
详解Linux索引节点inode

1.inode简介
理解inode,要从文件储存说起。文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512html" target="_blank">字节(相当于0.5KB)。操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点” 。
2.inode包含内容
Linux中目录的数据块中的每一项中都包含了文件名和其对应的inode。inode记录了文件的属性以及该文件实际存储位置,即数据块号(block number),每一个block(常见大小4KB),通过inode可以实现文件的查找定位。inode是Linux中的,Unix中是vnode。基本上,inode包含的信息至少有如下这些:
(1)文件的类型
(2)文件访问权限;
(3)文件的所有者与组;
(4)文件的大小;
(5)链接数,即指向该inode的文件名总数;
(6)文件的状态改变时间(ctime)、最近访问时间(atime)和最近修改时间(mtime);
(7)文件特殊属性,SUID、SGID和SBIT;
(8)文件内容的真正指向(pointer)。
可以用stat命令,查看某个文件的inode信息。
3.inode特点
inode的数量与大小在磁盘格式化的时候就已经固定了,inode的特点有:
(1)每一个inode的大小均固定为128B。可以通过命令dumpe2fs来显示ext2/ext3/ext4文件系统信息。
$ dumpe2fs -h /dev/sda1 | grep "Inode size" dumpe2fs 1.41.12 (17-May-2010) Inode size: 128
(2)每个文件都只占用一个inode。因此,文件系统能够建立的文件数量与inode数量有关。系统读取档案时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
4.操作系统读取磁盘文件的流程
操作系统读取磁盘文件的流程是这样的:
(1)根据给定的文件的所在目录,获取该目录的数据实体,根据数据实体中的数据项,找到对应文件的inode;
(2)根据文件inode,找到inodeTable;
(3)根据inodeTable中的对应关系,找到对应的block;
(4)读取文件。
系统读取磁盘文件流程示意图如下:
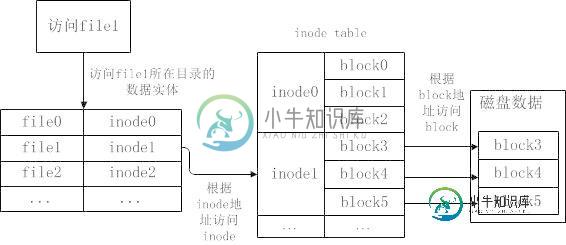
举例来说,如果想要读取/etc/passwd文件,读取流程如下:
(1)获取根目录/的inode。透过挂载点的信息找到根目录的inode号为2;
ll -di / 2 dr-xr-xr-x 19 root root 4096 Feb 14 09:32 /
(2)根据根目录的inode,找到根目录的数据实体block,可以理解为一个文件到inode号的映射表,找到目录etc的inode号;
ll -di /etc 786433 drwxr-xr-x 98 root root 12288 Feb 13 17:18 /etc
(3)根据目录etc的inode号,读取目录etc的数据实体block,并找到文件passwd的inode号;
ll -i /etc/passwd 787795 -rw-r--r-- 1 root root 1552 Jan 4 14:56 /etc/passwd
(4)根据/etc/passwd文件的inode号,即可获取/etc/passwd文件的数据实体block,完成文件的读取。
5.inode的诸多优点
(1)对于有些无法删除的文件可以通过删除inode节点来删除;
(2)移动或者重命名文件,只是改变了目录下的文件名到inode的映射,并不需要实际对硬盘操作;
(3)删除文件的时候,只需要删除inode,不需要实际清空那块硬盘,只需要在下次写入的时候覆盖即可(这也是为什么删除了数据可以进行数据恢复的原因之一);
(4)打开一个文件后,只需要通过inode来识别文件。
以上就是详解Linux索引节点inode的详细内容,更多关于Linux索引节点inode的资料请关注小牛知识库其它相关文章!
-
在基于UNIX的操作系统中,每个文件都由一个Inode索引。 Inode是创建文件系统时创建的特殊磁盘块。 文件系统中的文件或目录数量取决于文件系统中的Inode数量。 Inode包含以下信息 - 文件的属性(权限,时间戳,所有权详细信息等) 包含指向文件的前12个块的指针的多个直接块。 指向索引块的单个间接指针。 如果文件不能被直接块完全索引,则使用单个间接指针。 指向磁盘块的双重间接指针,该磁
-
索引节点 在SFS文件系统中,需要记录文件内容的存储位置以及文件名与文件内容的对应关系。sfs_disk_inode记录了文件或目录的内容存储的索引信息,该数据结构在硬盘里储存,需要时读入内存。sfs_disk_entry表示一个目录中的一个文件或目录,包含该项所对应inode的位置和文件名,同样也在硬盘里储存,需要时读入内存。 磁盘索引节点 SFS中的磁盘索引节点代表了一个实际位于磁盘上的文件。
-
我正在从SDN3迁移到SDN4,从NEO4J2.3迁移到3.0。1. 我有以下搜索密码查询: 在我的测试中,Param等于以下Lucene查询: 就是现在 返回 但在SDN 3和Neo4j 2.3上运行良好,并返回节点。 这是我的Neo4jTestConfig: 我的配置可能有什么问题?如何使其在SDN 4上工作? 更新 此外,我发现以下答案无法使用InProcessServer()SDN 4配置
-
本文向大家介绍详解MySQL 聚簇索引与非聚簇索引,包括了详解MySQL 聚簇索引与非聚簇索引的使用技巧和注意事项,需要的朋友参考一下 1、聚集索引 表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。 从物理文件也可以看出 InnoD
-
本文向大家介绍详解sqlserver查询表索引,包括了详解sqlserver查询表索引的使用技巧和注意事项,需要的朋友参考一下 SELECT 索引名称=a.name ,表名=c.name ,索引字段名=d.name ,索引字段位置=d.colid 需创建索引 例如: 根据某列判断是否有重复记录,如果该列为非主键,则创建索引 根据经常查询的列,创建索引 无须创建索引 字段内容大部分一样,
-
本文向大家介绍ASP.NET web.config 配置节点详解,包括了ASP.NET web.config 配置节点详解的使用技巧和注意事项,需要的朋友参考一下 web.config 文件查找规则: (1)如果在当前页面所在目录下存在web.config文件,查看是否存在所要查找的结点名称,如果存在返回结果并停止查找。 (2)如果当前页面所在目录下不存在web.config文件或者web