
MindSpore 是一个全场景 AI 计算框架,它的特性是可以显著减少训练时间和成本(开发态)、以较少的资源和最高能效比运行(运行态),同时适应包括端、边缘与云的全场景(部署态)。
针对不同的运行环境,MindSpore 框架架构上支持可大可小,适应全场景独立部署。MindSpore 框架通过协同经过处理后的、不带有隐私信息的梯度、模型信息,而不是数据本身,以此实现在保证用户隐私数据保护的前提下跨场景协同。除了隐私保护,MindSpore 还将模型保护内建于框架中,实现模型的安全可信。
MindSpore 通过实现 AI 算法即代码,使开发态变得更加友好,可以显著减少模型开发时间。以一个 NLP(自然语言处理)典型网络为例,相比其它框架,用 MindSpore 可降低核心代码量 20%,开发门槛大大降低,效率整体提升 50% 以上。
通过 MindSpore 框架自身的技术创新及其与昇腾处理器协同优化,有效克服 AI 计算的复杂性和算力的多样性挑战,实现了运行态的高效,大大提高了计算性能。除了昇腾处理器,MindSpore 同时也支持 GPU 与 CPU 等其它处理器。
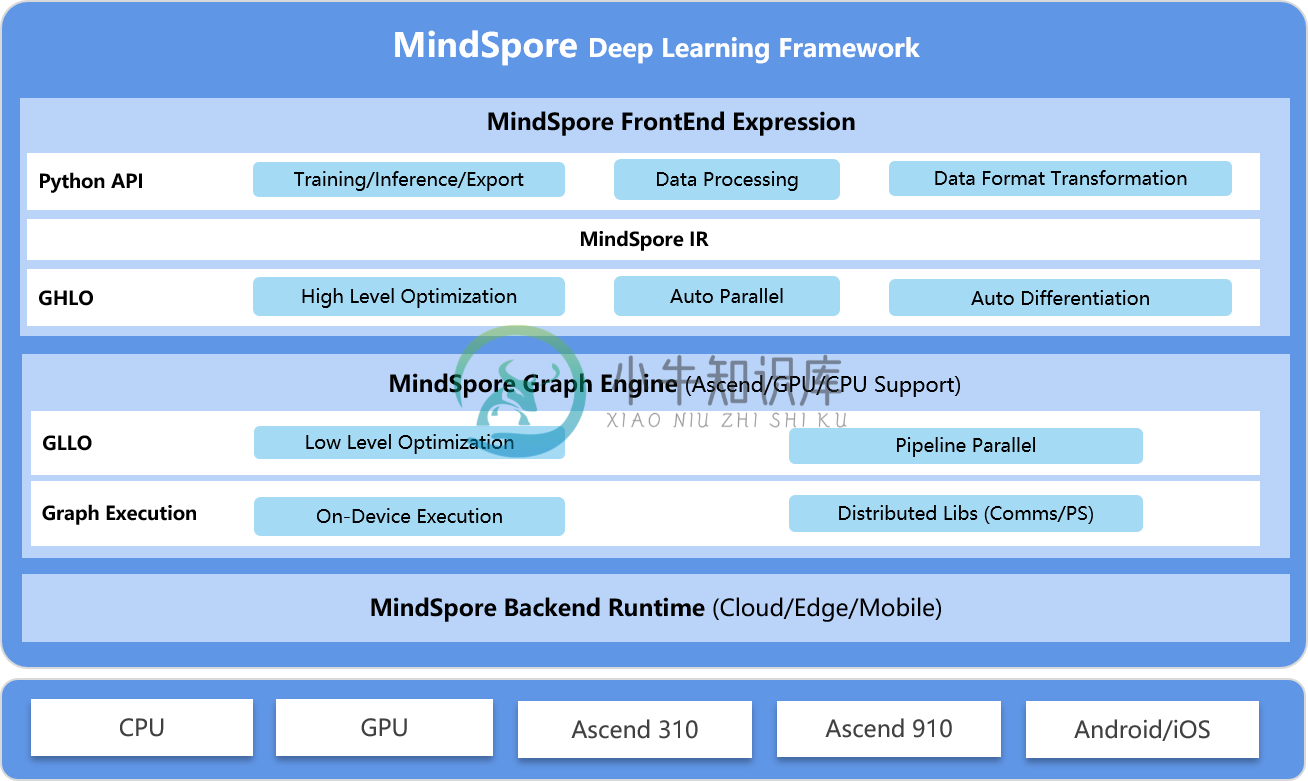
-
一、简介 首先MindSpore Data提供了简洁、丰富的数据读取、处理、增强等功能;同时使用读取数据的流程,主要分为三步(使用和PyTorch中数据读取方式类似): 数据集加载 - 根据数据格式,选择最简单、高效的数据集加载方式; 数据增强 - 使用几何变换、颜色变换、旋转、平移、缩放等基本图像处理技术来扩充数据集; 数据处理 - 对数据集做repeat、batch、shuffle、map、z
-
11.2 一面 因为10月底才考,所以面的比较晚,怕忘了记录一下。 1. 介绍项目(非常详细)。 2. 用过哪些神经网络,有什么区别和特点(说ResNet的时候,从公式角度解释了一下问什么缓解梯度消失)。 3. 老生常谈,问了梯度消失和梯度爆炸。 4. 平常看论文吗,看论文能力如何。 5. 还有的简单的小知识记不清了。 6. 手撕(medium,电话号码的字母排列),大概12/3分钟左右写出来。
-
去年12月转去学算法,算法底蕴有点浅,只有一个还没做完的项目。获奖:ACM CCPC银以及很多华为比赛的奖,都和算法无关 免笔试(不知道会不会影响最终成绩,早知道不偷懒了) 5.22一面 讲了项目,然后问我反向传播的原理。最后手撕算法,他问我平时刷不刷leetcode,我:???因为我是acm选手,所以不刷。然后他让我选一题写,我说直接上hard吧,他好像不信我,也不了解各种比赛,就选了一道中等题
-
算法:给一个数组,一个target,打印出所有的数组元素组合使其和恰好为target,不允许有重复 聊实习 内存与CPU问题如何排查处理 HashSet线程安全吗,原理
-
我在这里阅读了几个与我的问题相关的问题/解决方案。但似乎什么都不管用。 所以我有一个全屏模式的primarystage,比如说,如果我点击一个按钮,它会改变场景。但舞台似乎显示了任务栏。我还通过将此添加到所有场景方法中解决了此问题。。 但是,场景中的过渡不是那么流畅。首先,它进入桌面,然后回到全屏...这不是理想的解决方案。 以下是我的初级阶段代码: 这是我改变场景的代码: 我不知道这是虫子还是什
-
9.7 笔试 9.16 测评 9.19 一面 两个比赛情况简介 项目1介绍 评估指标 除了特征级优化还有哪些优化 数据归一化方式有哪些 Transformer了解哪些,是否看过源码 PyTorch是否看过源码 PyTorch如何处理数据 梯度消失有哪些处理方式 梯度爆炸有哪些处理方式 梯度反向传播有数学推导过吗 图片数据预处理做了哪些工作 自然语言处理也用卷积吗 Python实现接口类 不同数据结
-
有没有朋友这个岗开奖的?是不是压根没hc#华为##华为数字能源##华为开奖#
-
背景:211本硕,一作SCI一区论文两篇,无实习。 一面(9.21) 1. 复盘笔试内容; 2. 自我介绍; 3. 问两篇论文的细节,顺便展开问了一些基础知识(25分钟左右); 4. 撕代码(LC498,对角线遍历,15分钟左右)。 总结:面试官和我研究方向类似,对我的工作很感兴趣,全程聊的很愉快,面试体验极佳。 结果:面试结束后1分钟收到面试通过的短信。 二面(9.21) 1. 自我介绍; 2.
-
2023.09.06 一面 40mins 主要问实习经历,扣细节。 手撕:数组去重后排序。 2023.09.07 二面 40-45mins 问项目,问论文,问实习。 手撕:LC53 最大子数组和。手撕说给30mins做题,但是我暴力法做的1mins就做完了,面试官说怎么这么快哈哈哈!(其实要用dp,但是面试官说都可以,做出来就行) 2023.09.16 主管面 35mins 问了项目,后续就问一些