[实例]Python lxml应用
本节通过编写一个简单的爬虫程序,进一步熟悉 lxml 解析库的使用。
下面使用 lxml 库抓取猫眼电影 Top100 榜( 点击访问),编写程序的过程中,注意与《 Python爬虫抓取猫眼电影排行榜》中使用的正则解析方式对比,这样您会发现 lxml 解析库是如此的方便。
通过
下面使用 lxml 库抓取猫眼电影 Top100 榜( 点击访问),编写程序的过程中,注意与《 Python爬虫抓取猫眼电影排行榜》中使用的正则解析方式对比,这样您会发现 lxml 解析库是如此的方便。
确定信息元素结构
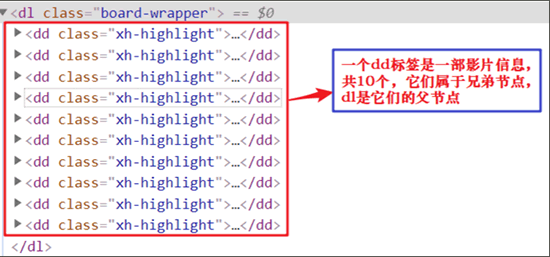
首先明确要抓取信息的网页元素结构,比如电影名称、主演演员、上映时间。通过简单分析可以得知,每一部影片的信息都包含在<dd>标签中,而每一
<dd>标签又包含在
<dl>标签中,因此对于
dd标签而言,
dl标签是一个更大的节点,也就是它的父辈节点,如下所示:
图1:分析元素结构
当一个
<dd>标签内的影片信息提取完成时,您需要使用同样的 Xpath 表达式提取下一影片信息,直到所有影片信息提取完成,这种方法显然很繁琐。那么有没有更好的方法呢?
基准表达式
因为每一个节点对象都使用相同 Xpath 表达式去匹配信息,所以很容易想到 for 循环。我们将 10 个<dd>节点放入一个列表中,然后使用 for 循环的方式去遍历每一个节点对象,这样就大大提高了编码的效率。
通过
<dd>节点的父节点
<dl>可以同时匹配 10 个
<dd>节点,并将这些节点对象放入列表中。我们把匹配 10个
<dd>节点的 Xpath 表达式称为“基准表达式”。如下所示:
xpath_bds='//dl[@class="board-wrapper"]/dd'下面通过基准表达式匹配 <dd> 节点对象,代码如下:
# 匹配10个dd节点对象 xpath_bds='//dl[@class="board-wrapper"]/dd' dd_list=parse_html.xpath(xpath_bds)输出结果:
[<Element dd at 0x36c7f80>, <Element dd at 0x36c7d50>, <Element dd at 0x36c7940>, <Element dd at 0x36c7d28>, <Element dd at 0x36c7bc0>, <Element dd at 0x36c7f58>, <Element dd at 0x36c7f30>, <Element dd at 0x36cc468>, <Element dd at 0x36cc170>, <Element dd at 0x37382b0>]
提取数据表达式
因为我们想要抓取的信息都包含在<dd>节点中,接下来开始分析<dd>节点包含的 HTML 代码,下面随意选取的一段<dd>节点包含的影片信息,如下所示:
<dd>
<i class="board-index board-index-4">4</i>
<a href="/films/1292" title="海上钢琴师" class="image-link" data-act="boarditem-click" data-val="{movieId:1292}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default">
<img alt="海上钢琴师" class="board-img" src="https://p0.meituan.net/movie/609e45bd40346eb8b927381be8fb27a61760914.jpg@160w_220h_1e_1c">
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/1292" title="海上钢琴师" data-act="boarditem-click" data-val="{movieId:1292}">海上钢琴师</a></p>
<p class="star">
主演:蒂姆·罗斯,比尔·努恩,克兰伦斯·威廉姆斯三世
</p>
<p class="releasetime">上映时间:2019-11-15</p> </div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.</i><i class="fraction">3</i></p>
</div>
</div>
</div>
</dd> 分析上述代码段,写出待抓取信息的 Xpath 表达式,如下所示:
提取电影名信息:xpath('.//p[@class="name"]/a/text()')
提取主演信息:xpath('.//p[@class="star"]/text()')
提取上映时间信息:xpath('.//p[@class="releasetime"]/text()')
完整程序代码
上述内容介绍了编写程序时用到的 Xpath 表达式,下面正式编写爬虫程序,代码如下所示:
# coding:utf8
import requests
from lxml import etree
from ua_info import ua_list
import random
class MaoyanSpider(object):
def __init__(self):
self.url='https://maoyan.com/board/4?offset=50'
self.headers={'User-Agent':random.choice(ua_list)}
def save_html(self):
html=requests.get(url=self.url,headers=self.headers).text
#jiexi
parse_html=etree.HTML(html)
# 基准 xpath 表达式,匹配10个<dd>节点对象
dd_list=parse_html.xpath('//dl[@class="board-wrapper"]/dd') #列表放10个dd
print(dd_list)
# .// 表示dd节点的所有子节点后代节点
# 构建item空字典将提取的数据放入其中
item={}
for dd in dd_list:
# 处理字典数据,注意xpath表达式匹配结果是一个列表,因此需要索引[0]提取数据
item['name']=dd.xpath('.//p[@class="name"]/a/text()')[0].strip()
item['star']=dd.xpath('.//p[@class="star"]/text()')[0].strip()
item['time']=dd.xpath('.//p[@class="releasetime"]/text()')[0].strip()
#输出数据
print(item)
def run(self):
self.save_html()
if __name__ == '__main__':
spider=MaoyanSpider()
spider.run() 输出结果如下:
{'name': '飞屋环游记', 'star': '主演:爱德华·阿斯纳,乔丹·长井,鲍勃·彼德森', 'time': '上映时间:2009-08-04'}
{'name': '窃听风暴', 'star': '主演:乌尔里希·穆埃,塞巴斯蒂安·科赫,马蒂娜·格德克', 'time': '上映时间:2006-03-23(德国)'}
{'name': '美国往事', 'star': '主演:罗伯特·德尼罗,詹姆斯·伍兹,伊丽莎白·麦戈文', 'time': '上映时间:2015-04-23'}
{'name': '乱世佳人', 'star': '主演:费雯·丽,克拉克·盖博,奥利维娅·德哈维兰', 'time': '上映时间:1939-12-15(美国)'}
{'name': '大话西游之大圣娶亲', 'star': '主演:周星驰,朱茵,莫文蔚', 'time': '上映时间:2014-10-24'}
{'name': '美丽心灵', 'star': '主演:罗素·克劳,詹妮弗·康纳利,艾德·哈里斯', 'time': '上映时间:2001-12-13(美国)'}
{'name': '消失的爱人', 'star': '主演:本·阿弗莱克,裴淳华,尼尔·帕特里克·哈里斯', 'time': '上映时间:2014-09-26(美国)'}
{'name': '罗马假日', 'star': '主演:格利高里·派克,奥黛丽·赫本,埃迪·艾伯特', 'time': '上映时间:1953-08-20(意大利)'}
{'name': '一一', 'star': '主演:吴念真,金燕玲,李凯莉', 'time': '上映时间:2017-07-28(中国台湾)'}
{'name': '蝴蝶效应', 'star': '主演:约翰·帕特里克·阿梅多利,罗根·勒曼,卡梅隆·布莱特', 'time': '上映时间:2004-01-23(美国)'}