本地,并且不想很麻烦的使用"git pull "这种格式; 那么就应当使用‘追踪分支'(Tracking Branches). ‘
-
日前,观察性分析平台和应用性能管理系统 SkyWalking 完成了与云原生网络代理 MOSN 的集成,作为 MOSN 中的支持的分布式追踪系统之一,旨在实现在微服务和 Service Mesh 中的更强大的可观察性。 相比传统的巨石(Monolith)应用,微服务的一个主要变化是将应用中的不同模块拆分为了独立的进程。在微服务架构下,原来进程内的方法调用成为了跨进程的远程方法调用。相对于单一进程内
-
当我将单体应用拆成多个微服务之后,如何监控服务之间的依赖关系和调用链,以判断应用在哪个服务环节出了问题,哪些地方可以优化?这就需要用到分布式追踪(Distributed Tracing)。 CNCF 提出了分布式追踪的标准 OpenTracing,它提供用厂商中立的 API,并提供 Go、Java、JavaScript、Python、Ruby、PHP、Objective-C、C++ 和 C# 这九
-
本文向大家介绍ASP.NET Core利用Jaeger实现分布式追踪详解,包括了ASP.NET Core利用Jaeger实现分布式追踪详解的使用技巧和注意事项,需要的朋友参考一下 前言 最近我们公司的部分.NET Core的项目接入了Jaeger,也算是稍微完善了一下.NET团队的技术栈。 至于为什么选择Jaeger而不是Skywalking,这个问题我只能回答,大佬们说了算。 前段时间也在CSh
-
随着服务的数量和复杂性的增加,跨数据中心的统一的可观察性变得越来越重要。Linkerd 的跟踪和度量工具旨在汇总,为所有服务的健康提供广泛而细致的洞察。Linkerd 作为服务网格的角色使其成为可观察性信息的理想数据源,特别是在多语言环境中。 当请求通过多个服务时,使用传统的调试技术来识别性能瓶颈变得越来越困难。分布式跟踪提供通过多个服务的请求的整体视图,允许立即识别延迟问题。 使用 linker
-
这是我的控制台中的日志格式。我正在使用spring cloud stream将我的日志从应用程序传输到logstash,这是logstash中的日志解析格式 这是我的logstash.conf 这是我在log-stash控制台中的输出。这是解析异常 {“message”=>“[{\”traceid\“:\”411a0496b048bcf4\“,\”parentId\“:\”8d40fcfea926
-
本章介绍如何使用Zipkin或Jaeger收集启用了Istio的应用程序的调用链信息。 完成本章后,你可以理解有关应用程序的所有假设以及如何使其参与跟踪,无论您使用何种语言/框架/平台构建应用程序。 BookInfo示例用来作为此任务的示例应用程序。 环境准备 参照安装指南的说明安装Istio。 如果您在安装过程中未启动Zipkin或Jaeger插件,则可以运行以下命令启动: 启动Zipkin:
-
综述 堆栈回溯信息本身并不是漏洞,但是他们通常为攻击者揭露了有趣的信息。攻击者尝试通过恶意HTTP请求和改变输入数据来产生这些堆栈追踪信息。 如果应用程序响应的堆栈回溯信息没有很好管理,他们可能为攻击者揭示有用的信息。这些信息可能被用于进一步的攻击中。基于多种原因,提供调试信息作为产出错误的页面返回结果被认为是一项不好的操作实践。例如,他们可能包含应用程序内部工作信息,如相对路径或对象是如何被内部