
XLearning 是奇虎 360 开源的一款支持多种机器学习、深度学习框架调度系统。基于 Hadoop Yarn 完成了对 TensorFlow、MXNet、Caffe、Theano、PyTorch、Keras、XGBoost 等常用框架的集成,同时具备良好的扩展性和兼容性。
架构设计
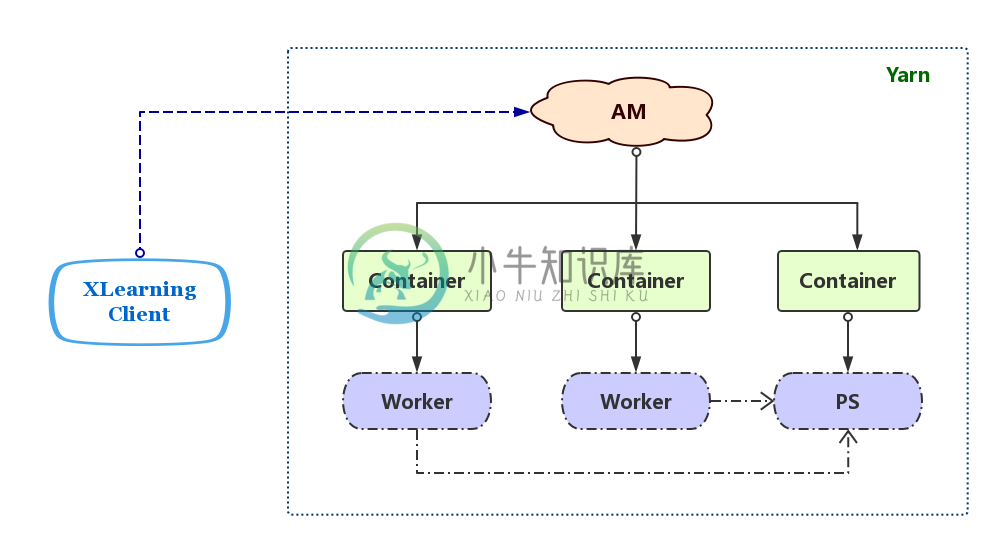
XLearning 系统包括三种组件:
Client:XLearning 客户端,负责启动作业及获取作业执行状态;
ApplicationMaster(AM):负责输入数据分片、启动及管理 Container、执行日志保存等;
Container:作业的实际执行者,负责启动 Worker 或 PS(Parameter Server)进程,监控并向 AM 汇报进程状态,上传作业的输出等。对于 TensorFlow 类型作业,还负责启动 TensorBoard 服务。
功能特性
1 支持多种深度学习框架
支持 TensorFlow、MXNet 分布式和单机模式,支持所有的单机模式的深度学习框架,如 Caffe、Theano、PyTorch 等。对于同一个深度学习框架支持多版本和自定义版本。
2 基于 HDFS 的统一数据管理
训练数据和模型结果统一采用 HDFS 进行存储,用户可通过 --input-strategy 或 xlearning.input.strategy 指定输入数据所采用的读取方式。目前,XLearning 支持如下三种 HDFS 输入数据读取方式:
Download: AM 根据用户在提交脚本中所指定的输入数据参数,遍历对应 HDFS 路径下所有文件,以文件为单位将输入数据平均分配给不同 Worker 。在 Worker 中的执行程序对应进程启动之前,Worker 会根据对应的文件分配信息将需要读取的 HDFS 文件下载到本地指定路径;
Placeholder: 与 Download 模式不同,Worker 不会直接下载 HDFS 文件到本地指定路径,而是将所分配的 HDFS 文件列表通过环境变量
INPUT_FILE_LIST传给 Worker 中的执行程序对应进程。执行程序从环境变量os.environ["INPUT_FILE_LIST"]中获取需要处理的文件列表,直接对 HDFS 文件进行读写等操作。该模式要求深度学习框架具备读取 HDFS 文件的功能,或借助第三方模块库如 pydoop 等。InputFormat: XLearning 集成有 MapReduce 中的 InputFormat 功能。在 AM 中,根据 “split size” 对所提交脚本中所指定的输入数据进行分片,并均匀的分配给不同 Worker 。在 Worker 中,根据所分配到的分片信息,以用户指定的 InputFormat 类读取数据分片,并通过管道将数据传递给 Worker 中的执行程序进程。
同输入数据读取类似,用户可通过--output-strategy或xlearning.output.strategy指定输出结果的保存方式。XLearning 支持如下两种结果输出保存模式:
Upload: 执行程序结束后,Worker 根据提交脚本中输出数据参数,将本地输出路径保存文件上传至对应 HDFS 路径。为方便用户在训练过程中随时将本地输出上传至 HDFS,XLearning 系统在作业执行 Web 界面提供对输出模型的当前状态主动保存的功能,详情请见“可视化界面”说明部分;
OutputFormat: XLearning 集成有 MapReduce 中的 OutputFormat 功能。在训练过程中, Worker 根据指定的 OutputFormat 类,将结果输出至 HDFS 。
3 可视化界面
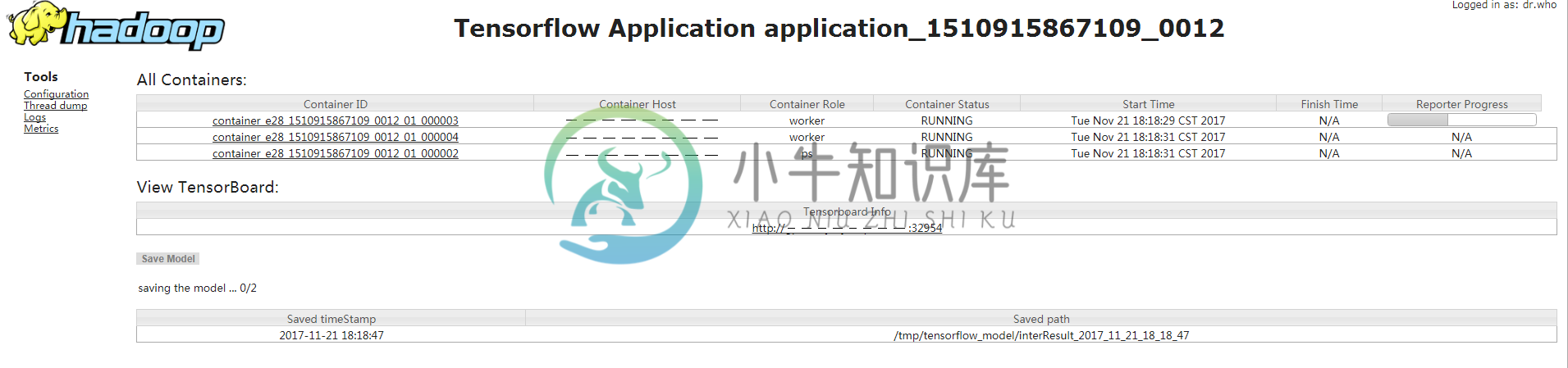
作业运行界面大致分为三部分:
All Containers:显示当前作业所含 Container 列表及各 Container 对应信息,如 Contianer ID、所在机器(Container Host)、所属类型(Container Role)、当前执行状态(Container Status)、开始时间(Start Time)、结束时间(Finish Time)、执行进度(Reporter Progress)。其中,点击 Container ID 超链接可查看该 Container 运行的详细日志;
View TensorBoard:当作业类型为 TensorFlow 时,可点击该链接直接跳转到 TensorBoard 页面;
Save Model:当作业提交脚本中“--output”参数不为空时,用户可通过
Save Model按钮,在作业执行过程中,将本地输出当前模型训练结果上传至 HDFS 。上传成功后,显示目前已上传的模型列表。
如下图所示:
4 原生框架代码的兼容性
TensorFlow 分布式模式支持 “ClusterSpec” 自动分配构建,单机模式和其他深度学习框架代码不用做任何修改即可迁移到 XLearning 上。
-
最近发现了一个做事很认真的做算法同事,身上很多优点值得我学习,推荐使用了一种360的开源工具,可以将tensoeflow提交至yarn里面。这个工具感觉解决了很多问题。我这个人比较懒,大部分工作都是我那个同事研究成功的,然后我坐享其成,等着验证结果。特此在这里将他的成果记录下来: 参考网址: https://github.com/Qihoo360/XLearning/blob/master/REA
-
主要内容 课程列表 专项课程学习 辅助课程 论文专区 课程列表 课程 机构 参考书 Notes等其他资料 卷积神经网络视觉识别 Stanford 暂无 链接 神经网络 Tweet 暂无 链接 深度学习用于自然语言处理 Stanford 暂无 链接 自然语言处理 Speech and Language Processing 链接 专项课程学习 下述的课程都是公认的最好的在线学习资料,侧重点不同,但推
-
Google Cloud Platform 推出了一个 Learn TensorFlow and deep learning, without a Ph.D. 的教程,介绍了如何基于 Tensorflow 实现 CNN 和 RNN,链接在 这里。 Youtube Slide1 Slide2 Sample Code
-
本文向大家介绍深度学习调参经验?相关面试题,主要包含被问及深度学习调参经验?时的应答技巧和注意事项,需要的朋友参考一下 参数初始化,uniform均匀分布初始化,normal高斯分布初始化 数据预处理,进行归一化,有几种常用方法 梯度归一,算出来的梯度除以minibatch size 还有梯度裁剪,限制梯度上限,dropout防过拟合,一般sgd,选择0.1的学习了,衰减型的,激活函数选择relu
-
现在开始学深度学习。在这部分讲义中,我们要简单介绍神经网络,讨论一下向量化以及利用反向传播(backpropagation)来训练神经网络。 1 神经网络(Neural Networks) 我们将慢慢的从一个小问题开始一步一步的构建一个神经网络。回忆一下本课程最开始的时就见到的那个房价预测问题:给定房屋的面积,我们要预测其价格。 在之前的章节中,我们学到的方法是在数据图像中拟合一条直线。现在咱们不
-
深度学习的总体来讲分三层,输入层,隐藏层和输出层。如下图: 但是中间的隐藏层可以是多层,所以叫深度神经网络,中间的隐藏层可以有多种形式,就构成了各种不同的神经网络模型。这部分主要介绍各种常见的神经网络层。在熟悉这些常见的层后,一个神经网络其实就是各种不同层的组合。后边介绍主要基于keras的文档进行组织介绍。
-
Python 是一种通用的高级编程语言,广泛用于数据科学和生成深度学习算法。这个简短的教程介绍了 Python 及其库,如 Numpy,Scipy,Pandas,Matplotlib,像 Theano,TensorFlow,Keras 这样的框架。
-
你拿起这本书的时候,可能已经知道深度学习近年来在人工智能领域所取得的非凡进展。在图像识别和语音转录的任务上,五年前的模型还几乎无法使用,如今的模型的表现已经超越了人类。
-
全程拷打项目(因为项目是和tf与机器学习相关的) 手写conv2D的计算函数(因为项目里有个conv3D相关的tf算子,但是没有写出来) 手写nms算法(写得很慢,之前又因为也是做项目,没有仔细研究源码) 之前使用opencl比较多,cuda使用得比较少,而且机器学习相关的算法也不是很精通,第二天就挂了