XML DOM遍历
在本章中,我们将讨论XML DOM遍历。 在前一章中学习了如何加载XML文档并解析由此获得的DOM对象。 可以遍历解析后的DOM对象以获取每个对象的内容。 遍历是一种通过在节点树中逐步遍历每个元素以系统方式完成循环的过程。
示例
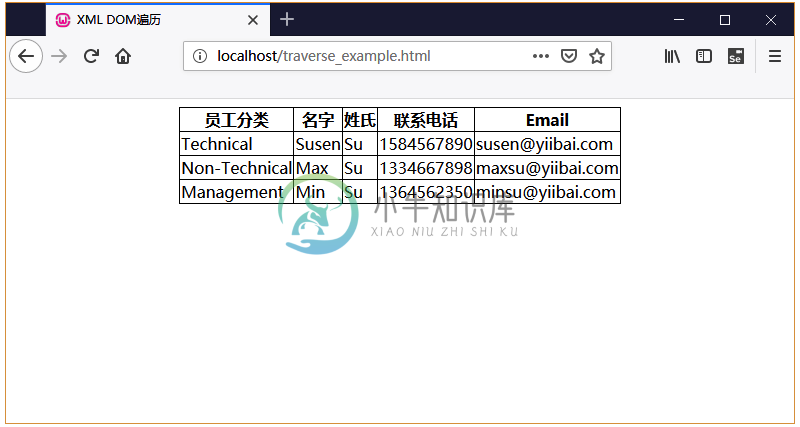
以下示例(traverse_example.html)演示了DOM遍历具体用法。 在这里,将遍历<Employee>元素的每个子节点。
文件:traverse_example.html -
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>XML DOM遍历</title>
</head>
<style>
table,th,td {
border:1px solid black;
border-collapse:collapse
}
</style>
<body>
<div id = "ajax_xml"></div>
<script>
//if browser supports XMLHttpRequest
if (window.XMLHttpRequest) {// Create an instance of XMLHttpRequest object.
//code for IE7+, Firefox, Chrome, Opera, Safari
var xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
var xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
// sets and sends the request for calling "node.xml"
xmlhttp.open("GET","/node.xml",false);
xmlhttp.send();
// sets and returns the content as XML DOM
var xml_dom = xmlhttp.responseXML;
// this variable stores the code of the html table
var html_tab = '<table id = "id_tabel" align = "center"><tr><th>员工分类</th><th>名字</th><th>姓氏</th><th>联系电话</th><th>Email</th></tr>';
var arr_employees = xml_dom.getElementsByTagName("Employee");
// traverses the "arr_employees" array
for(var i = 0; i<arr_employees.length; i++) {
var employee_cat = arr_employees[i].getAttribute('category');
// gets the value of 'category' element of current "Element" tag
// gets the value of first child-node of 'FirstName'
// element of current "Employee" tag
var employee_firstName =
arr_employees[i].getElementsByTagName('FirstName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'LastName'
// element of current "Employee" tag
var employee_lastName =
arr_employees[i].getElementsByTagName('LastName')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'ContactNo'
// element of current "Employee" tag
var employee_contactno =
arr_employees[i].getElementsByTagName('ContactNo')[0].childNodes[0].nodeValue;
// gets the value of first child-node of 'Email'
// element of current "Employee" tag
var employee_email =
arr_employees[i].getElementsByTagName('Email')[0].childNodes[0].nodeValue;
// adds the values in the html table
html_tab += '<tr><td>'+ employee_cat+ '</td><td>'+ employee_firstName+ '</td><td>'+ employee_lastName+ '</td><td>'+ employee_contactno+ '</td><td>'+ employee_email+ '</td></tr>';
}
html_tab += '</table>';
// adds the html table in a html tag, with id = "ajax_xml"
document.getElementById('ajax_xml').innerHTML = html_tab;
</script>
</body>
</html>
文件:node.xml -
<Company>
<Employee category = "Technical" id = "firstelement">
<FirstName>Susen</FirstName>
<LastName>Su</LastName>
<ContactNo>1584567890</ContactNo>
<Email>susen@yiibai.com</Email>
</Employee>
<Employee category = "Non-Technical">
<FirstName>Max</FirstName>
<LastName>Su</LastName>
<ContactNo>1334667898</ContactNo>
<Email>maxsu@yiibai.com</Email>
</Employee>
<Employee category = "Management">
<FirstName>Min</FirstName>
<LastName>Su</LastName>
<ContactNo>1364562350</ContactNo>
<Email>minsu@yiibai.com</Email>
</Employee>
</Company>
有关上面文件:traverse_example.html 中代码的说明 -
- 此代码加载node.xml。
- XML内容转换为JavaScript XML DOM对象。
- 获得方法
getElementsByTagName()使用元素数组(带有标记Element)。 - 接下来,遍历此数组并在表中显示子节点值。
执行结果
将上面两个文件保存到服务器WEB应用目录中(node.xml应位于服务器的同一路径上)。在浏览器将看到以下输出 -