
sumk是一款轻量级的互联网框架。拥有开发速度快、性能好、易于横向扩展等特点。并且集成了一些互联网中常见功能,sumk入门文档点这里
主要功能特点简单介绍如下:
-
配置管理:sumk默认的配置是app.properties,同时内置了http、zookeeper两种统一配置中心。所有这些配置,都支持热变更,而不需要重启应用。并且提供了配置变更的通知机制。大多数配置都能兼容半角和全角符号。
-
微服务:服务注册、自动发现、故障转移、负载均衡等常见功能这里也都提供,并且使用更简单。服务器端只要在方法上添加@Soa注解,就能被其它实例调用,并且它还能在调用链上自动传递userId参数。客户端提供了同步、异步两种调用方式。
-
Web服务:主要针对移动端访问(PC端也可以使用),也可以用作微服务的网关。只要在方法上添加@Web注解就可以被html访问,比spring mvc更方便(spring mvc还需要在参数上添加注解)。本模块可以不使用tomcat,因为sumk内置了jetty服务器。还内置了通信加密,参数的签名验证等功能,可以在http模式下享受https的安全性
-
IOC:类似于spring的IOC功能,但拥有自己的特色。比如支持数组、集合方式的注入
-
ORM:类似于Hibernate的ORM,支持分表。它的特点是可以结合redis做准实时缓存,它跟hibernate二级缓存的显著区别就在于准实时。开发人员在操作数据库的时候,默认情况下,他并不关心数据来自缓存还是数据库。整个sumk框架,只有ORM功能有使用门槛。点这里看它的帮助文档。
-
事务:支持读写分离、权重、多数据源
-
数据库事件监听:通过ORM修改数据表的内容,在事务提交后,可以获取到它的通知。代码示例在这里
-
mybatis支持:sumk有自己的sql执行工具:RawUtil和NamedUtil。它们可以执行sql文件中的sql,但不支持if等标签。如果需要更灵活的操作,请使用mybatis。sumk提供了对mybatis的内置支持。
-
redis封装:封装了redis的连接获取与关闭、失败重试、多数据源路由等。
-
分布式session:只要在redis.properties里配置了session的地址,就实现了分布式session。否则就是单机运行。切换就是这么简单
-
异常体系:异常处理很考验开发者的基本功。许多应用的异常体系都是一团糟。sumk可以让开发者从异常中解脱出来,开发人员不需要去catch异常,也不需要做太多的校验,比如空指针之类。
-
线程管理:sumk将应用的线程管理起来,使得系统的线程不至于暴涨,让线程可以更有效的被利用,并提供工具方法,使得开发人员可以很方便的执行异步任务。此外还提供了限流功能,当线程紧张的时候,低优先级的任务会被直接拒绝。
-
分布式锁:因为许多应用是分布式部署的,需要用到分布式锁。sumk内置了一套分布式锁,只要有redis就可以运行,不需要开发任何额外的代码。它的原理是基于redis的lua脚本。
-
日志体系:在高并发应用中,接口调用量很高,很难定位日志是哪个请求打印的。sumk将会记录日志所属的用户或访问,便于日志跟踪。并且会提供统一日志扩展,不需要额外使用logstash等日志工具。具体参见这里
-
测试框架:数据库和微服务的单元测试一向是痛点。sumk提供了测试接口,在测试模式下,所有的数据库操作都会被回滚。它发起的微服务调用,如果被调用方允许被测试,它所做的数据库修改也会被还原。ORM的redis缓存也会被清理,但是手工修改的redis无法被清理。
-
其它功能:sumk还提供了web的第三方应用登陆、web的多端互踢、拦截器等功能。它的功能远不止上述那些。它是一个百宝箱,如果你掌握了,开发速度将会大大提升
-
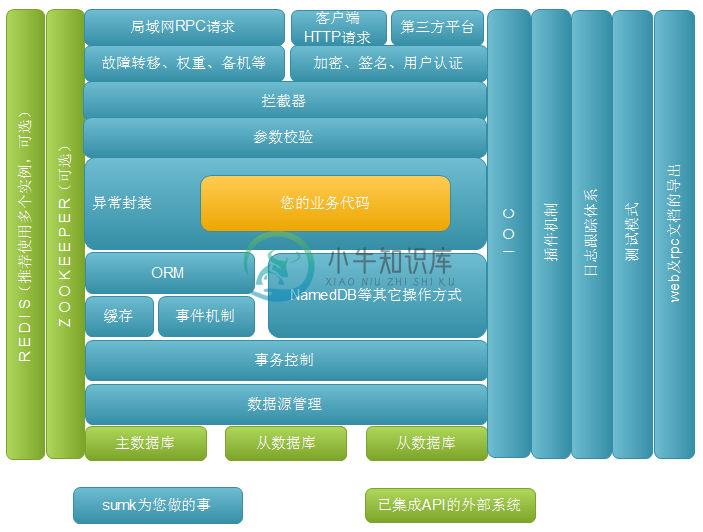
使用方式:通过maven引入sumk-log、sumk.jar及其依赖包(最新版惨叫maven中央库)。可以通过sumk-log引入,也可以直接引入sumk.jar,sumk-log是可选的。
<dependency>
<groupId>com.github.youtongluan</groupId>
<artifactId>sumk-log</artifactId>
<version>2.2.1</version>
</dependency>
sumk的四大模块为:数据库操作、微服务、web请求、IOC。除了sumk-db,其它使用很简单。
数据库操作方面,sumk提供了sumk-db、RawDB(RawDBUtil)、NamedDB(NamedDBUtil)和Mybatis4种方式,以下是代码示例:
@Box //@Box表示启用sumkDB的事务管理,类似于spring的@Transaction
public void test() {
//sumk-db类似于hibernate,以下是示例
DemoUser user = new DemoUser();
user.setAge(30);
user.setName("张三");
user.setLastUpdate(new Date());
DB.insert(user).execute(); //插入对象
//多条件查询,sumk不好入门的也就只有这个。这个功能是可选的,不用也没关系
List list=DB.select().tableClass(DemoUser.class)
.lessThan("lastupdate", new Date())
.orderByAsc("lastupdate")
.offset(10)
.limit(10)
.queryList();
//sumk-db例子结束
// RawDB使用的是原生的sql,后面跟的是要注入的参数。参数个数与sql中的?的个数一致
RawDB.list("select * from demouser where name=? and age=?", "登陆",12);
//NamedDB类似于mybatis,目前只支持#{}方式,不支持等标签。
NamedDB.count("select count(1) from demouser where name=#{name}", SBuilder.map("name", "登陆").toMap());
}
微服务(sumk-soa)代码示例:
/////////////////////////////////////服务器端:
@Soa
public List echo(String echo,List names){
............
return list;
}
//////////////////////// 客户端调用
List names=Arrays.asList("游夏","游侠");
String echo=",how are you";
String result=Rpc.call("groupId.appId.echo", echo,names); //返回是json格式的List对象
sumk-http代码示例:
@Web
public List echo(String echo,List names){
List list=new ArrayList();
for(String name:names){
list.add(echo+" "+name);
}
return list;
}
//客户端就是一般的http请求
//请求路径是http://localhost/intf/rest/echo
//请求实体是data={"echo":"hi","name":["张三","李四"]}
sumk项目的搭建非常简单,只要app.properties、sumk.jar及其它依赖包,您就自动拥有了架构图中的那些功能。启动方式是调用SumkServer.start()。需要jdk1.8。搭建示例参见文档
使用入门:
只需要引入sumk包,并添加配置文件app.properties,你就能运行sumk应用了。具体步骤参见sumk框架入门.docx。
接口压测:
运行org.test.Main,在这个类的相同目录下,有HttpPressTest和RpcPressTest两个文件,分别是http和微服务的压测用例。2个用例的压测结果大概都在2万次每秒(根据机器环境的不同而不同)。
联系方式:
QQ:3205207767
-
整理总结一下与sumK有关的问题。 1.两数之和 给定一个整数数组和一个目标值,找出数组中和为目标值的两个数。 你可以假设每个输入只对应一种答案,且同样的元素不能被重复利用。 示例: 给定 nums = [2, 7, 11, 15], target = 9 因为 nums[0] + nums[1] = 2 + 7 = 9 所以返回 [0, 1] 使用一个map用来存储数组元素值以及下标索引,遍历
-
sumk 的定位是提供一个类似于 spring boot 的轻量级互联网框架。它的生命线是开发速度和对互联网天然支持,比如分布式 session、数据库读写分离、微服务、数据缓存及刷新等。解决中小企业开发中常见的问题。 本次 sumk、sumk-log、sumk-tool 都进行了升级,并且把版本号升级到 2.0.0。本次更新对配置方式以及 web 接口样式变更比较大。 本次更新的主要内容: we
-
使用sumk框架,你不需要关心接口交互(包括rpc和http)、数据库访问、加解密、异常处理、redis连接等,并且大大减少sql编写数量,使开发者能够专注于业务代码编写,大大提升开发效率。有了sumk,架构师的门槛大大降低。 与spring生态相比,sumk的做法就是舍去低频应用,使得常用功能能够做得更好,使用更简单。相对spring来说,sumk无论是搭建、开发速度、项目启动速度等,都有了很大
-
sumk项目连接mysql,插入数据报错:创建datasource失败。 解决: 1.首先确认数据库连接正常 2.dao和xml要对应,比如:一个dao类名:AddDao.java 对应的xml为:AddDao.xml
-
主要内容:物联网解决方案架构的阶段物联网(IoT)架构没有这种独特或标准的共识,这种架构是普遍定义的。物联网架构与其功能区域及其解决方案不同。但是,物联网架构技术主要包括四个主要组成部分: 物联网架构的组成部分 传感器/设备 网关和网络 云/管理服务层 应用层 物联网解决方案架构的阶段 基于物联网元素的功能和性能构建了多层物联网,为企业和最终用户提供了最佳解决方案。物联网架构是设计物联网各种元素的基本方式,因此它可以通过网络提供服
-
一面 自我介绍 大学项目 图像分割与识别 没问 实习 CPU指令加速 稍微问了下加速的原理(SIMD) 毕业后项目 详细问了虚拟窗口通路原理 我干了什么 八股 C++八股文 问我怎么排查越界和内存泄露。加打印,注释部分函数。 排序算法的时间复杂度 为什么会有logn?答分治算法就有logn,归并和快排执行可以看作树,数据数量为n,深度为logn,所以是nlogn。 B+树知道吗?不知道就算了。。。
-
我对这家公司有着先入为主的厌恶滤镜,这源自自己作为消费者的直接评价、作为社会人的责任使然;此外,作为学生在与从基层到中层员工、从职能到业务人员的交流接触中,更加加深了这层滤镜。但需要说明的是,我十分幸运——最后遇到了很棒的老板和同事,让我出乎意料;奇葩的面试流程让我对面试有了更深刻的理解。 最后拿到offer对应的组真的挺棒的。做的事情算得上核心,也能发挥自己的特长,面试官/团队有技术,不过分卷;
-
主要内容:背景,业务架构设计,网络拓扑架构设计,秒杀业务流量洪峰,架构设计优化背景 大家好,这篇文章给大家介绍一个非常经典的去大厂面试经常被问的一个问题,就是瞬时 高并发抢购问题,通常来说,大厂开发的系统经常会遇到一些类似电商秒杀抢购、景点门票高并发抢购、特殊商品(比如口罩)高并发抢购、类似12306的高并发抢票类的系统。 所以经常会问这一类高并发抢购类的问题,这个时候,小伙伴们如果不能有理有据的给出一整套高并发场景下系统可能遇到的各种问题,以及你对应的架构设计和解决方案,
-
一面(技术面) 自我介绍 hadoop架构 namenode的功能,对namenode影响最大的计算机资源 介绍一下hive 宽依赖,窄依赖 写过复杂sql吗,介绍一下 sql分组过滤 java的hashmap c++和java的区别 介绍一下hbase 数据库三范式 二面(hr面) 自我介绍 为什么选择中移互联网 了解中移互联网吗(这里尬住了,压根不了解) #中移互联网##数据研发#
-
移动互联快速开发平台 采用Mongodb为底层数据库:数据设计随需而变; 采用Mongodb集群,支撑大数据量,大并发实时查询,便于扩展; 采用SpringMongodb简化开发,简单得令人发指; 采用SpringRest提供JSON的输出,支持各种转换; 提供程序整合、兼容中文、跨域JSONP的支持; 进行了大数据量的压力测试,参数的最优配置; 各种最佳实践。 HTML5 快速开发的前端架构,专
-
CL,SL,CL,SL,CM,Softmax 架构2(我们真的又需要NN在末尾了吗?)http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5605630&tag=1 CL,SL,CL,SL,NN,Softmax 建筑3我的想法 CL,SL,CL,SL,Softmax
-
自我介绍 RPC,如何理解,有哪些成熟的框架 实习参与的内容 区块链分叉 死锁如何解决 使用多线程需要注意什么 如何保证线程安全 如何提高区块链写入效率 链上链下相结合的存储如何保证安全性 在校成绩 职业规划