
Opendedup,一个新的开源重复数据删除解决方案。作为针对Linux的重复数据删除文件系统(也成 为SDFS),Opendedup从设计上来说针对的是那些拥有虚拟环境并寻求高性能、可扩展和低成本重复数据删除解决方案的企业。
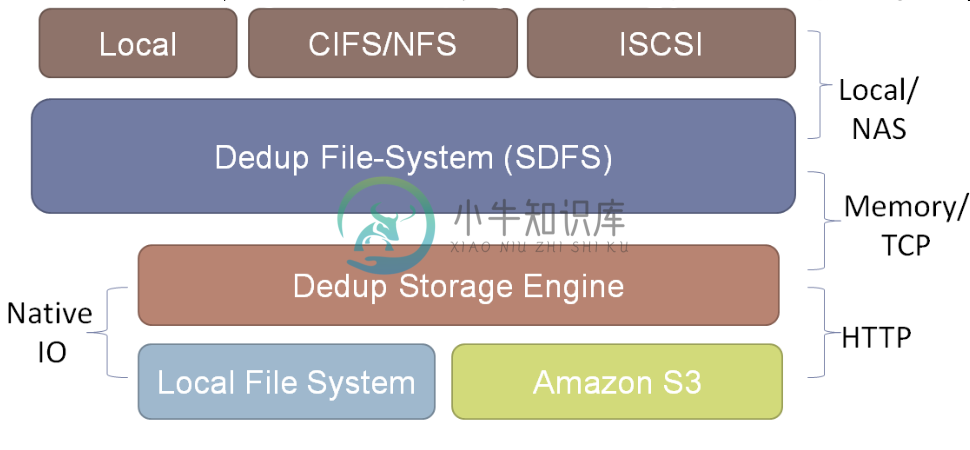
根据开发者Sam Silverberg的说法,"SDFS的设计目标是利用基于对象的文件系统的性能和可扩展性优点,通过重复数据删除优化存储。"结果 是:"Opendedup/SDFS可以优化1PB以上的数据;在128K块大小的情况下,每GB记忆体支持3TB以上数据;在线重复数据删除的执行速度 达到290MB/秒;拥有很高的总I/O性能;支持VMware(以及Xen和KVM),并可以对4K的块进行重复数据删除操作。同时,它还是免费的。
Silverberg表示,在标准的Linux系统上,Opendedup/SDFS的安装只需要大约20分钟时间,而且不需要编译。他表 示:"SDFS卷可以像Linux文件系统那样载入和创建。如果用户曾经在Linux系统上载过卷,那么他肯定对SDFS的命令也很熟悉。"此外,对那些 需要一些帮助的用户,SDFS还有一个快速开始指导,同时在Opendedup网站上还有详细的管理操作指导。那么,使用Linux系统的用户是否可以使 用Opendedup并从中获益呢?
根据Silverberg的说法,SDFS的适用对象包括:所有大量利用虚拟化的组织("SDFS 可以跨共享的SDFS卷或在单独的SDFS卷上对数百个虚拟机进行重复数据删除.......而且可以加速新的虚拟机并快速复制现有的虚拟机"),或那些 寻求高存储效率和基于磁盘备份系统的组织("SDFS卷可以呈现给基于磁盘的备份,并带来存储节约和I/O提升的好处"),或那些需要归档大量数据的组织 ("SDFS卷可以当作NAS(网络附加存储)共享......同时非结构化数据可以复制并归档到作为第三层存储的SDFS卷")。
不 过,Opendedup/SDFS真的可以作为专有解决方案的替代品么?
Silverberg表示:"同许多专有解决方案相 比,SDFS在性能、可扩展性和成本上具有优势,不过我认为专有解决方案有一定的真正的技术上的优势。开源解决方案目前还不能提供远程复制功能、基于来源 端的重复数据删除和一周七天一天24小时的无间断的电话支持。"
Silverberg表示,SDFS是一个文件系统,"这使得它可以很 容易作为一个存储设备来实施",不过"如果不契合到专有API(应用程序编程接口),它更难深入地整合到备份和虚拟机管理器等解决方案"。
不 过,他补充道:"如果用户希望获得的是来自文件系统的裸性能、可扩展性和重复数据删除功能,那么SDFS是个理想选择。"显然很多企业是这样的,因为就在 第一周,Opendedup.org就吸引了1.4万个独立访客的访问,其中许多人下载了软件。
-
Opendedup 1.2.0 包含一个更新的 Windows 移植版本,更好的垃圾收集以及更好的性能,修复了复制、垃圾收集和线程相关的 bug。 Opendedup,一个新的开源重复数据删除解决方案。作为针对Linux的重复数据删除文件系统(也成 为SDFS),Opendedup从设计上来说针对的是那些拥有虚拟环境并寻求高性能、可扩展和低成本重复数据删除解决方案的企业。
-
Filesystem3接口继承自FilesystemConstants接口,其中有以下成员: public int getattr(String path, FuseGetattrSetter getattrSetter) throws FuseException; public int readlink(String path, CharBuffer link) throws Fus
-
http://www.opendedup.org/ 原文出处:Netkiller 系列 手札 本文作者:陈景峯 转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。
-
XattrSupport接口主要用来实现文件系统的一些扩展属性,如果所需的文件系统需要一些额外的扩展属性,则可以添加上对XattrSupport的继承。 其成员主要有: public static final int XATTR_CREATE = 0x1; public int getxattrsize(String path, String name, FuseSizeSetter s
-
接下来的时间里作者将对fuse包进行逐一分析, 首先分析FilesystemConstants接口,该接口非常简单,里面定义了只读,只写,读写状态对应的代码。 public static final int O_RDONLY = 00; public static final int O_WRONLY = 01; public static final int O_RDWR = 02;
-
FakeFilesystem类继承自Filesystem3, XattrSupport,具体功能没有搞明白,好像是实现了一个模拟的文件系统。
-
本文向大家介绍删除MySQL重复数据的方法,包括了删除MySQL重复数据的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了删除MySQL重复数据的方法。分享给大家供大家参考。具体方法如下: 项目背景 在最近做的一个linux性能采集项目中,发现线程的程序入库很慢,再仔细定位,发现数据库里面很多冗余数据。因为在采集中,对于同一台设备,同一个时间点应该只有一个数据,然而,数据库中存入了多个
-
本文向大家介绍Oracle删除重复的数据,Oracle数据去重复,包括了Oracle删除重复的数据,Oracle数据去重复的使用技巧和注意事项,需要的朋友参考一下 Oracle 数据库中查询重复数据: select * from employee group by emp_name having count (*)>1; Oracle 查询可以删除的重复数据 select t1.* from
-
本文向大家介绍Mysql删除重复的数据 Mysql数据去重复,包括了Mysql删除重复的数据 Mysql数据去重复的使用技巧和注意事项,需要的朋友参考一下 MySQL数据库中查询重复数据 select * from employee group by emp_name having count (*)>1; Mysql 查询可以删除的重复数据 select t1.* from employee
-
然而,当我运行foreach循环时,它运行了几分钟就崩溃了 最初的数据库mydb有0.173GB,现在是0.368GB 你知道出什么问题了吗? 所以这次看起来很管用,但为什么'mydb'变大了呢?
-
本文向大家介绍MySQL中删除重复数据的简单方法,包括了MySQL中删除重复数据的简单方法的使用技巧和注意事项,需要的朋友参考一下 MYSQL里有五百万数据,但大多是重复的,真实的就180万,于是想怎样把这些重复的数据搞出来,在网上找了一圈,好多是用NOT IN这样的代码,这样效率很低,自己琢磨组合了一下,找到一个高效的处理方式,用这个方式,五百万数据,十来分钟就全部去除重复了,请各位参考。 第一
-
我有2个数据帧,和,有一个列(和其他非重要的)。 我想在中删除包含已在中的电子邮件的行。 我该怎么做?
-
问题内容: 有没有一种有效的方法使用python从此数据中删除重复的“ person_id”字段?在这种情况下,只需保持第一次出现。 应成为: 问题答案: 假设您的JSON是有效语法,并且您确实在请求帮助,因为您将需要执行以下操作 如果要始终保留第一次出现,则需要执行以下操作
-
当我的用户使用我的应用程序时,数据会发送到Firebase,但我只希望数据在删除之前存储60秒。 如何在服务器端60秒后自动删除存储在Firebase上的数据并自动更新我的RecycleView客户端?