
HugeGraph 是一款易用、高效、通用的开源图数据库系统(Graph Database), 实现了 Apache TinkerPop3 框架及完全兼容 Gremlin 查询语言, 具备完善的工具链组件,助力用户轻松构建基于图数据库之上的应用和产品。HugeGraph 支持百亿以上的顶点和边快速导入,并提供毫秒级的关联关系查询能力(OLTP), 并可与 Hadoop、Spark 等大数据平台集成以进行离线分析(OLAP)。
HugeGraph 典型应用场景包括深度关系探索、关联分析、路径搜索、特征抽取、数据聚类、社区检测、 知识图谱等,适用业务领域有如网络安全、电信诈骗、金融风控、广告推荐、社交网络和智能机器人等。
本系统的主要应用场景是解决百度安全事业部所面对的反欺诈、威胁情报、黑产打击等业务的图数据存储和建模分析需求,在此基础上逐步扩展及支持了更多的通用图应用。
主要特性
HugeGraph 支持在线及离线环境下的图操作,支持批量导入数据,支持高效的复杂关联关系分析,并且能够与大数据平台无缝集成。 HugeGraph 支持多用户并行操作,用户可输入 Gremlin 查询语句,并及时得到图查询结果,也可在用户程序中调用 HugeGraph API 进行图分析或查询。
本系统具备如下特点:
- 易用:HugeGraph 支持 Gremlin 图查询语言与 Restful API,同时提供图检索常用接口,具备功能齐全的周边工具,轻松实现基于图的各种查询分析运算。
- 高效:HugeGraph 在图存储和图计算方面做了深度优化,提供多种批量导入工具,轻松完成百亿级数据快速导入,通过优化过的查询达到图检索的毫秒级响应。支持数千用户并发的在线实时操作。
- 通用:HugeGraph 支持 Apache Gremlin 标准图查询语言和 Property Graph 标准图建模方法,支持基于图的 OLTP 和 OLAP 方案。集成 Apache Hadoop 及 Apache Spark 大数据平台。
- 可扩展:支持分布式存储、数据多副本及横向扩容,内置多种后端存储引擎,也可插件式轻松扩展后端存储引擎。
- 开放:HugeGraph 代码开源(Apache 2 License),客户可自主修改定制,选择性回馈开源社区。
本系统的功能包括但不限于:
- 支持从多数据源批量导入数据(包括本地文件、HDFS 文件、MySQL 数据库等数据源),支持多种文件格式导入(包括 TXT、CSV、JSON 等格式)
- 具备可视化操作界面,可用于操作、分析及展示图,降低用户使用门槛
- 优化的图接口:最短路径(Shortest Path)、K 步连通子图(K-neighbor)、K步到达邻接点(K-out)、个性化推荐算法 PersonalRank 等
- 基于 Apache TinkerPop3 框架实现,支持 Gremlin 图查询语言
- 支持属性图,顶点和边均可添加属性,支持丰富的属性类型
- 具备独立的 Schema 元数据信息,拥有强大的图建模能力,方便第三方系统集成
- 支持多顶点 ID 策略:支持主键 ID、支持自动生成 ID、支持用户自定义字符串 ID、支持用户自定义数字 ID
- 可以对边和顶点的属性建立索引,支持精确查询、范围查询、全文检索
- 存储系统采用插件方式,支持 RocksDB、Cassandra、ScyllaDB、HBase、MySQL、PostgreSQL、Palo 以及 InMemory 等
- 与 Hadoop、Spark GraphX 等大数据系统集成,支持 Bulk Load 操作
- 支持高可用 HA、数据多副本、备份恢复、监控等
组件
- HugeGraph-Server: HugeGraph-Server 是 HugeGraph 项目的核心部分,包含 Core、Backend、API 等子模块;
- Core:图引擎实现,向下连接 Backend 模块,向上支持 API 模块;
- Backend:实现将图数据存储到后端,支持的后端包括:Memory、Cassandra、ScyllaDB、RocksDB、HBase 及 MySQL,用户根据实际情况选择一种即可;
- API:内置 REST Server,向用户提供 RESTful API,同时完全兼容 Gremlin 查询。
- HugeGraph-Client:HugeGraph-Client 提供了 RESTful API 的客户端,用于连接 HugeGraph-Server,目前仅实现 Java 版,其他语言用户可自行实现;
- HugeGraph-Loader:HugeGraph-Loader 是基于 HugeGraph-Client 的数据导入工具,将普通文本数据转化为图形的顶点和边并插入图形数据库中;
- HugeGraph-Spark:HugeGraph-Spark 能在图上做并行计算,例如 PageRank 算法等;
- HugeGraph-Studio:HugeGraph-Studio 是 HugeGraph 的 Web 可视化工具,可用于执行 Gremlin 语句及展示图;
- HugeGraph-Tools:HugeGraph-Tools 是 HugeGraph 的部署和管理工具,包括管理图、备份/恢复、 Gremlin 执行等功能。
界面展示
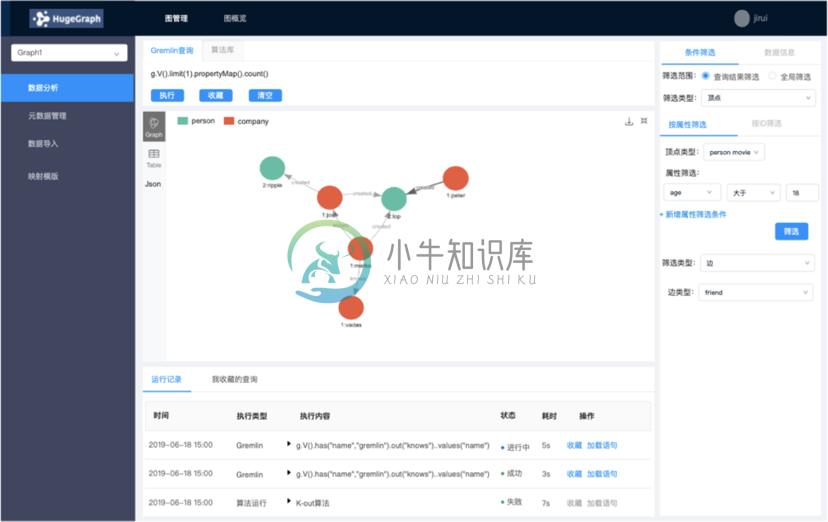
-
本文针对HugeGraph后端存储使用RocksDB时的参数配置进行梳理. HugeGraph的版本是0.11.2, RocksDB的参数配置类是:com.baidu.hugegraph.backend.store.rocksdb.RocksDBOptions,共有47个参数(RocksDB的参数真是多呀), 重点的参数已经标蓝色,具体如下: 如果想调整配置,请修改xxxgraph.propert
-
hugegraph使用 1 概述 HugeGraph-Server 是 HugeGraph 项目的核心部分,包含Core、Backend、API等子模块。 Core模块是Tinkerpop接口的实现,Backend模块用于管理数据存储,目前支持的后端包括:Memory、Cassandra、ScyllaDB以及RocksDB,API模块提供HTTP Server,将Client的HTTP请求转化为对
-
事务处理 索引
-
问题内容: 在数据库中建立适当的关系对数据完整性以外的其他功能没有帮助吗? 它们会改善还是阻碍性能? 问题答案: 我不得不说,适当的关系将比省略它们更好地帮助人们理解数据(或数据的意图),特别是因为维护它们的总成本非常低。 它们的存在不会影响性能,除非是在体系结构方面(正如其他人指出的那样,数据完整性有时会导致外键冲突,这可能会产生某些影响),但是IMHO的许多好处(如果正确使用,则不胜枚举)。
-
一、事务 概念 ACID AUTOCOMMIT 二、并发一致性问题 丢失修改 读脏数据 不可重复读 幻影读 三、封锁 封锁粒度 封锁类型 封锁协议 MySQL 隐式与显示锁定 四、隔离级别 未提交读(READ UNCOMMITTED) 提交读(READ COMMITTED) 可重复读(REPEATABLE READ) 可串行化(SERIALIZABLE) 五、多版本并发控制 基本思想 版本号 Un
-
数据库创建索引能够大大提高系统的性能。 第一,通过创建唯一性的索引,可以保证数据库表中每一行数据的唯一性。 第二,可以大大加快数据的检索速度,这也使创建索引的最主要的原因。 第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 第四,在使用分组和排序子句进行数据检索时,同样可以显著的减少查询中查询中分组和排序的时间。 第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,
-
在数据库原理中,关系运算包含 选择、投影、连接 这三种运算。相应的在SQL语句中也有表现,其中Where子句作为选择运算,Select子句作为投影运算,From子句作为连接运算。 连接运算是从两个关系的笛卡尔积中选择属性间满足一定条件的元组,在连接中最常用的是等值连接和自然连接。 等值连接:关系R、S,取两者笛卡尔积中属性值相等的元组,不要求属性相同。比如 R.A=S.B 自然连接(内连接):是一
-
基本概念 在数据库中,索引的含义与日常意义上的“索引”一词并无多大区别(想想小时候查字典),它是用于提高数据库表数据访问速度的数据库对象。 索引可以避免全表扫描。多数查询可以仅扫描少量索引页及数据页,而不是遍历所有数据页。 对于非聚集索引,有些查询甚至可以不访问数据页。 聚集索引可以避免数据插入操作集中于表的最后一个数据页。 一些情况下,索引还可用于避免排序操作。 索引的存储 一条索引记录中包含的