
TFS(Taobao FileSystem)是一个高可扩展、高可用、高性能、面向互联网服务的分布式文件系统,其设计目标是支持海量的非结构化数据。
目前,国内自主研发的文件系统可谓凤毛麟角。淘宝在这一领域做了有效的探索和实践,Taobao File System(TFS)作为淘宝内部使用的分布式文件系统,针对海量小文件的随机读写访问性能做了特殊优化,承载着淘宝主站所有图片、商品描述等数据存储。
文章首先概括了TFS的特点:最近,淘宝核心系统团队工程师楚材(李震)在其官方博客上撰文(《TFS简介》,以下简称文章)简要介绍了TFS系统的基本情况,引起了社区的关注。
完全扁平化的数据组织结构,抛弃了传统文件系统的目录结构。
在块设备基础上建立自有的文件系统,减少EXT3等文件系统数据碎片带来的性能损耗。
单进程管理单块磁盘的方式,摒除RAID5机制。
带有HA机制的中央控制节点,在安全稳定和性能复杂度之间取得平衡。
尽量缩减元数据大小,将元数据全部加载入内存,提升访问速度。
跨机架和IDC的负载均衡和冗余安全策略。
完全平滑扩容。
当前,TFS在淘宝的应用规模达到“数百台PCServer,PB级数据量,百亿数据级别”,对于其性能参数,楚材透漏:
TFS在淘宝的部署环境中前端有两层缓冲,到达TFS系统的请求非常离散,所以TFS内部是没有任何数据的内存缓冲的,包括传统文件系统的内存缓冲也不存在......基本上我们可以达到单块磁盘随机IOPS(即I/O per second)理论最大值的60%左右,整机的输出随盘数增加而线性增加。
TFS的逻辑架构图1如下所示:
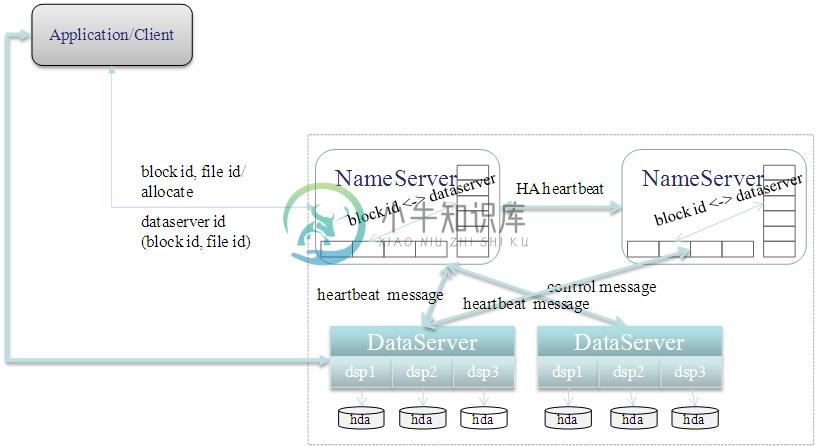
图1. TFS逻辑架构图(来源:淘宝核心系统团队博客)
楚材结合架构图做了进一步说明:
-
TFS尚未对最终用户提供传统文件系统API,需要通过TFSClient进行接口访问,现有JAVA、JNI、C、PHP的客户端
-
TFS的NameServer作为中心控制节点,监控所有数据节点的运行状况,负责读写调度的负载均衡,同时管理一级元数据用来帮助客户端定位需要访问的数据节点
-
TFS的DataServer作为数据节点,负责数据实际发生的负载均衡和数据冗余,同时管理二级元数据帮助客户端获取真实的业务数据。
-
https://www.cnblogs.com/hf-z/p/5842579.html
-
TFS 从2005,2008已经发展到目前的2010,你还在用VSS? out了。 TFS的功能远远多于源代码管理,这篇文档 用一个专门的视角来介绍TFS:从VSS到TFS
-
新建TFS之后,遇到很多问题。 1. 项目“绑定”到一个tfs的collection之后,如何解绑? File--->Source Control ----> Advanced ---> Change Source Control , 可以解除和tfs的关系, 但是似乎无法解除 collection 不让 TFS_A/defaultcollection 只会变成 TFS_B/defaultcol
-
1. win2003+sp1 2. ghost os 3. sql2005+sp1 4. .net Framework 3.0 5. wss 3.0 6. TFS
-
TFS 本身有一个 test_batch_write性能测试工具。通过ssh到服务器跑工具网卡流量一直上不去。把日志重定向到文件后问题解决,原来ssh后屏幕打印日志对性能测试影响挺大的。 参考: http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=20196318&id=3611197
-
运行TFS 启动nameserver 执行scripts目录下的tfs ./tfs start_ns 启动dataserver 现有TFS可以在一台服务器上启动多个DataServer进程。一般每个DataServer进程负责一个磁盘。 将数据盘格式化成EXT4文件系统,并挂载到/data/tfs1至/data/tfs(i),其中i为磁盘号。 启动步骤: 一、存储区预分配。执行scripts下的s
-
获取TFS C++客户端 TFS C++ 客户端库包含一些头文件和一个libtfsclient.so的共享库文件。 可以直接通过编译源码获取。 TFS C++客户端使用说明 Tfs客户端提供了TfsClient类作为TFS文件操作的接口。类TfsClient在使用前需要初始化,初始化完成之后就可以多次打开不同的Tfs文件,对它们进行读写。Tfs客户端提供了打开/关闭、读/写、删除/反删除等主要的操
-
TFS的安装,部署请参考TFS文档-安装篇、TFS文档-部署篇,本文主要介绍如何使用TFS提供的工具来管理、运维、诊断集群,主要包括tfstool、ssm、ds_client、admintool等,安装tfs后,所有的工具都在tfs-home/bin目录下,每个命令都包含help命令,用于打印帮助信息。 tfstool 提供写文件、读文件、删除文件的命令支持,使用方式如下: tfstool -s
-
服务器软件环境:TFS 2010。 故障: 不能登录。 现象:昨天TFS还能正常工作,今天就无法登录。 原因:登上装有TFS的服务器, 1 发现C盘空间不足。原来是C:\Program Files\Common Files\Microsoft Shared\web server extensions\12\LOGS 下的日志文件过大。 2 服务器时间被改动,小时,分,秒没有问题。但是年份少了一年。
-
下载windows版本的git客户端和github desktop https://desktop.githubusercontent.com/releases/1.4.3-f0beb6ed/GitHubDesktopSetup.exe https://github-production-release-asset-2e65be.s3.amazonaws.com/23216272/081b0800
-
TFS今天刚刚做好的。 Mark一下,坐个记录 1. 搭建TFS服务器. 详见google TFS服务器环境: Centos Linux version 2.6.32-431.el6.x86_64 (mockbuild@c6b8.bsys.dev.centos.org) (gcc version 4.4.7 20120313 (Red Hat 4.4.7-4) (GCC) ) #1 SMP Fri
-
Operating systems TFS can be installed on a Windows server or client operating system. TFS 2017 and TFS 2018 only support 64-bit operating systems. For earlier versions of TFS, you can use either the
-
我是64位UBUNTU,gcc 4.7,官方说是要4.1.2. 但不知道怎么回事,我就硬是没有在机子上装成功GCC4.1.2,只好硬着头皮再GCC 4.7上继续了。 安装libuuid-devel,zlib-devel,mysql-devel三个开发包。 ubuntu 上 mysql-devel 库的名字叫 libmysqld-dev,别弄错了 sudo apt-get install lib
-
数据存储容量的问题。 数据读写速度的问题。 数据可靠性的问题。 几种常见 RAID 的对比|名称|优点|缺点| |------|------|------| |RAID 0|使用 N 块磁盘的 RAID 0,将数据从内存写入磁盘时,将数据分成 N 块,并发写入,读取同理。所以,读写速度是单盘的 N 倍。|任何一块盘损坏,数据完整性破坏,数据不可用。| |RAID 1|数据写入磁盘时,将一份数据同时
-
一、介绍 HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构 HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成: NameNode : 负责执行有关 文件系统命名空间 的操作,例如打开,
-
Hadoop分布式文件系统(HDFS)的设计主旨,在于对超大规模数据集提供可靠的存储功能,并对用户应用程序提供高带宽的输入输出数据流。在大型的集群里,上千台服务器均可直接参与到数据存储和应用程序任务执行。通过多服务器,分布式的存储和计算,计算资源的规模能够按照需要增长,并兼顾在各种规模上经济适用性。 本文主要描述了HDFS的架构,并以Yahoo!企业数据服务为例,介绍了如何使用HDFS系统管理高达
-
原文链接:http://www.aosabook.org/en/hdfs.html 作者:Robert Chansler, Hairong Kuang, Sanjay Radia, Konstantin Shvachko与Suresh Srinivas HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)的设计宗旨,是可靠地存储极大的数据集,并将其以
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
被别人指出问题时,别管别人能不能做到,看别人说的对不对,然后完善自己。别人能不能做到是别人的事情,自己能不能做到关系到自己能否发展的更好。——hustlihaifeng Go语言号称是互联网时代的C语言。现在的互联网系统已经不是以前的一个主机搞定一切的时代,互联网时代的后台服务由大量的分布式系统构成,任何单一后台服务器节点的故障并不会导致整个系统的停机。同时以阿里云、腾讯云为代表的云厂商崛起标志着
-
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。要理解HDFS的内部工作原理,首先要理解什么是分布式文件系统。 1.分布式文件系统 多台计算机联网协同工作(有时也称为一个集群)就像单台系统一样解决某种问题,这样的系统我们称之为分布式系统。 分布
-
本文向大家介绍Java访问Hadoop分布式文件系统HDFS的配置说明,包括了Java访问Hadoop分布式文件系统HDFS的配置说明的使用技巧和注意事项,需要的朋友参考一下 配置文件 m103替换为hdfs服务地址。 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDF