
numpy中索引和切片详解

索引和切片
一维数组
一维数组很简单,基本和列表一致。
它们的区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始都会跟着更改)。
这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。
import numpy as np #导入numpy arr = np.arange(10) #类似于list的range() arr Out[3]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr[4] #索引(注意是从0开始的) Out[4]: 4 arr[3:6] #切片 Out[6]: array([3, 4, 5]) arr_old = arr.copy() #先复制一个副本 arr_old Out[8]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr[3:6] = 33 arr #可以发现将标量赋值给一个切片时,该值可以传播到整个选区 Out[10]: array([ 0, 1, 2, 33, 33, 33, 6, 7, 8, 9]) arr_old Out[11]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
二维数组
二维数组中,各索引位置上的元素不再是标量,而是一维数组(好像很难理解哈)。
arr1 = np.array([[1, 2, 3],[4, 5, 6],[7, 8, 9]]) arr1[0] Out[13]: array([1, 2, 3]) arr1[1,2] Out[14]: 6
好像很难理解,是吧。
那这样看:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
想到了什么?咱们当做一个平面直角坐标系。

相当于arr1[x,y],x相当于行数,y相当于列数(必须声明,图中x和y标反了,但不影响理解)。
多维数组
先说明下reshape()更改形状:
np.reshape(a,newshape,order='C')
a:array_like以一个数组为参数。
newshape:intortupleofints。整数或者元组
顺便说明下,np.reshape()不更改原数组形状(会生成一个副本)。
arr1 = np.arange(12)
arr2 = arr1.reshape(2,2,3) #将arr1变为2×2×3数组
arr2
Out[9]:
array([[[ 0, 1, 2],
[ 3, 4, 5]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
其实多维数组就相当于:
row * col * 列中列
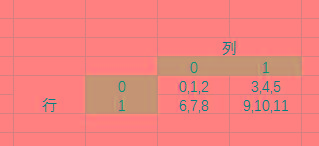
那么:
arr2[0]
Out[10]:
array([[0, 1, 2],
[3, 4, 5]])
arr2[1]
Out[11]:
array([[ 6, 7, 8],
[ 9, 10, 11]])
arr2[0,1]
Out[12]: array([3, 4, 5])
arr2[0] = 23 #赋值
arr2
Out[15]:
array([[[23, 23, 23],
[23, 23, 23]],
[[ 6, 7, 8],
[ 9, 10, 11]]])
切片索引
那么这样也就很容易的就可以理解下面这种索引了。
切片索引把每一行每一列当做一个列表就可以很容易的理解。
返回的都是数组。
再复杂一点:
我们想要获得下面这个数组第一行的第2,3个数值。
arr1 = np.arange(36)#创建一个一维数组。
arr2 = arr1.reshape(6,6) #更改数组形状。
Out[20]:
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
为了得到第2,3个数,我们可以:
arr2[0,2:4] Out[29]: array([2, 3])
可以发现ndarray的切片其实与列表的切片是差不太多的。
我们还可以这样:
arr2[1] #取得第2行
Out[37]: array([ 6, 7, 8, 9, 10, 11])
arr2[:,3] #取得第3列, 只有:代表选取整列(也就是整个轴)
Out[38]: array([ 3, 9, 15, 21, 27, 33])
arr2[1:4,2:4] # 取得一个二维数组
Out[40]:
array([[ 8, 9],
[14, 15],
[20, 21]])
arr2[::2,::2] #设置步长为2
Out[41]:
array([[ 0, 2, 4],
[12, 14, 16],
[24, 26, 28]])
arr3 = arr2.reshape(4,3,3)
arr3[2:,:1] = 22 #对切片表达式赋值
arr3
Out[25]:
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[22, 13, 14, 15, 16, 17],
[22, 19, 20, 21, 22, 23],
[22, 25, 26, 27, 28, 29],
布尔型索引
arr3 = (np.arange(36)).reshape(6,6)#生成6*6的数组
arr3
Out[35]:
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
x = np.array([0, 1, 2, 1, 4, 5])
x == 1#通过比较运算得到一个布尔数组
Out[42]: array([False, True, False, True, False, False], dtype=bool)
arr3[x == 1] #布尔索引
Out[43]:
array([[ 6, 7, 8, 9, 10, 11],
[18, 19, 20, 21, 22, 23]])
从结果上看,布尔索引取出了布尔值为True的行。
布尔型数组的长度和索引的数组的行数(轴长度)必须一致。
布尔型数组可与切片,整数(整数序列)一起使用。
arr3[x == 1,2:]#切片
Out[44]:
array([[ 8, 9, 10, 11],
[20, 21, 22, 23]])
arr3[x == 1,-3:]#切片
Out[47]:
array([[ 9, 10, 11],
[21, 22, 23]])
arr3[x == 1,3]#整数
Out[48]: array([ 9, 21])
!= 不等于符号。
~ 负号可以对条件进行否定。logical_not()函数也可以。
x != 1
Out[49]: array([ True, False, True, False, True, True], dtype=bool)
arr3[~(x == 1)] #实际类似于取反
Out[51]:
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
arr3[np.logical_not(x == 1)] #作用于 ~ 相同
Out[53]:
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[24, 25, 26, 27, 28, 29],
[30, 31, 32, 33, 34, 35]])
组合多个条件,使用布尔运算符&(和),|(或)
(x == 1 ) & (x == 4)#和
Out[67]: array([False, False, False, False, False, False], dtype=bool)
(x==1)|(x==4)#或
Out[68]: array([False, True, False, True, True, False], dtype=bool)
arr3[(x==1)|(x==4)]#布尔索引
Out[71]:
array([[ 6, 7, 8, 9, 10, 11],
[18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29]])
通过以上的代码实验,我们也可以发现,布尔索引不更改原数组,创建的都是原数组的副本。
那这个东西能做什么呢?其他索引能做的,他基本也都可以。
比如有这样一个数组:
arr5 = np.random.randn(4,4)#randn返回一个服从标准正态分布的数组。
arr5
Out[77]:
array([[-0.64670829, 1.53428435, 0.20585387, 0.42680995],
[-0.63504514, 0.54542881, -0.82163028, -0.89835051],
[-0.66770299, 0.22617913, 0.16358189, -0.75074314],
[-0.25439447, -0.96135628, -0.10552532, -1.06962358]])
我们要将arr5大于0的数值变为10:
arr5[arr5 > 0] = 10
arr5
Out[80]:
array([[ -0.64670829, 10. , 10. , 10. ],
[ -0.63504514, 10. , -0.82163028, -0.89835051],
[ -0.66770299, 10. , 10. , -0.75074314],
当然,布尔索引也可以结合上面的运算符来进行操作。
花式索引
花式索引(Fancy indexing),指的是利用整数数组进行索引。
第一次看到这个解释,我是一脸懵的。
试验后,我才理解。
arr6 = np.empty((8,4))# 创建新数组,只分配内存空间,不填充值
for i in range(8):#给每一行赋值
arr6[i] = i
arr6
Out[5]:
array([[ 0., 0., 0., 0.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.],
[ 4., 4., 4., 4.],
[ 5., 5., 5., 5.],
[ 6., 6., 6., 6.],
[ 7., 7., 7., 7.]])
arr6[[2,6,1,7]] #花式索引
Out[14]:
array([[ 2., 2., 2., 2.],
[ 6., 6., 6., 6.],
[ 1., 1., 1., 1.],
[ 7., 7., 7., 7.]])
我们可以看到花式索引的结果,以一个特定的顺序排列。
而这个顺序,就是我们所传入的整数列表或者ndarray。
这也为我们以特定的顺序来选取数组子集,提供了思路。
arr6[2] Out[15]: array([ 2., 2., 2., 2.]) arr6[6] Out[17]: array([ 6., 6., 6., 6.]) arr6[1] Out[18]: array([ 1., 1., 1., 1.])
可以看到,花式索引的结果与普通索引是一致的。只不过,花式索引简化了索引过程,而且还实现了按一定的顺序排列。
还可以使用负数(其实类似于列表)进行索引。
arr6[[-2,-6,-1]]
Out[21]:
array([[ 6., 6., 6., 6.],
[ 2., 2., 2., 2.],
[ 7., 7., 7., 7.]])
一次传入多个索引数组,会返回一个一维数组,其中的元素对应各个索引元组。
有点懵。
arr7 = np.arange(35).reshape(5,7)#生成一个5*7的数组
arr7
Out[24]:
array([[ 0, 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12, 13],
[14, 15, 16, 17, 18, 19, 20],
[21, 22, 23, 24, 25, 26, 27],
[28, 29, 30, 31, 32, 33, 34]])
arr7[[1,3,2,4],[2,0,6,5]]
Out[27]: array([ 9, 21, 20, 33])
经过对比可以发现,返回的一维数组中的元素,分别对应(1,2)、(3,0)....
这一样一下子就清晰了,我们传入来两个索引数组,相当于传入了一组平面坐标,从而进行了定位。
此处,照我这样理解的话,那么一个N维数组,我传入N个索引数组的话,是不是相当于我传入了一个N维坐标。
我试验了下三维,是这样的,但是以后的不知道了。谁知道求告诉。
ar = np.arange(27).reshape(3,3,3)
ar
Out[31]:
array([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]],
[[18, 19, 20],
[21, 22, 23],
[24, 25, 26]]])
ar[[1,2],[0,1],[2,2]]
Out[32]: array([11, 23])
那么应该如何得到一个矩形区域呢。可以这样做:
arr7[[1,3,2,4]][:,[2,0,6,5]]
Out[33]:
array([[ 9, 7, 13, 12],
[23, 21, 27, 26],
[16, 14, 20, 19],
[30, 28, 34, 33]])
必须明白,arr7[2][3]等价于arr7[2,3]
那么上面这种得到矩形区域的方法,就相当于行与列去了交集。
此外还可用np.ix_函数,它的作用与上面的方法类似,只不过是将两个一维的数组转换为了一个可以选择矩形区域的索引器。
arr7[np.ix_([1,3,2,4],[2,0,6,5])]
Out[34]:
array([[ 9, 7, 13, 12],
[23, 21, 27, 26],
[16, 14, 20, 19],
[30, 28, 34, 33]])
通过,这些试验,还可发现,花式索引将数据复制到了一个新的数组中。
总结
以上就是本文关于numpy中索引和切片详解的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站:
利用numpy实现一、二维数组的拼接简单代码示例
numpy自动生成数组详解
numpy排序与集合运算用法示例
如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
-
主要内容:基本切片,多维数组切片在 NumPy 中,如果想要访问,或修改数组中的元素,您可以采用索引或切片的方式,比如使用从 0 开始的索引依次访问数组中的元素,这与 Python 的 list 列表是相同的。 NumPy 提供了多种类型的索引方式,常用方式有两种:基本切片与高级索引。本节重点讲解基本切片。 基本切片 NumPy 内置函数 slice() 可以用来构造切片对象,该函数需要传递三个参数值分别是 start(起始索引
-
本文向大家介绍浅析NumPy 切片和索引,包括了浅析NumPy 切片和索引的使用技巧和注意事项,需要的朋友参考一下 ndarray对象的内容可以通过索引或切片来访问和修改,与 Python 中 list 的切片操作一样。 ndarray 数组可以基于 0 - n 的下标进行索引,切片对象可以通过内置的 slice 函数,并设置 start, stop 及 step 参数进行,从原数组中切割出一个新
-
Python 的内置容器对象,例如列表,可以通过索引或切片来访问和修改。这在 ndarray 对象中也一样,ndarray 对象中的元素遵循基于零的索引,常用的索引方式:元素访问、切片索引、布尔型索引。 1. 元素访问 1.1 单一元素访问 一维数组的元素访问非常简单,和 Python 列表规则基本差不多。对单一元素的访问,索引遵循从 0 开始,依次递增 1。 案例 例如,对于创建的一维数组,我们
-
如前所述,对象中的元素遵循基于零的索引。 有三种可用的索引方法类型: 字段访问,基本切片和高级索引。 基本切片是 Python 中基本切片概念到 n 维的扩展。 通过将start,stop和step参数提供给内置的slice函数来构造一个 Python slice对象。 此slice对象被传递给数组来提取数组的一部分。 输出如下: [2 4 6] 在上面的例子中,ndarray对象由arang
-
本文向大家介绍NumPy 基本切片和索引的具体使用方法,包括了NumPy 基本切片和索引的具体使用方法的使用技巧和注意事项,需要的朋友参考一下 索引和切片是NumPy中最重要最常用的操作。熟练使用NumPy切片操作是数据处理和机器学习的前提,所以一定要掌握好。 文档:https://docs.scipy.org/doc/numpy/reference/arrays.indexing.html 索引
-
本文向大家介绍python numpy数组的索引和切片的操作方法,包括了python numpy数组的索引和切片的操作方法的使用技巧和注意事项,需要的朋友参考一下 NumPy - 简介 NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。 Numeric,即 NumPy 的前身,是由 Jim Hugunin 开