
铸龙是一款用于分析用户行为事件的 BI 软件。
特点如下
- 事件分析
- 埋点上报
- 漏斗分析
- 留存分析
- 智能路径分析
- 报表,面板管理
- 多平台部署,直接二进制部署无需搭建环境
技术栈主要用
- mysql
- redis
- kafka
- clickhouse
- 该系统分为以下四部分
- 埋点上报sdk
- report_server
- sinker
- manager
- 埋点上报sdk: 用于采集埋点信息,目前SDK支持类型
- web
- cocos creator
- egert
- report_server:用于收集sdk上报的信息,并生产消息入kafka
- sinker:消费kafka的埋点消息并入库
- manager:基于入库后的埋点数据进行分析,报表。
部署文件下载地址为 https://gitee.com/cynthia520/xwl_bi/releases/v1.0.0
- 下载sdk.zip,解压缩 如下图所

下面我们拿web为例子 步骤如下
1. 打开web文件夹后有如下js文件
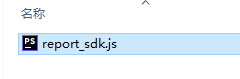
<script type="text/javascript" src="report_sdk.js" ></script>
<script type="text/javascript" >
let parmas = {"appid":"********","appkey":"********"}
let eventReport = new EventReport("http://127.0.0.1:8091", parmas["appid"], parmas["appkey"], 0)
eventReport.track("访问铸龙BI文档",{feeling:"Hello World!"})
</script>- 下载对应操作系统的压缩包,如windows系统则下载win.zip,解压缩后有如下文件
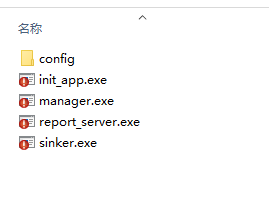
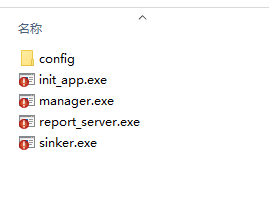
-
- 修改 config文件夹下的config.json
具体配置项解释如下
{ "manager": { //bi管理系统配置模块 "port": 8090, //启动端口 "jwtSecret": "1340691923@qq.com", //jwt密钥 "deBug": true //是否为调试模式 ,非调试模式会调用浏览器打开bi访问地址 }, "report": { //上报服务模块 "reportPort":8091, //启动端口 "readTimeout":20, //读超时时间,单位(秒)(不填则不受限制) "writeTimeout":20, //写超时时间,单位(秒)(不填则不受限制) "maxConnsPerIP":100000, //每个IP允许的最大并发客户端连接数(不填则不受限制) "maxRequestsPerConn":100000, //每个连接服务的最大请求数(不填则不受限制) "idleTimeout":20, //等待消息的最长时间,如果为零,则使用readTimeout的值。 "userAgentBanList":["mpcrawler"] //不允许访问的userAgent请求头 , 例如 demo中的 mpcrawler 是微信小程序机器人的 userAgent }, "sinker": { //sinker模块 "reportAcceptStatus":{ //上报数据状态入库(入库 CK) "bufferSize": 999, //入库批次数量 "flushInterval": 2 //入库轮循间隔时间(秒) }, "reportData2CK":{ //上报数据入库(入库 CK) "bufferSize": 1000, //入库批次数量 "flushInterval": 2 //入库轮循间隔时间(秒) }, "realTimeWarehousing":{ //实时数据入库(入库 ES) "bufferSize": 1000, //入库批次数量 "flushInterval": 2 //入库轮循间隔时间(秒) }, "pprofHttpPort": 8093 //pprof性能检测端口 }, "comm": { //公用模块 "log": { //日志模块 "storageDays":4, //存放天数 "logDir":"logs" //存放目标文件夹 }, "mysql": { //mysql模块 "username":"root", //用户名 "pwd":"123456", //密码 "ip":"127.0.0.1", //ip "port":"3306", //端口 "dbName":"lyn_bi", //数据库名 "maxOpenConns":10, //连接池最大打开数 "maxIdleConns":10 //连接池初始化闲置数 }, "clickhouse": { //clickhouse模块 "username":"default", //用户名 没有则不填 "pwd":"EtHnvllx", //密码 没有则不填 "ip":"127.0.0.1", //IP "port":"9000", //端口 "dbName":"default", //数据库名 "clusterName":"perftest_3shards_1replicas", //集群名 单机CK则不填 "macrosShardKeyName":"share", //metrika.xml 的share key名 单机CK则不填 //例如: <macros> //<share>1</share> // <replica>192.168.1.236</replica> //</macros> //则 macrosShardKeyName 填share "macrosReplicaKeyName":"replica", //metrika.xml 的replica key名 单机CK则不填 "maxOpenConns":100, //连接池最大打开数 "maxIdleConns":1000 //连接池初始化闲置数 }, "kafka": { //kakfa 模块 "addresses":["127.0.0.1:9092"], //访问地址 "username":"", //用户名 "password":"", //密码 "numPartitions":300, //初始化 埋点数据topic分区数 "debugDataTopicName": "debugDataTopicName", //测试模式下 测试埋点数据的topic名 "debugDataGroup": "debugDataGroup", //测试模式下 测试埋点数据的消费者组名 "reportTopicName": "test005", //埋点数据的topic名 "reportData2CKGroup": "reportData2CKGroup2", //埋点数据的消费者组名(入库 CK) "realTimeDataGroup": "realTimeDataGroup2", //实时数据的消费者组名(入库 ES) "producer_type":"async", //kafka生产者类型 async 为异步模式 sync 为同步模式 ,不填为async }, "redis": { //redis模块 "addr":"127.0.0.1:6379", //访问地址 "passwd":"", //密码 "db": 7, //库名 "maxIdle": 300, //连接池初始化闲置数 "maxActive": 0 //连接池所能分配的最大的连接数目 ,当设置成0的时候,该连接池连接数没有限制 } } } -
启动 windows环境 则双击 应用名.exe linux环境则 chmod +x 应用名 && ./应用名
- init_app
显示 “数据已全部初始化完毕!”则为正常启动
- manager
启动后显示下图则为正常启动
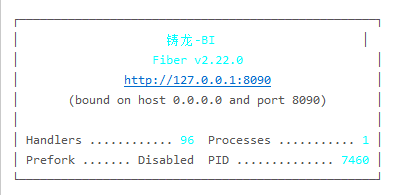 report_server
report_server启动后显示下图则为正常启动
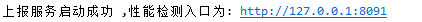
- sinker
启动后显示下图则为正常启动
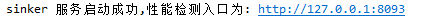
至此,服务端已配置完毕
-
用户趋势 活跃用户 用户画像 地域分布 终端分析 版本分析 实时访客
-
用户分析 一、功能简介 增长黑客必须以用户为王!了解产品的用户是谁?从哪来?有什么特征?这些是做产品运营和功能设计最基础的要求,也是统计与分析工具需要帮助您解决的最基础的一个问题,即:从数据层面分析您的用户。 在移动统计平台上,我们通过用户趋势与活跃分析、地域分布、终端分析、版本分析和用户画像五个功能,帮助您剖析: 用户规模、质量构成、用户来源、终端属性以及超出APP范畴的用户在大数据世界的画像(
-
9.16 一面 20min左右 1.自我介绍 2.挖实习,针对部分细节做提问 3.数据分析需要哪些技能 4.反问 9.19 二面 25min 1.自我介绍 2.深挖简历,面试官比较关注项目的产出 3.广告投放的渠道分析(实习中有) 4.是否了解地产数字化 5.反问 问了下后续面试流程,说是至少还有一轮业务面+hr面,如果sp的话还会有总监面 许愿终试 龙湖数科数据分析求抱团 #龙湖集团数字科技##
-
行为分析模块提供了丰富的高阶分析工具,您可以通过这些分析工具,深度分析业务指标、洞察用户行为模式特征、刻画用户画像、科学评估渠道推广效果,甚至基于用户分群与百度投放直达能力,实现分人群的精准营销与策略落地。 此外,您也可以通过保存到数据看板来逐步沉淀有价值的行为分析思路与结果。 目前行为分析模块包含6大分析能力。 事件分析 漏斗分析 留存分析 行为流 分布分析 关联分析
-
生成图表 如何分析用户的数据是一个有趣的问题,特别是当我们有大量的数据的时候。除了 matlab,我们还可以用 numpy + matplotlib 数据可以在这边寻找到 https://github.com/gmszone/ml 最后效果图 2014 01 01 要解析的 JSON 文件位于data/2014-01-01-0.json,大小 6.6M,显然我们可能需要用每次只读一行的策略,这足以
-
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData