
Zstandard(zstd)是 Facebook 开源的一种快速无损压缩算法,以 zlib 级为目标的实时压缩场景和更好的压缩比。它提供了非常宽范围的压缩/速度折衷,同时支持非常快的解码器。它还为小数据提供了一种特殊模式,称为字典压缩,并且可以从任何样本集创建字典。
Zstandard 是一种新的数据压缩算法,改进了 Facebook 的存储要求。
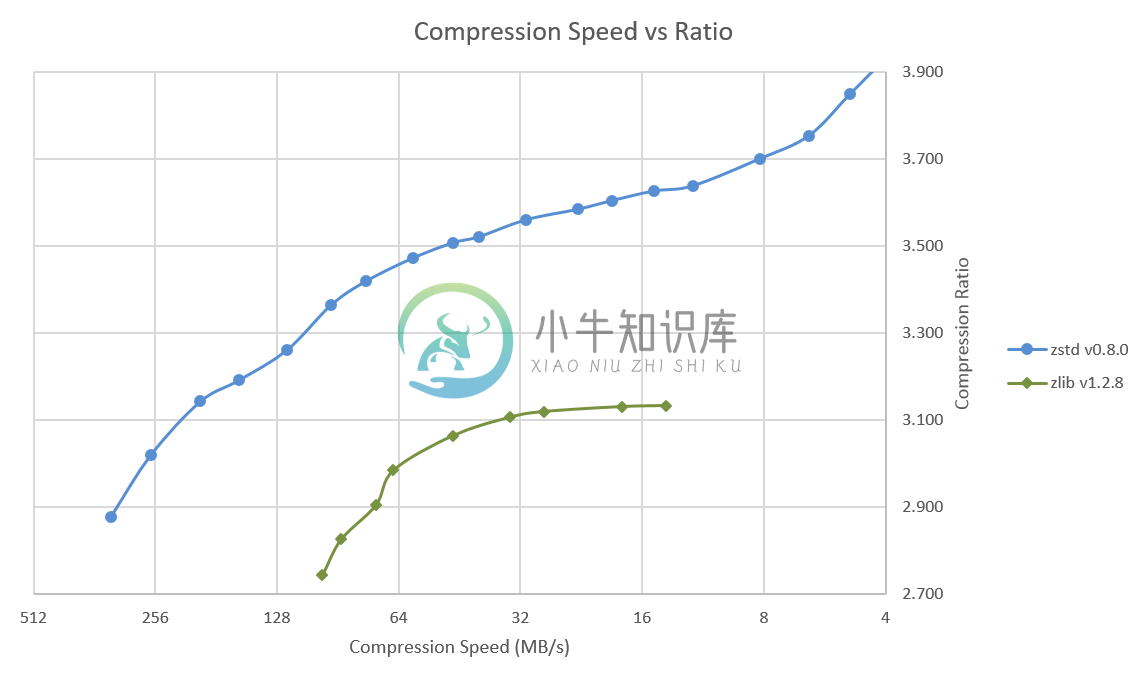
压缩速度对比:
Zstandard 采用双授权协议:BSD 和 GPLv2
-
欢迎访问我的个人博客 ,原文链接 简介 Zstandard(缩写为Zstd)是由Facebook的Yann Collet开发的一个无损数据压缩算法。Zstandard在设计上与DEFLATE(.zip、gzip)算法有着差不多的压缩比,但有更高的压缩和解压缩速度。 Zstandard使用字典算法(LZ77)结合熵编码法的有限状态熵(tANS)。—–Wikipedia GitHub上的zstd页面
-
Flink SQL ClassNotFoundException: org.apache.commons.compress.compressors.zstandard.ZstdCompressorIn
1. 现象 在 Flink SQL 中使用 FileSystem Connector 以 CSV 格式读取本地 csv 文件时,抛出如下异常: Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/compress/compressors/zstandard/ZstdCompressorInput
-
为方便在windows环境下使用Zstandard (zstd) 库,基于Zstandard (zstd) 1.5.2版本,运用visual studio IDE环境,搭建了Zstandard (zstd) 的编译环境,可以方便生成静态库、动态库、头文件等。 包含有:visual studio 2010、visual studio 2015、visual studio 2017、visual
-
zstd 1.4.0 发布了,zstd 又叫 Zstandard,它是一种快速无损压缩算法,主要应用于 zlib 级别的实时压缩场景,并且具有更好的压缩比。zstd 还可以以压缩速度为代价提供更强的压缩比,速度与压缩权衡可通过小增量进行配置。 高级 API 此版本主要关注于高级 API 的稳定性,高级 API 提供了一种在兼容 API 和 ABI 的情况下,在压缩和解压期间设置特定参数的方法。例如
-
flink报错:org/apache/commons/compress/compressors/zstandard/ZstdCompressorInputStream pom.xml添加下面依赖 <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-compress</artifactId>
-
zstd 1.4.1 发布了,zstd 又叫 Zstandard,它是一种快速无损压缩算法,主要应用于 zlib 级别的实时压缩场景,并且具有更好的压缩比。zstd 还可以以压缩速度为代价提供更强的压缩比,速度与压缩权衡可通过小增量进行配置。 此版本是一个维护版本,它修复了一些错误,包括只能在小众用例中触发的罕见数据损坏错误,当执行以下所有操作时会出现该 bug:使用多线程模式,重叠大小>= 51
-
流式输入API stream_writer(fh)允许您将{em1}$stream数据放入压缩器。 返回的实例实现了io.RawIOBase接口。只有方法 涉及写作的东西会有用的。 stream_writer()的参数必须有一个write(data)方法。作为 压缩数据可用,write()将使用压缩 数据作为它的论据。许多常见的python类型实现write(),包括 打开文件句柄和io.Byte
-
今天,Facebook 宣布其开源了自家的 Zstandard 压缩算法。这个无损的压缩技术致力于取代已存在的诸如 zlib 这种依赖过时的技术 Deflate compression algorithm 的库。除了 Zstandard 压缩算法,Facebook 把 MyRocks 存储引擎也开源了,MyRocks 现在被 Facebook 用于提升自家 MySQL 数据库的存储效率。 Face
-
有一种“带路径压缩的加权快速联合”算法。 代码: 问题: > 路径压缩是如何工作的意味着我们只到达节点的第二个祖先,而不是根。 包含从 到 整数。如何帮助我们知道集合中元素的数量? 有人能帮我澄清一下吗?
-
我正在为联合/查找结构实现快速联合算法。在“Java中的算法”一书网站上给出的实现中,普林斯顿实现在实现路径压缩(在方法中)时无法保持树的大小不变。这不应该对算法产生不利影响吗?还是我错过了什么?另外,如果我是对的,我们将如何修改大小数组?
-
我正在学习联合/查找结构的“加权快速联合与路径压缩”算法。普林斯顿edu网站详细解释了该算法。这是Java的实现: 但就像网站提到它的性能一样: 定理:从空数据结构开始,任何 M 并集序列和对 N 个对象的查找操作都需要 O(N M lg* N) 时间。 证明非常困难。 但是算法仍然很简单! 但我仍然很好奇迭代对数lg*n是如何产生的。它是如何推导出来的?有人可以证明它或只是以直观的方式解释它吗?
-
我有一个项目,我必须实现一个带有路径压缩算法的加权快速并集。在看到其他一些源代码后,我最终得到了这个: 分配给我的任务是正确完成以下方法: int find(int v) void unite(int v,int u) setCount(int v) 嗯,算法似乎很慢,我找不到合适的解决方案。
-
根据Princeton booksite,带有路径压缩的加权快速联合将10^9联合对10^9对象的操作时间从一年减少到大约6秒。这个数字是怎么得出的?当我在10^8操作中运行下面的代码时,我的运行时间是61s。
-
我希望使用log4j2 RollingFileAppender和定制的压缩算法(ZStd)。 目前为止支持的压缩算法似乎是FileExtension枚举(zip,gz,bz2,...)中的压缩算法,请参见https://github.com/apache/logging-log4j2/blob/efa64bfad3f67c5b5fed6b25d65ef5ca2212011b/log4j-core/
-
我试图找到一种压缩算法,我可以使用它来编码一个blob,只使用16个固定长度的符号(0b0000-0b1111)。 在没有任何压缩的情况下,我可以使用这16个符号对其各自的位值进行编码(例如,符号5(0b0101)对位0101进行编码,因此如果我的blob是100位长,我需要25个符号来表示它-但这样做不会提供压缩。 我认为我需要的是一个反向霍夫曼(在某种意义上,代码是固定长度的,但它代表可变长度
-
DEFLATE 是同时使用了哈夫曼编码(Huffman Coding)与 LZ77 算法的一个无损数据压缩算法,是一种压缩数据流的算法。任何需要流式压缩的地方都可以用。目前 zip 压缩文件默认使用的就是该算法。 关于算法的原理,以及 哈夫曼编码(Huffman Coding)与 LZ77 算法,感兴趣的读者可以查询相关资料,这里推荐 GZIP压缩原理分析——第五章 Deflate算法详解 序列文