
使用python实现ANN

本文实例为大家分享了python实现ANN的具体代码,供大家参考,具体内容如下
1.简要介绍神经网络
神经网络是具有适应性的简单单元组成的广泛并行互联的网络。它的组织能够模拟生物神经系统对真实世界物体做做出的反应。神经网络的最基本的成分是神经元模型,也就是最简单的神经元模型。
“M-P模型”
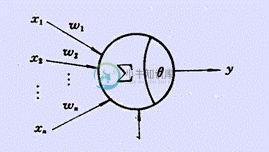
如上图所示,神经元接收到来自n个其他神经元传递过来的输入信号,这些信号通过带权重的链接进行传递。神经元接收到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”处理以产生神经元的输出
激活函数:
理想的激活函数应该是阶跃函数,也就是它能够将输入值映射成为输出值0或1。其中“0”代表神经元抑制,“1”代表神经元兴奋。但是由于阶跃函数不连续且不可导,因此实际上常常使用sigmoid函数当做神经元的激活函数。它能够将可能在较大范围内变化的输出值挤压到(0,1)之间这个范围内。因此有时也成为挤压函数。常用的sigmoid函数是回归函数
f(x) = 1/(1+e^(-x))
如下图所示:

感知机:
感知机是最简单的神经网络,它由两层神经元组成。输入层接受外界信号后传递给输出层。输出层是M-P神经元。感知机也成为阈值逻辑单元。感知机可以通过采用监督学习来逐步增强模式划分的能力,达到学习的目的。
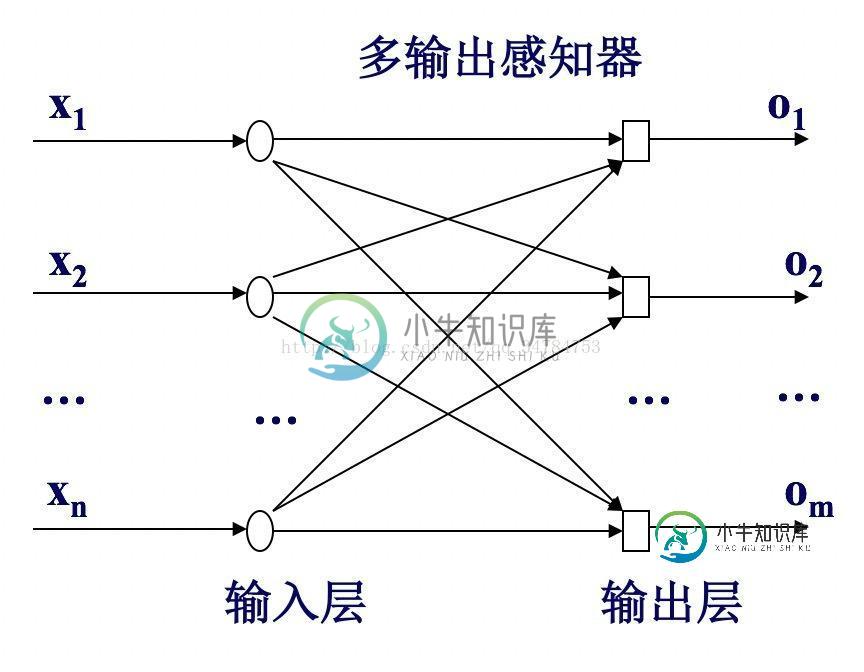
感知机能够实现简单的逻辑运算。
一般的,对于给定训练数据集,权重Wi以及阈值θ可以通过学习得到。其中阈值(bias)可以通过学习得到。在输出神经元中,阈值可以看做是一个固定输入为-1,0的哑结点,所对应的连接权重为Wn+1,从而使得权重和阈值的学习统一为权重的学习。
感知机的学习规则非常简单,对于训练样本(X,y),若当前感知机输出为y',则感知机做如下调整
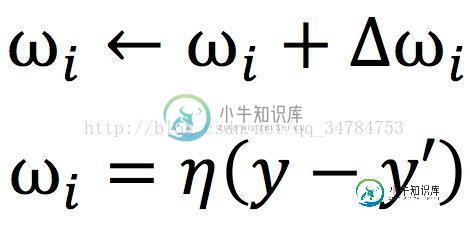
其中,η属于(0,1),称为“学习率”
若感知机对训练样例预测正确,则感知机不发生变化,否则将根据错误的程度进行权重的调整。
需要注意的是,感知机只有输出神经元进行激活函数处理,因此它的学习能力非常有限,也就是因为它只有一层功能神经元。
可以证明,若两类模式实现性可分的,即存在一个超平面可以将他们分开,则利用感知机一定会收敛,可以求得一个权向量。否则,感知机的学习过程将会发生震荡,导致参数难以稳定下来,不等求得合适的解。例如,单层感知机不能解决抑或问题。
如果想要解决非线性可分问题,考虑使用多层功能神经元。
前馈神经网络
每层神经元与下一层神经元全互联,神经元之间不存在同层链接,也不存在跨曾链接。其中输入层神经元有由外界进行输入,隐藏层与输出层神经元对信号进行加工,最终结果由输出层神经元进行输出。输入层神经元仅仅起到接受输入的功能,并不进行函数处理。
所谓的神经网络的学习过程,也就是根据训练数据来调整神经元之间的“连接权”以及每个功能神经元的阈值,换句话说,神经网络能够“学习”到的东西,全部都蕴含在“连接权”与“阈值”之中
BP算法(误差逆传播算法)
BP算法,也成为反向传播算法
•在感知器算法中我们实际上是在利用理想输出与实际输出之间的误差作为增量来修正权值,然而在多层感知器中,我们只能计算出输出层的误差,中间隐层由于不直接与外界连接,其误差无法估计。
•反向传播算法(BP算法)的思想:从后向前反向逐层传播输出层的误差,以间接计算隐层的误差。算法可以分为两个阶段:
–正向过程:从输入层经隐层逐层正向计算各单元的输出;
–反向过程:由输出误差逐层反向计算隐层各单元的误差,并用此误差修正前层的权值。
B-P算法的学习过程如下:
(1)选择一组训练样例,每一个样例由输入信息和期望的输出结果两部分组成。
(2)从训练样例集中取一样例,把输入信息输入到网络中。
(3)分别计算经神经元处理后的各层节点的输出。
(4)计算网络的实际输出和期望输出的误差。
(5)从输出层反向计算到第一个隐层,并按照某种能使误差向减小方向发展的原则,调整网络中各神经元的连接权值。
(6)对训练样例集中的每一个样例重复(3)-(5)的步骤,直到对整个训练样例集的误差达到要求时为止。
•优点:
–理论基础牢固,推导过程严谨,物理概念清晰,通用性好等。所以,它是目前用来训练前馈多层网络较好的算法。
•缺点:
–BP算法的收敛速度一般来说比较慢;
–BP算法只能收敛于局部最优解,不能保证收敛于全局最优解;
–当隐层元的数量足够多时,网络对训练样本的识别率很高,但对测试样本的识别率有可能很差,即网络的推广能力有可能较差。
具体的公式在这里不再给出,因为相关的资料也有很多,可以随时查阅。
可以证明:
只需要一个包含足够多的神经元的因曾,多层前馈网络能够以任意精度逼近任意复杂度的连续函数。而主要的问题是:如何设置隐层神经元的个数?
考虑采用”试错法“
因为前馈网络具有强大地表示能力,因此BP算法有时会出现过拟合的现象,对于过拟合,采用的主要策略是早停和正则化:
早停:将数据集分为训练集和验证集,训练集用来计算梯度,更新连接权值和阈值,验证集用来估计误差,若训练集误差降低但验证集误差升高,则立即停止训练。返回具有最小验证集误差的连接权和阈值。
正则化:在误差目标函数中增加一个用来描述网络复杂度的部分。例如连接权与阈值的平方和,仍令Ek为第k个训练样例上误差,Wi表示链接权和阈值,则误差目标函数定义为:
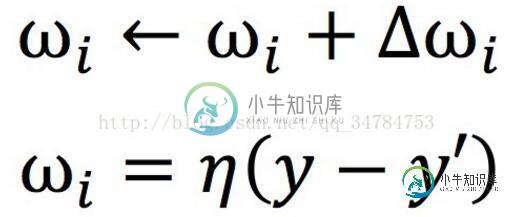
其中λ属于(0,1),用对经验误差与网络复杂度这两项进行这种,使用”交叉验证“
2.使用python和机器学习库sklearn库编程实现:
# coding=utf-8 # 使用Python构建ANN import numpy as np # 双曲函数 def tanh(x): return np.tanh(x) # 双曲函数的微分 def tanh_deriv(x): return 1.0 - np.tanh(x) * np.tanh(x) # 逻辑函数 def logistics(x): return 1 / (1+np.exp(-x)) # 逻辑函数的微分 def logistics_derivative(x): return logistics(x)*(1-logistics(x)) # 使用类 面向对象的技巧 建立ANN class NeuralNetwork: # 构造函数 layers指的是每层内有多少个神经元 layers内的数量表示有几层 # acvitation 为使用的激活函数名称 有默认值 tanh 表示使用tanh(x) def __init__(self,layers,activation='tanh'): if activation == 'logistic': self.activation = logistics self.activation_deriv = logistics_derivative elif activation == 'tanh': self.activation = tanh self.activation = tanh_deriv self.weight =[] # len(layers)-1的目的是 输出层不需要赋予相应的权值 for i in range(1,len(layers) - 1): # 第一句是对当前层与前一层之间的连线进行权重赋值,范围在 -0.25 ~ 0.25之间 self.weight.append((2*np.random.random((layers[i-1]+1,layers[i]+1))-1)*0.25) # 第二句是对当前层与下一层之间的连线进行权重赋值,范围在 -0.25 ~ 0.25之间 self.weight.append((2*np.random.random((layers[i]+1,layers[i+1]))-1)*0.25) def fit(self,X,y,learning_rate = 0.2,epochs = 10000): # self是指引当前类的指针 X表示训练集 通常模拟成一个二维矩阵,每一行代表一个样本的不同特征 # 每一列代表不同的样本 y指的是classLabel 表示的是输出的分类标记 # learning_rate是学习率,epochs表示循环的次数 X = np.atleast_2d(X) # 将X转换为numpy2维数组 至少是2维的 temp = np.ones([X.shape[0],X.shape[1]+1]) # X.shape[0]返回的是X的行数 X.shape[1]返回的是X的列数 temp[:,0:-1] = X # :指的是所有的行 0:-1指的是从第一列到除了最后一列 X = temp # 偏向的赋值 y = np.array(y) # 将y转换为numpy array的形式 # 使用抽样的算法 每次随机选一个 x中的样本 for k in range(epochs): # randint(X.shape[0])指的是从0~X.shape[0] 之间随机生成一个int型的数字 i = np.random.randint(X.shape[0]) a = [X[i]] # a是从x中任意抽取的一行数据 #正向更新 for l in range(len(self.weight)): # 循环遍历每一层 # dot是求内积的运算 将内积运算的结果放在非线性转换方程之中 a.append(self.activation(np.dot(a[l], self.weight[l]))) error = y[i] - a[-1] # 求误差 a[-1]指的是最后一层的classLabel deltas = [error * self.activation_deriv(a[-1])] # 开始反向传播 从最后一层开始,到第0层,每次回退1层 for l in range(len(a) - 2,0,-1): deltas.append(deltas[-1].dot(self.weight[l].T)*self.activation_deriv(a[l])) deltas.reverse() for i in range(len(self.weight)): layer = np.atleast_2d(a[i]) delta = np.atleast_2d(deltas[i]) # delta存的是误差 self.weight[i] += learning_rate * layer.T.dot(delta) # 误差与单元格的值的内积 # 预测过程 def predict(self,x): x=np.array(x) temp = np.ones(x.shape[0]+1) temp[0:-1] = x a = temp for l in range(0,len(self.weight)): a = self.activation(np.dot(a,self.weight[l])) return a
使用简单的程序进行测试
# coding=utf-8 from ANN import NeuralNetwork import numpy as np nn = NeuralNetwork([2, 2, 1], 'tanh') X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) y = np.array([0, 1, 1, 0]) nn.fit(X, y) for i in [[0, 0], [0, 1], [1, 0], [1, 1]]: print(i, nn.predict(i))
执行后,输出的结果为:
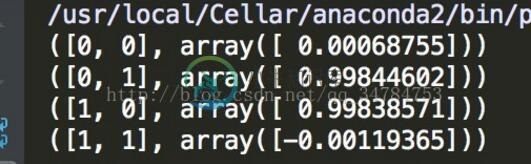
End.
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍使用python实现链表操作,包括了使用python实现链表操作的使用技巧和注意事项,需要的朋友参考一下 一、概念梳理 链表是计算机科学里面应用应用最广泛的数据结构之一。它是最简单的数据结构之一,同时也是比较高阶的数据结构(例如棧、环形缓冲和队列) 简单的说,一个列表就是单数据通过索引集合在一起。在C里面这叫做指针。比方说,一个数据元素可以由地址元素,地理元素、路由信息活着交易细节等
-
本文向大家介绍使用python实现生成用户信息,包括了使用python实现生成用户信息的使用技巧和注意事项,需要的朋友参考一下 今天练习的时候要展示一个从用户信息列表,就想把他做成信息和修改在一起的一个网页,方便用户修改内容 考虑到要把信息和值分开放,那么肯定是字典了,因为需要保证位置不变,使用有序字典 考虑到需要解析方便和好看点,所以让models.py中返回的就直接是”k1 v1 k2 v2”
-
本文向大家介绍使用Python & Flask 实现RESTful Web API的实例,包括了使用Python & Flask 实现RESTful Web API的实例的使用技巧和注意事项,需要的朋友参考一下 环境安装: sudo pip install flask Flask 是一个Python的微服务的框架,基于Werkzeug, 一个 WSGI 类库。 Flask 优点: Written
-
本文向大家介绍使用python实现rsa算法代码,包括了使用python实现rsa算法代码的使用技巧和注意事项,需要的朋友参考一下 RSA算法是一种非对称加密算法,是现在广泛使用的公钥加密算法,主要应用是加密信息和数字签名。 维基百科给出的RSA算法简介如下: 假设Alice想要通过一个不可靠的媒体接收Bob的一条私人讯息。她可以用以下的方式来产生一个公钥和一个私钥: 随意选择两个大的质数p和q,
-
本文向大家介绍使用python实现kNN分类算法,包括了使用python实现kNN分类算法的使用技巧和注意事项,需要的朋友参考一下 k-近邻算法是基本的机器学习算法,算法的原理非常简单: 输入样本数据后,计算输入样本和参考样本之间的距离,找出离输入样本距离最近的k个样本,找出这k个样本中出现频率最高的类标签作为输入样本的类标签,很直观也很简单,就是和参考样本集中的样本做对比。下面讲一讲用pytho
-
我在windows上使用python 3,使用Selenium包使用Chrome进行web爬行。我在一台新电脑上运行,做的一切都一样,但在第一次运行时立即出现以下错误。我从未见过这种例外。任何人都熟悉它,并能提供一些线索?谢谢 异常会在驱动程序调用的开头立即发生: 更新:升级到chromeDriver2.4后,有一个我以前从未见过的不同错误: WebDriverException:未知错误:无法发