
Apache NiFi 是一个易于使用、功能强大而且可靠的数据处理和分发系统。Apache NiFi 是为数据流设计。它支持高度可配置的指示图的数据路由、转换和系统中介逻辑。
架构:
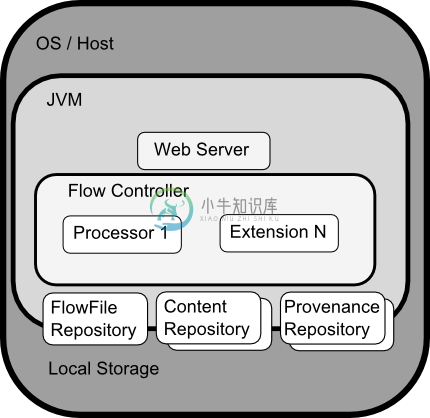
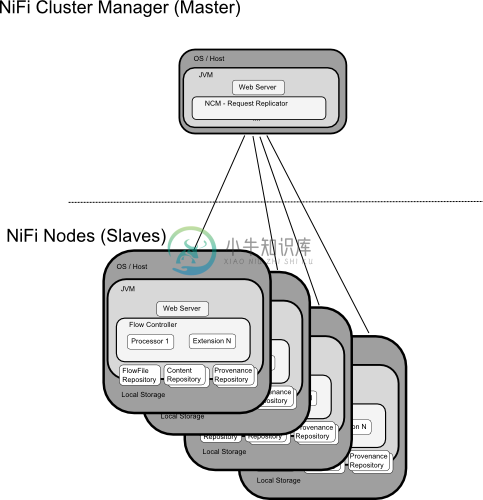
集群管理器:
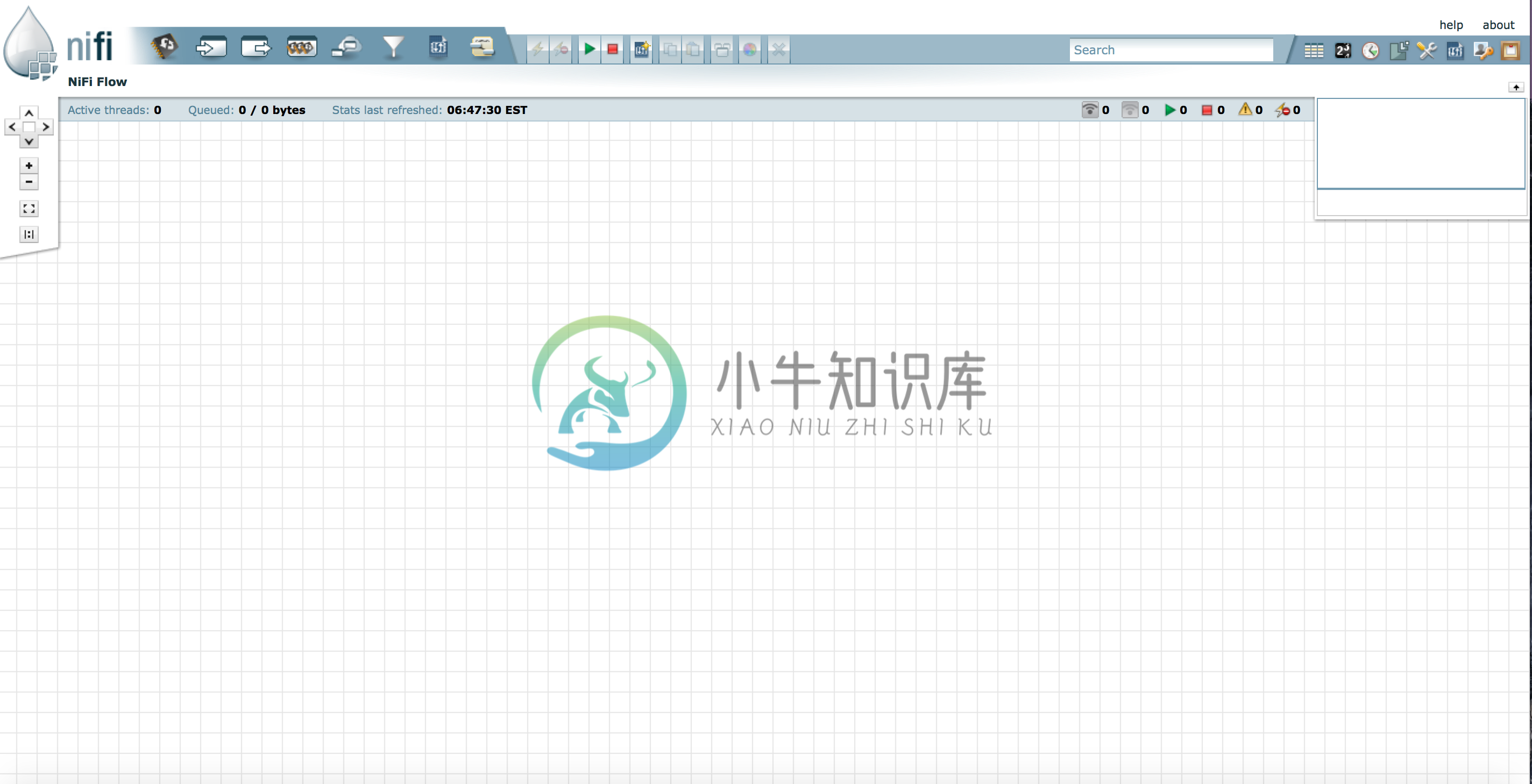
主界面:
关键特性包括:
-
基于web的用户界面
-
无缝体验设计、控制和监视
-
-
高度可配置的
-
数据丢失容错和保证交付
-
低延迟和高吞吐量
-
动态优先级
-
流可以在运行时修改
-
背压 Back presure
-
-
数据来源
-
从始至终跟踪数据流
-
-
为扩展设计
-
构建自己数据处理器
-
支持快速开发和有效的测试
-
-
安全
-
SSL,SSH,HTTPS加密内容,等等……
-
可插拔的基于角色的验证/授权
-
-
整体文件竟然1.5G左右。现在已经下载下来了。基本上视频教程大概两个小时左右。国内的使用比较少。 dataflow 数据流 不同系统之间的数据流通 Nifi 是用来处理数据集成场景的数据分发,BS结构的图形化。 1、高可用 2、高性能高并发 3、错误纠察 4、对于现实业务的变更可以快速响应 5、对于不同系统之间的数据格式可以进行兼容,兼容各种数据格式 6、安全性比较高 7、可以方便的
-
nifi apache Just a couple of years ago, software projects didn’t exceed a bunch of files! You could store a project on a Floppy disk and install it here and there. Nowadays, hardware and software comp
-
事务的概念 事务的概念来自于两个独立的需求:并发数据库访问,系统错误恢复。 一个事务是可以被看作一个单元的一系列SQL语句的集合。 事务的特性(ACID) A, atomacity 原子性 事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。通常,与某个事务关联的操作具有共同的目标,并且是相互依赖的。如果系统只执行这些操作的一个子集,则可能会破坏事务的总体目标。原子性消除了系统处
-
我正在实现spring批处理作业,用于使用分区方法处理一个DB表中的数百万条记录,如下所示- > 从分区器中的表中提取唯一的分区代码,并在执行上下文中设置相同的代码。 创建一个包含读取器、处理器和写入器的块步骤,以基于特定分区代码处理记录。 是否可以创建分区/线程来处理像thread1进程1-1000,thread2进程1001-2000等? 如何控制创建的线程数,因为分区代码可以是100个左右,
-
数据处理 可将字段的值进行处理得到最终结果 html标签过滤 内容替换 批量替换 关键词过滤 条件判断 截取字符串 翻译 工具箱 将文本链接标记为图片链接:如果字段的值是完整的url链接(非<img>标签内的链接),可将链接识别为图片 使用函数 调用接口
-
数据概览 1.数据概览 首页>报表>数据 查看时间范围内系统的关键数据指标。包括总会话量、总消息量、平均会话时长、平均响应时长、排队放弃会话量、平均满意度以及会话量、消息量、平均会话时长之间的变化趋势条形图、柱状图和饼状图。 2.客服报表 首页>报表>客服 客服工作量分析:查看人工客服的工作数据。包括接待总数、对话总数、对话总时长、在线总时长以及在线人工利用率。 客服工作效率/质量分析:查看人工客
-
我需要访问两个数据源: Spring批处理存储库:在内存H2中 我的步骤需要访问。 我在那里看到了几个关于如何创建自定义
-
译者:yportne13 作者:Sasank Chilamkurthy 在解决机器学习问题的时候,人们花了大量精力准备数据。pytorch提供了许多工具来让载入数据更简单并尽量让你的代码的可读性更高。在这篇教程中,我们将学习如何加载和预处理/增强一个有价值的数据集。 在运行这个教程前请先确保你已安装以下的包: scikit-image: 图形接口以及变换 pandas: 便于处理csv文件 fro
-
我遇到了一些数据,我想用许多不同的方式对它进行排序,例如按购买最多的最便宜的产品进行排序。我想一行一行地对文档进行分组,因为每行包含另一个“项目”。我附上了一张图片供参考。我更喜欢使用Java,但如果有必要,我会学习R。我是否手动将每行编码为数组?有400个项目,如果这是唯一的方法,我可以将其分成几天。 样品