
easyLambda 是一个 C++ 的 MPI 和数据处理框架。该项目旨在满足使用 C++ 进行标准化的数据处理。设计的目标是可组合、易用接口、去耦合 I/O,算法逻辑无需关注数据格式和并行处理代码,减少样板代码数量。可方便的处理类型安全的数据流管道,MapReduce 操作,MPI 并行计算 等等。
easyLambda 使用 ezl 来编写数据处理任务,下面是一个示例的 ezl 任务:
ezl::rise(ezl::kick(10000)) // 10000 trials in total
.map([] {
auto x = rand01();
auto y = rand01();
return x*x + y*y;
})
.filter(ezl::lt(1.))
.reduce(ezl::count(), 0)
.map([](int inCircleCount) {
return (4.0 * inCircleCount / 10000);
}).colsTransform().dump()
.run();
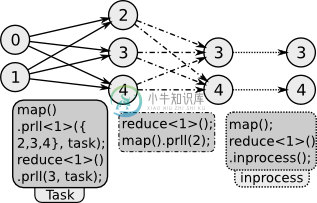
并行计算模型:
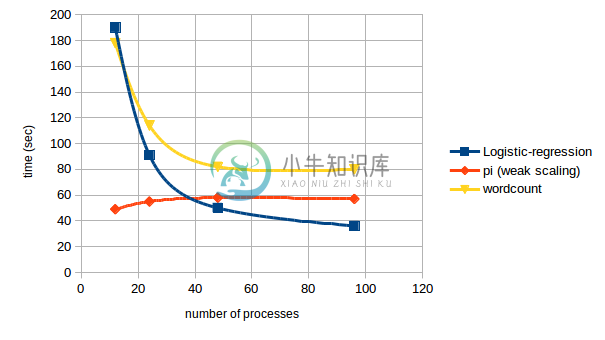
性能测试结果:
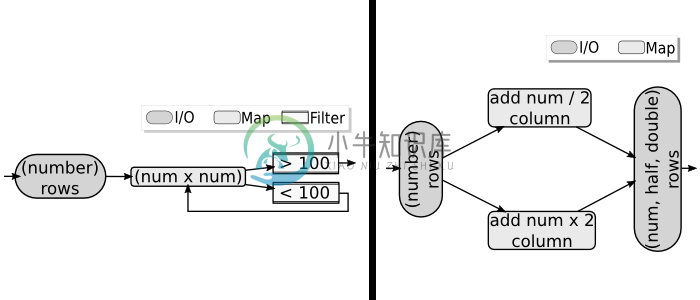
数据流:
要求:
c++14 兼容的编译器和 MPI (mpic++/mpicxx 和 mpirun)
支持 gcc-5.1 和 clang-3.5 或者更新版本
在 gcc-5.3, gcc-6.0(dev. branch), Apple LLVM version 7.0.0 (clang-700.0.72) 下测试通过
boost::mpi, boost::serialization 测试通过的版本是 5.8 和 6.0.
MPI 是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。
主要的MPI-1模型不包括共享内存概念,MPI-2只有有限的分布共享内存概念。 但是MPI程序经常在共享内存的机器上运行。在MPI模型周边设计程序比在NUMA架构下设计要好因为MPI鼓励内存本地化。
尽管MPI属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定惯例集(API)组成,可由C,C++,Fortran,或者有此类库的语言比如C#, Java or Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。
下面是一个用于统计单词数量的示例代码:
#include <string>
#include <boost/mpi.hpp>
#include "ezl/ezl.hpp"
#include "ezl/algorithms/readFile.hpp"
#include "ezl/algorithms/reduces.hpp"
int main(int argc, char* argv[]) {
using std::string;
using ezl::readFile;
boost::mpi::environment env(argc, argv);
ezl::rise(readFile<string>(argv[1]).rowSeparator('s').colSeparator(""))
.reduce<1>(ezl::count(), 0).dump()
.run();
return 0;
}-
是一个通用数据库处理框架(可以包含MSSQL POSTGRESQL,SQLITE EXCEL MYSQL DB2 ORACLE...只要你愿意实现接口就可以).很便捷地进行常用数据库操作(增删改查).其性能是几近纯ADO.NET.对于实体的查询采用emit实 现,如果您还不满意可用此框架的代码生成器直接生成纯ADO.NET SQL形式.其主要特色就是性能和便捷的操作.
-
好吧,我对使用Scala/Spark还比较陌生,我想知道是否有一种设计模式可以在流媒体应用程序中使用大量数据帧(几个100k)? 在我的示例中,我有一个SparkStreaming应用程序,其消息负载类似于: 因此,当用户id为123的消息传入时,我需要使用特定于相关用户的SparkSQL拉入一些外部数据,并将其本地缓存,然后执行一些额外的计算,然后将新数据持久保存到数据库中。然后对流外传入的每条
-
数据处理 可将字段的值进行处理得到最终结果 html标签过滤 内容替换 批量替换 关键词过滤 条件判断 截取字符串 翻译 工具箱 将文本链接标记为图片链接:如果字段的值是完整的url链接(非<img>标签内的链接),可将链接识别为图片 使用函数 调用接口
-
求大佬推荐个数据处理的开源项目,功能大概包含元数据管理、数据质量管理、数据共享交换、数据资源目录等几大功能?搜变gitee 也没找到个
-
我遇到了一些数据,我想用许多不同的方式对它进行排序,例如按购买最多的最便宜的产品进行排序。我想一行一行地对文档进行分组,因为每行包含另一个“项目”。我附上了一张图片供参考。我更喜欢使用Java,但如果有必要,我会学习R。我是否手动将每行编码为数组?有400个项目,如果这是唯一的方法,我可以将其分成几天。 样品
-
Data Preparation You must pre-process your raw data before you model your problem. The specific preparation may depend on the data that you have available and the machine learning algorithms you want
-
在输入的JSON数据中,v的值越高,粒子越亮,并且它们从出发国家到目的国家的运行越快。 (请查阅Michael Chang的文章来 了解他是如何提出这个想法的)。Gio.js库会自动缩放输入数据的范围以便于更好的数据可视化。作为开发人员,您还可以定义自己的预处理数据的方式。
-
随着数据获取的便捷,GIS数据已不再成为GIS分析的瓶颈,但对海量数据的加载却又成了GIS相关软件的难题。LocaSpaceViewer对数据的加载进行了大量的优化,极大的加快了数据的加载速度。同时经过各种摸索,不断的改进算法与数据的存储和读取方式,研究出了能够加载速度更快的数据结构。 LocaSpaceViewer提供了数据影像处理功能,可以把多个影像或者地形数据进行