
Python math库 ln(x)运算的实现及原理

这个是很有用的一个运算,除了本身可以求自然对数,还是求指数函数需要用到的基础函数。
实现原理就是泰勒展开,最简单是在x=1处进行泰勒展开:
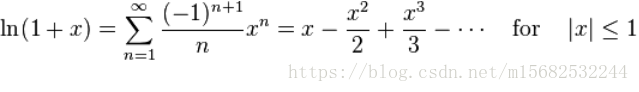
但该函数离1越远越难收敛,同时大于2时无法收敛,所以需要进行换元,然后重新展开:
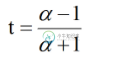

但是该换元在接近0时或者接近无穷大时收敛困难,处在1到10范围内收敛快且精度高,所以对大于10或小于1的值进行分解如下:
ln(55000)=ln(5.5)+4ln10
ln(0.0015)=ln(1.5)-4ln10
ln10为算好的值,可直接由ln_h1(10)得到
Epsilon 为精度控制
输出的i可以检测收敛次数。
Epsilon = 10e-16
ln10 = 2.30258509299404568401
def ln_h(x):
'''
ln函数泰勒换元展开
:param x: 0<x
:return:ln(x)
'''
def ln_h1(x):
s2 = 0.0
delta = x = (x - 1.0) / (x + 1.0)
i = 0
while fab_h(delta * 2) / (i * 2 + 1) > Epsilon:
s2 += delta / (i * 2 + 1)
delta *= x * x
i += 1
print(i)
return 2 * s2
coef = 0
if x > 10:
while x / 10 > 1:
coef += 1
x /= 10
return ln_h1(x) + coef*ln10
elif x < 1:
while x * 10 < 10:
coef += 1
x *= 10
return ln_h1(x) - coef*ln10
else:
return ln_h1(x)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
据我所知,Java中的String concatenation""运算符是使用Stringbuilder实现的,例如: 内部编译为: 所以我尝试了这样的东西: 接下来,我使用==运算符相互测试了这些。结果主要是我所期望的:foo2和foo4没有为任何其他字符串返回“==”。 但是,fo3==fo1返回true。这是什么原因?StringBuilder类的toString方法内部调用“new Str
-
本文向大家介绍MySQL8.0 DDL原子性特性及实现原理,包括了MySQL8.0 DDL原子性特性及实现原理的使用技巧和注意事项,需要的朋友参考一下 1. DDL原子性概述 8.0之前并没有统一的数据字典dd,server层和引擎层各有一套元数据,sever层的元数据包括(.frm,.opt,.par,.trg等),用于存储表定义,分区表定义,触发器定义等信息;innodb层也有自己一套元数据,
-
问题内容: 我已经尝试实现sizeof运算符。 但是,对于任何一种数据类型,结果总是以“ 1”表示。 然后,我为此搜索了一下..,我发现代码是 强制转换的 如果代码是强制转换的,那么代码也可以正常工作。.我不明白为什么..该代码也完美地填充了结构。 它也为 有人能解释一下如果进行类型转换和未进行类型转换如何工作吗? 提前致谢.. 问题答案: 指针减法的结果以 元素 为单位,而不是以字节为单位。因此
-
本文向大家介绍pandas DataFrame运算的实现,包括了pandas DataFrame运算的实现的使用技巧和注意事项,需要的朋友参考一下 1 算术运算 add(other) 比如进行数学运算加上具体的一个数字 sub(other) 2 逻辑运算 2.1 逻辑运算符号 例如筛选data[“open”] > 23的日期数据 data[“open”] > 23返回逻辑结果 完成多个逻辑判断,
-
本文向大家介绍Kmeans均值聚类算法原理以及Python如何实现,包括了Kmeans均值聚类算法原理以及Python如何实现的使用技巧和注意事项,需要的朋友参考一下 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给定两个质心,我们这个算法的目的就是将这一堆点根据它们自身的坐标特征分为两类,因此选取了两个质心,什么时候这一堆点能够根据这两
-
我正在寻找一种通用模式来分解一些常见的代码:我需要在具有不同算术属性的类之间实现代数加法和减法。一个典型的例子是可以用秒、小时和分钟表示的间隔,我用一个具有三个int属性的类实现了它。 例如,如果我想减去0秒、0分钟、1小时的周期,减去0秒、30分钟、0小时的周期,我不想获得0秒、-30分钟、1小时的周期。 我需要编码两个时间间隔之间的加减法,有没有通用的模式来编码这个代数?我应该寻找不同的代表吗