
Tera 是一个高性能、可伸缩的数据库系统,被设计用来管理搜索引擎万亿量级的超链与网页信息。为实现数据的实时分析与高效访问,我们使用按行键、列名和时间戳全局排序的三维数据模型组织数据,使用多级Cache系统,充分利用新一代服务器硬件大内存、SSD盘和万兆网卡的性能优势,做到模型灵活的同时,实现了高吞吐与水平扩展。
特性
全局有序
热点自动分片
数据强一致
多版本,自动垃圾收集
按列存储,支持内存表
动态schema
支持表格快照
高效随机读写
数据模型
Tera使用了bigtable的数据模型,可以将一张表格理解为这样一种数据结构:
map<RowKey, map<ColummnFamily:Qualifier, map> >
其中RowKey、ColumnFamily、Qualifier和Value是字符串,Timestamp是一个64位整形。ColumnFamliy需要建表时指定,是访问控制、版本保留等策略的基本单位。
系统架构
系统主要由Tabletserver、Master和ClientSDK三部分构成。其中Tabletserver是核心服务器,承载着所有的数据管理与访问;Master是系统的仲裁者,负责表格的创建、schema更新与负载均衡;ClientSDK包含供管理员使用的命令行工具teracli和给用户使用的SDK。 表格被按RowKey全局排序,并横向切分成多个Tablet,每个Tablet负责服务RowKey的一个区间,表格又被纵向且分为多个LocalityGroup,一个Tablet的多个Localitygroup在物理上单独存储,可以选择不同的存储介质,以优化访问效率。
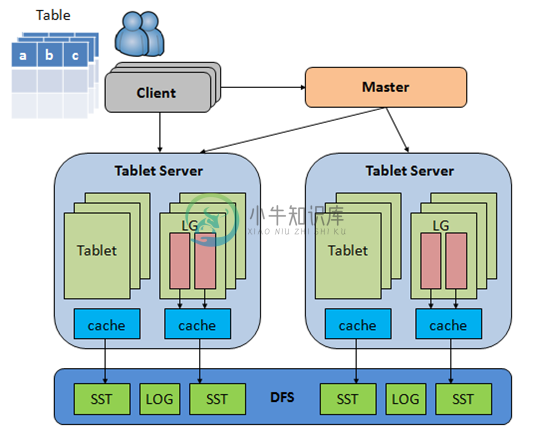
系统依赖
使用分布式文件系统(HDFS、NFS等)持久化数据与元信息
使用zookeeper选主与协调
使用Sofa-pbrpc实现跨进程通信
系统构建
参考BUILD
使用示例
参考wiki
反馈与技术支持
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
万法皆空,因果不空。 随着摩尔定律碰到瓶颈,越来越多的系统要依靠分布式集群架构来实现海量数据处理和可扩展计算能力。 区块链首先是一个分布式系统。 中央式结构改成分布式系统,碰到的第一个问题就是一致性的保障。 很显然,如果一个分布式集群无法保证处理结果一致的话,那任何建立于其上的业务系统都无法正常工作。 本章将介绍分布式系统中一些核心问题的来源以及相关的工作。
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
邂逅相遇 网络延迟 存之为吾 无食我数 —— Kyle Kingsbury, Carly Rae Jepsen 《网络分区的危害》(2013年) [TOC] 最近几章中反复出现的主题是,系统如何处理错误的事情。例如,我们讨论了副本故障切换(“处理节点中断”),复制延迟(“复制延迟问题”)和事务控制(“弱隔离级别”)。当我们了解可能在实际系统中出现的各种边缘情况时,我们会更好地处理它们。