
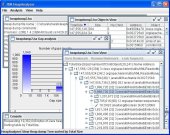
HeapAnalyzer 是 IBM 的一个用来分析 Java 程序的内存堆使用情况的图形化工具。
-
在故障定位(尤其是out of memory)和性能分析的时候,经常会用到一些文件来帮助我们排除代码问题。这些文件记录了JVM运行期间的内存占用、线程执行等情况,这就是我们常说的dump文件。常用的有heap dump和thread dump(也叫javacore,或java dump)。我们可以这么理解:heap dump记录内存信息的,thread dump是记录CPU信息的。 heap d
-
heapAnalyzer使用教程 heapAnalyzer是ibm的一个内存分析工具,当服务器内存负载出现问题时可以生成堆的dump文件,然后通过heapanalyzer可以堆dump文件进行分析,分析内存泄漏对象,或者那些对象占用大量内存。 jmap命令:例如jvm进程号为3331 jmap -heap 3331:查看java 堆(heap)使用情况 jmap -histo 3331:查看堆内存
-
官方文档:http://www-01.ibm.com/support/docview.wss?uid=swg27006624&aid=1 使用:http://blog.csdn.net/zongxiao08/article/details/8600237 http://blog.csdn.net/neu_lcj77/article/details/71553679 手动生成dump(步骤略
-
我想了解为什么多次动态分配调用的数据比直接在代码中指定的或通过的单个调用分配的数据使用如此多的内存。 例如,我用C编写了以下两个代码: 测试1.c:int x用malloc分配 我在这里没有使用free来保持简单。当程序等待交互时,我查看另一个终端中的顶级功能,它向我显示了以下内容: test2. c: int x不是动态分配的 顶部显示: 我还编写了第三个代码,其结果与test2相同,我在tes
-
我使用5.6.21-70.0进行性能测试。 当我跑步时 mysqlslp-a--并发=40--查询次数1000次--迭代=500次--引擎=innodb--debug-info-utest-p 做一些性能测试,ram增长超过最大内存使用量,永不释放 当完成mysqlslap时,内存显示使用78% 我有1G物理内存,不使用交换 KiB Mem:总共1016656个,使用953808个,免费62848
-
问题内容: 我知道Valgrind,但它只是检测内存管理问题。我要搜索的是一个概述的工具,程序的哪些部分确实消耗了多少内存。带有树形图的图形表示(就像KCachegrind对Callgrind所做的那样)会很酷。 我在Linux机器上工作,所以Windows工具对我没有太大帮助。 问题答案: 使用massif,这是Valgrind工具的一部分。massif- visualizer 可以帮助您绘制数
-
问题内容: 使用以下Java选项启动Apache Tomcat(Atlassian Confluence)实例: 但是,我看到启动后,它很快就耗尽了虚拟服务器上可用的1GB内存中的大部分。 总消耗的内存(堆+ PermGen)是否不应该保持在使用- Xmx指定的值以下?这引起的问题之一是我无法使用关闭脚本关闭服务器,因为它试图生成具有256MB内存的JVM,该JVM因不可用而失败。 问题答案: T
-
问题内容: 每次从stdin读取字母“ u”时,此代码段将分配2Gb,并且在读取“ a”后将初始化所有分配的字符。 我在具有3Gb内存的linux虚拟机上运行此代码。在使用htop工具监视系统资源使用情况时,我已经意识到malloc操作不会反映在资源上。 例如,当我仅输入一次“ u”(即分配2GB的堆内存)时,我看不到htop中的内存使用量增加2GB。只有当我输入“ a”(即初始化)时,我才会看到
-
/redis/script/redis-sampler.rb 127.0.0.1 6379 0 10000 /redis/script/redis-audit.rb 127.0.0.1 6379 0 10000
-
问题内容: 我在此处的注释中读到,更改列表时执行切片分配具有更高的内存效率。例如, 应该比 因为前者会替换现有列表中的元素,而后者会创建一个新列表并重新绑定到该新列表,从而将旧列表保留在内存中,直到可以对其进行垃圾回收为止。对两者进行基准测试以提高速度,后者则要快一些: 这就是我所期望的,因为重新绑定变量应该比替换列表中的元素更快。但是,我找不到任何支持内存使用声明的官方文档,也不确定如何进行基准
-
问题内容: 我想知道我的Python应用程序的内存使用情况,尤其想知道哪些代码块/部分或对象消耗了最多的内存。Google搜索显示商用的是(仅限)。 开源的是和。 我没有尝试过任何人,所以我想知道哪个是最好的考虑因素: 提供大多数细节。 我必须对我的代码做最少的修改或不做任何更改。 问题答案: 堆很容易使用。在代码中的某些时候,你必须编写以下代码: 这将为你提供如下输出: 你还可以从哪里找到对象的