
深入了解java8的foreach循环

虽然java8出来很久了,但是之前用的一直也不多,最近正好学习了java8,推荐一本书还是不错的<写给大忙人看的javase8>。因为学习了Java8,所以只要能用到的地方都会去用,尤其是Java8的Stream,感觉用起来觉得很方便,因为点点点就出来了,而且代码那么简洁。现在开始慢慢深入了解java8,发现很多东西不能看表面。
比如常规遍历一个集合,下面给出例子:
1.首先遍历一个List
方式1.一开始是这样的:
public static void test1(List<String> list) {
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
方式2.当然稍微高级一点的是这样:
public static void test2(List<String> list) {
for (int i = 0,lengh=list.size(); i < lengh; i++) {
System.out.println(list.get(i));
}
}
方式3.还有就是Iterator遍历:
public static void test3(List<String> list) {
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
}
方式4.后来有了增强for循环:
public static void test4(List<String> list) {
for(String str:list){
System.out.println(str);
}
}
方式5.java8以后新增的方式:
public static void test5(List<String> list) {
//list.forEach(System.out::println);和下面的写法等价
list.forEach(str->{
System.out.println(str);
});
}
方式6.还有另一种:
public static void test6(List<String> list) {
list.iterator().forEachRemaining(str->{
System.out.println(str);
});
}
应该没有其他的了吧,上面六中方法,按我的使用习惯5最常用,4偶尔使用,其他的基本就不怎么用了,使用5的原因是因为方便书写,提示就可以写出来,偶尔使用4的原因是,5不方便计数用,下面进行性能测试,String不具备代表性,决定使用对象,简单的一个测试类如下:
一个简单的测试,内容不要太在意,简单计算hashCode:
package test;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class Test8 {
public static void main(String[] args) {
List<Dog> list=new ArrayList<>();
for(int i=0;i<10;i++){
list.add(new Dog(i,"dog"+i));
}
long nanoTime = System.nanoTime();
test1(list);
long nanoTime1 = System.nanoTime();
test2(list);
long nanoTime2 = System.nanoTime();
test3(list);
long nanoTime3 = System.nanoTime();
test4(list);
long nanoTime4 = System.nanoTime();
test5(list);
long nanoTime5 = System.nanoTime();
test6(list);
long nanoTime6 = System.nanoTime();
System.out.println((nanoTime1-nanoTime)/1000000.0);
System.out.println((nanoTime2-nanoTime1)/1000000.0);
System.out.println((nanoTime3-nanoTime2)/1000000.0);
System.out.println((nanoTime4-nanoTime3)/1000000.0);
System.out.println((nanoTime5-nanoTime4)/1000000.0);
System.out.println((nanoTime6-nanoTime5)/1000000.0);
}
public static void test1(List<Dog> list) {
for (int i = 0; i < list.size(); i++) {
list.get(i).hashCode();
}
}
public static void test2(List<Dog> list) {
for (int i = 0,lengh=list.size(); i < lengh; i++) {
list.get(i).hashCode();
}
}
public static void test3(List<Dog> list) {
Iterator<Dog> iterator = list.iterator();
while(iterator.hasNext()){
iterator.next().hashCode();
}
}
public static void test4(List<Dog> list) {
for(Dog dog:list){
dog.hashCode();
}
}
public static void test5(List<Dog> list) {
//list.forEach(System.out::println);和下面的写法等价
list.forEach(dog->{
dog.hashCode();
});
}
public static void test6(List<Dog> list) {
list.iterator().forEachRemaining(dog->{
dog.hashCode();
});
}
}
class Dog{
private int age;
private String name;
public Dog(int age, String name) {
super();
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog [age=" + age + ", name=" + name + "]";
}
}
运行三次取平均值,机器配置就不说了,因为我不是比较的绝对值,我是比较的这几种方式的相对值,数据结果,趋势图如下:
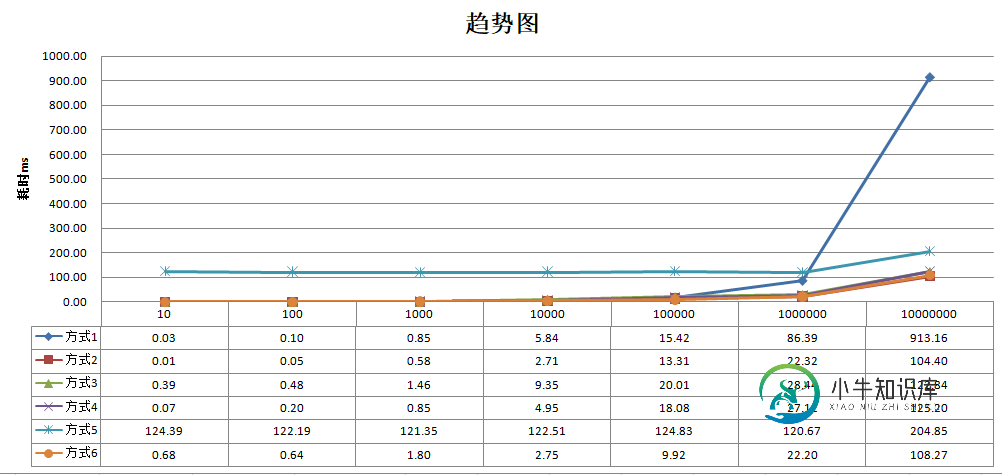
然后去掉表现一直很稳定的方式5和百万级数据量以上的数据,来分析结果:

可以得出一个非常吓人的结果,java8的foreach每次循环的耗时竟然高达100毫秒以上,虽然它比较稳定(算是优点吧)。所以得出以下结论:
在正常使用(数据量少于百万以下),正常(非并行)遍历一个集合的时候:
•不要使用java8的foreach,每次耗时高达100毫秒以上
•提前计算出大小的普通for循环,耗时最小,但是书写麻烦
•增强for循环表现良好
2.再次遍历一个Set
使用以相同的方式测试HashSet,测试方法如下:
package test;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test9 {
public static void main(String[] args) {
Set<Dog> set = new HashSet<>();
for (int i = 0; i < 10_000_000; i++) {
set.add(new Dog(i, "dog" + i));
}
long nanoTime = System.nanoTime();
test1(set);
long nanoTime1 = System.nanoTime();
test2(set);
long nanoTime2 = System.nanoTime();
test3(set);
long nanoTime3 = System.nanoTime();
test4(set);
long nanoTime4 = System.nanoTime();
System.out.println((nanoTime1 - nanoTime) / 1000000.0);
System.out.println((nanoTime2 - nanoTime1) / 1000000.0);
System.out.println((nanoTime3 - nanoTime2) / 1000000.0);
System.out.println((nanoTime4 - nanoTime3) / 1000000.0);
}
public static void test1(Set<Dog> list) {
Iterator<Dog> iterator = list.iterator();
while (iterator.hasNext()) {
iterator.next().hashCode();
}
}
public static void test2(Set<Dog> list) {
for (Dog dog : list) {
dog.hashCode();
}
}
public static void test3(Set<Dog> list) {
list.forEach(dog -> {
dog.hashCode();
});
}
public static void test4(Set<Dog> list) {
list.iterator().forEachRemaining(dog -> {
dog.hashCode();
});
}
}
经过计算得出如下结果:
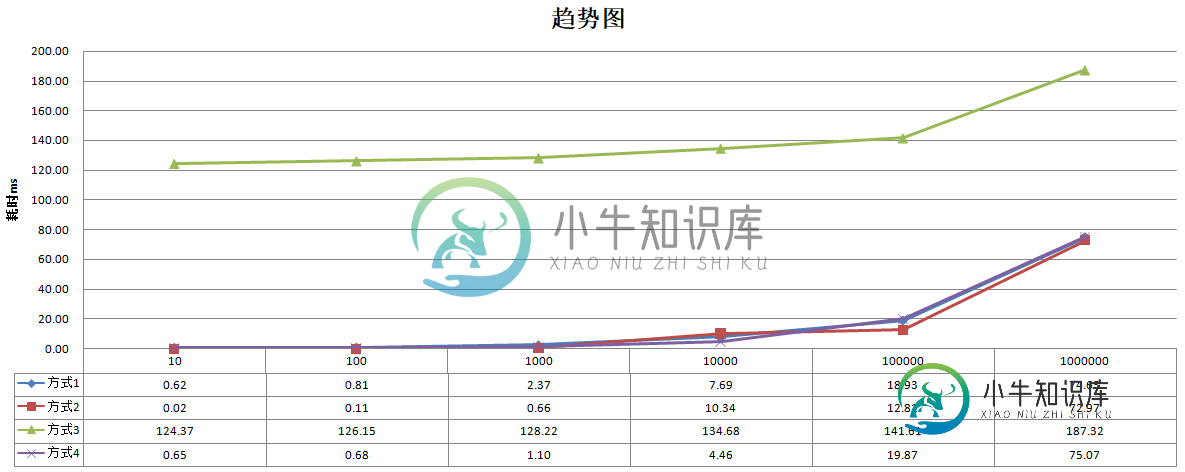
不难发现,java8的foreach依然每次耗时100ms以上,最快的变成了增强for循环,Iterator遍历和java8的iterator().forEachRemaining差不多。
3.最后遍历Map
依然使用相同的方式测试Map集合遍历,测试类如下:
package test;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Test10 {
public static void main(String[] args) {
Map<String, Dog> map = new HashMap<>();
for (int i = 0; i < 1000_000; i++) {
map.put("dog" + i, new Dog(i, "dog" + i));
}
long nanoTime = System.nanoTime();
test1(map);
long nanoTime1 = System.nanoTime();
test2(map);
long nanoTime2 = System.nanoTime();
test3(map);
long nanoTime3 = System.nanoTime();
test4(map);
long nanoTime4 = System.nanoTime();
System.out.println((nanoTime1 - nanoTime) / 1000000.0);
System.out.println((nanoTime2 - nanoTime1) / 1000000.0);
System.out.println((nanoTime3 - nanoTime2) / 1000000.0);
System.out.println((nanoTime4 - nanoTime3) / 1000000.0);
}
public static void test1(Map<String, Dog> map) {
Iterator<Map.Entry<String, Dog>> entries = map.entrySet().iterator();
while (entries.hasNext()) {
Map.Entry<String, Dog> entry = entries.next();
int code=entry.getKey().hashCode()+entry.getValue().hashCode();
}
}
public static void test2(Map<String, Dog> map) {
for (Map.Entry<String, Dog> entry : map.entrySet()) {
int code=entry.getKey().hashCode()+entry.getValue().hashCode();
}
}
public static void test3(Map<String, Dog> map) {
for (String key : map.keySet()) {
int code=key.hashCode()+map.get(key).hashCode();
}
}
public static void test4(Map<String, Dog> map) {
map.forEach((key, value) -> {
int code=key.hashCode()+value.hashCode();
});
}
}
结果如下:

java8的foreach依然不负众望,最快的是增强for循环。
最终结论
普通(数量级10W以下,非并行)遍历一个集合(List、Set、Map)如果在意效率,不要使用java8的foreach,虽然它很方便很优雅
任何时候使用增强for循环是你不二的选择
以上所述是小编给大家介绍的java8的foreach循环 ,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
-
本文向大家介绍深入了解PHP中的Array数组和foreach,包括了深入了解PHP中的Array数组和foreach的使用技巧和注意事项,需要的朋友参考一下 1. 了解数组 PHP 中的数组实际上是一个有序映射。映射是一种把 values 关联到 keys 的类型。详细的解释可参见:PHP.net中的Array数组 。 2.例子:一般的数组 这里,我通过一个简单的例子,并使用图形方式来了解
-
logstash 已经拥有数以百计的插件,并提供了一站式的部署方式,极大的方便了新手入门。但在实际运用上,我们终究会碰上其他人还没碰到过,或者碰到过但没公布出来完整解决方案的问题。可能是某些环境适配,可能是某个环节的性能不佳,可能是某处硬编码设置不合理,等等等等。这时候,了解一些 logstash 的代码逻辑,了解 logstash 之所以做出当前选择的缘由。是有助于解决实际问题的。 此外,log
-
问题内容: 我试图了解如何使用Golang和forks。情况如下,我在写一个依赖于library的库,这不是我的。 由于缺少我需要的一些方法,因此将其分叉到。但是,我不能只是这样做,库引用了自己,所以它坏了。 在本文中,他们提供了可能的解决方案: 现在,这充其量是hacky。从库代码中无法得知依赖项来自其他存储库。任何使用我的图书馆的人都无法使其正常运行。 由于dep有望成为正式的依赖管理器。我发
-
在这本教程的一开始 (第 6 章, 构建脚本基础) 你已经学习了如何创建简单的任务. 然后你也学习了如何给这些任务加入额外的行为, 以及如何在任务之间建立依赖关系. 这些仅仅是用来构建简单的任务. Gradle 可以创建更为强大复杂的任务. 这些任务可以有它们自己的属性和方法. 这一点正是和 Ant targets 不一样的地方. 这些强大的任务既可以由你自己创建也可以使用 Gradle 内建好的
-
在这篇文章中我将向你演示如何使用Java8中的foreach操作List和Map 1. Foreach操作Map 1.1 正常方式遍历Map Map<String, Integer> items = new HashMap<>(); items.put("A", 10); items.put("B", 20); items.put("C", 30); items.put("D", 40); ite
-
为了试图深入理解Java流和spliterator,我有一些关于spliterator特性的微妙问题: Q1:与(不带参数的stream.of()) :已沉降,大小 :沉降的、不可变的、有大小的、有序的 为什么不具有相同的特性?请注意,当它与stream.concat()结合使用时(特别是没有)会产生影响。我想说不仅应该具有不可变和有序性,而且还应该具有DISTINCT和nonnull。只有一个参