
1秒50万字!js实现关键词匹配

在论坛和聊天室这样的场景里,为了保证用户体验,我们经常需要屏蔽很多不良词语。对于单个关键词查找,自然是indexOf、正则那样的方式效率比较高。但对于关键词较多的情况下,多次重复调用indexOf、正则的话去匹配全文的话,性能消耗非常大。由于目标字符串通常来说体积都比较大,所以必须要保证一次遍历就得到结果。根据这样的需求,很容易就想到对全文每个字符依次匹配的方式。比如对于这段文字:“Mike Jordan had said "Just do IT", so Mark has been a coder.”,假如我们的关键词是“Mike”“Mark”,那么可以遍历整句话,当找到“M”就接着看能不能匹配到“i”或者“a”,能一直匹配到最后则成功找到一个关键词,否则继续遍历。那么关键词的结构就应该是这样的:
var keywords = {
M: {
i: {
k: {
e: {end: true}
}
},
a: {
r: {
k: {end: true}
}
}
}
}
由上文可以看出这个数据就是一个树结构,而根据关键词组来创建树结构还是比较耗时的,而关键词却又是我们早已给定的,所以可以在匹配前预先创建这样的数据结构。代码如下:
function buildTree(keywords) {
var tblCur = {},
key, str_key, Length, j, i;
var tblRoot = tblCur;
for(j = keywords.length - 1; j >= 0; j -= 1) {
str_key = keywords[j];
Length = str_key.length;
for(i = 0; i < Length; i += 1) {
key = str_key.charAt(i);
if(tblCur.hasOwnProperty(key)) {
tblCur = tblCur[key];
} else {
tblCur = tblCur[key] = {};
}
}
tblCur.end = true; //最后一个关键字
tblCur = tblRoot;
}
return tblRoot;
}
这段代码中用了一个连等语句:tblCur = tblCur[key] = {},这里要注意的是语句的执行顺序,由于[]的运算级比=高,所以首先是在 tblCur对象中先创建一个key属性。结合tblRoot = tblCur = {} 看,执行顺序就是:
var tblRoot = tblCur = {};
tblRoot = tblCur;
tblCur['key'] = undefined; // now tblRoot = {key: undefined}
tblCur['key'] = {};
tblCur = tblCur['key'];
通过上面的代码就构建了好了所需的查询数据,下面看看查询接口的写法。
对于目标字符串的每一字,我们都从这个keywords顶部开始匹配。首先是 keywords[a] ,若存在,则看 keyword[a][b],若最后 keyword[a][b]…[x]=true 则说明匹配成功,若 keyword[a][b]…[x]=undefined,则从下一个位置重新开始匹配 keywords[a] 。
function search(content) {
var tblCur,
p_star = 0,
n = content.length,
p_end,
match, //是否找到匹配
match_key,
match_str,
arrMatch = [], //存储结果
arrLength = 0; //arrMatch的长度索引
while(p_star < n) {
tblCur = tblRoot; //回溯至根部
p_end = p_star;
match_str = "";
match = false;
do {
match_key = content.charAt(p_end);
if(!(tblCur = tblCur[match_key])) { //本次匹配结束
p_star += 1;
break;
} else {
match_str += match_key;
}
p_end += 1;
if(tblCur.end) //是否匹配到尾部
{
match = true;
}
} while (true);
if(match) { //最大匹配
arrMatch[arrLength] = {
key: match_str,
begin: p_star - 1,
end: p_end
};
arrLength += 1;
p_star = p_end;
}
}
return arrMatch;
}
以上就是整个关键词匹配系统的核心。这里很好的用到了js的语言特性,效率非常高。我用一篇50万字的《搜神记》来做测试,从中查找给定的300个成语,匹配的效果是1秒左右。重要的是,由于目标文本是一次遍历的,所以目标文本的长短对查询时间的影响几乎不计。对查询时间影响较大的是关键词的数量,目标文本的每个字都遍历一遍关键词,所以对查询有一定影响。
简单分析
看到上文估计你也纳闷,对每个字都遍历一遍所有关键词,就算有些关键词有部分相同,但是完全遍历也是挺耗时的呀。但js中对象的属性是使用哈希表来进行构建的,这种结构的数据跟单纯的数组遍历是有很大不同的,效率要比基于顺序的数组遍历高得多。可能有些同学对数据结构不太熟悉,这里我简单说一下哈希表的相关内容。
首先看看数据的存储。
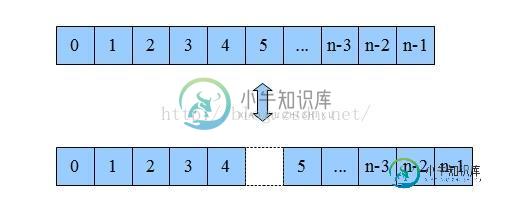
数据在内存的存储由两部分组成,一部分是值,另一部分是地址。把内存想象成一本新华字典,那字的解释就是值,而目录就是地址。字典里面是按拼音排序的,比如相同发音的“ni”就排在同一块,也就是说数组整齐排列在一块内存区域里面,这样的结构就是数组,你可以指定“ni” 1号,10号来访问。结构图如下:

数组的优势是遍历简单,通过下标就能直接访问相应的数据了。但是它要增删某一项就非常困难。比如你要把第6项删掉,那第5项之后的数据都要向前移一个位置。如果你要删除第一位,整个数组都要移动,消耗非常大。
为了解决数组增删的问题,链表就出现了。如果我们将值分成两部分,一部分用来储存原来的值,另一部分用来储存一个地址,这个地址指向另外一个同样的结构,以此类推就构成了一个链表。结构如下:

从上图可以明显看出,对链表进行增删非常简单,只要把目标项和前一项的next改写就完成了。但是要查询某个项的值就非常困难了,你必须依次遍历才可以访问到目标位置。

为了整合这两种结构的优势,聪明如你一定想到了下面这种结构。
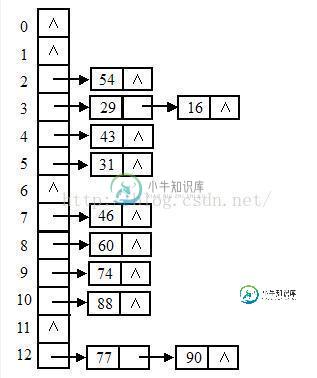
这种数据结构就是哈希表结构。数组里面存储链表的头地址,就可以形成一个二维数据表。至于数据如何分布,这个就是哈希算法,正规的翻译应该是散列算法。算法虽然有很多种,原理上都是通过一个函数对key进行求解,再根据求解得到的结果安放数据。也就是说key和实际地址之间形成了一个映射,所以这个时候我们不再以数组下标或者单纯的遍历来访问数组,而是以散列函数的反函数来定位数据。js中的对象就是一个哈希结构,比如我们定义一个obj,obj.name通过散列,他在内存中的位置可能是上图中的90,那我们想要操作obj.name的时候,底层就会自动帮我们通过哈希算法定位到90的位置,也就是说直接从数组的12项开始查找链表,而不是从0开始遍历整个内存块。
js中定义一个对象obj{key: value},key是被转换成字符串然后经过哈希处理得到一个内存地址,然后将值放入其中。这就可以理解为什么我们可以随意增删属性,也能理解为什么在js中还能为数组赋属性,而且数组也没有所谓的越界了。
在数据量较大的场合,哈希表具有非常明显的优势,因为它通过哈希算法减少了很多不必要的计算。所谓性能优化,其实就是让计算机少运算;最大的优化,就是不计算!
算法的优化
现在理解算法底层实现,回过头来就可以考虑对算法进行优化了。不过在优化前还是要强调一句:不要盲目追求性能!比如本案例中,我们最多就是5000字的匹配,那现有算法足矣,所有优化都是不必要的。之所以还来说说优化,就是为了提高自己对算法对程序的理解,而不是真的要去做那1ms的优化。
我们发现我们的关键词都没有一个字的,那我们按照一个字的单位进行关键词遍历显然就是一个浪费了。这里的优化就是预先统计关键词的最大最小长度,每次以最小长度为单位进行查找。比如说我测试用例的关键词是成语,最短都是4个字,那么我每次匹配都是4个字一起匹配,如果命中就继续深入查找到最大长度。也就是说我们最开始构造树的时候首先是以最小长度构建的,然后再逐字增加。
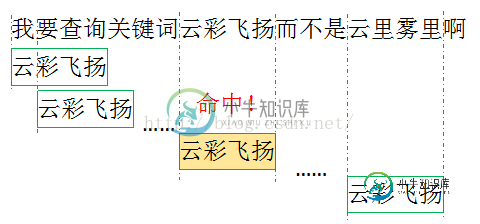
简单计算一下,按照我们的测试用例,300个成语,我们匹配一个词只需一次对比,而单字查询的话我们需要对比4次,而每次对比我们都要访问我们的树结构,这就是可避免的性能消耗。更重要的是,这里的对比并不是字符串对比,这里我们的关键字都是作为key存在的,效果就是 和key in obj一样的,都是对key进行哈希变换然后访问相应的地址!所以千万不要纠结对比一个字和对比4个字的差异,我们没对比字符串!
关于多关键词的匹配就说到这里了,优化版代码我就不贴了,因为一般也用不到。
-
本文向大家介绍js实现搜索框关键字智能匹配代码,包括了js实现搜索框关键字智能匹配代码的使用技巧和注意事项,需要的朋友参考一下 只要使用搜索引擎的朋友应该都有这样的体会,就是当在搜索框输入关键字的时候,会出现自能匹配现象,这绝对是非常好的用户体验,下面就是一段类似的代码,当然这里只是掩饰,所以只能匹配的数据都是本地固定好的,在实际应用中可以才能够数据库读取数据。 效果图: 代码实例如下: 更多关于
-
问题内容: 我目前正在尝试使我的java代码(使用eclipse)执行某些功能(如果说了某件事)。我正在使用Sphinx4库,这是我目前拥有的: 我想做的是在它说的那行: 如果我的发言是Hello Computer,Hello Jarvis,Good Morning Computer或Good Morning Jarvis,则运行该功能。或者换句话说,如果语音与.gram文件中的“ public
-
本文向大家介绍python通过BF算法实现关键词匹配的方法,包括了python通过BF算法实现关键词匹配的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了python通过BF算法实现关键词匹配的方法。分享给大家供大家参考。具体实现方法如下: 算法思想:目标串t与模式串p逐词比较,若对应位匹配,则进行下一位比较;若不相同,p右移1位,从p的第1位重新开始比较。 算法特点:整体移动方向
-
关键词分为两部分: 时间/关键词筛选 和 关键词详情 1.时间/关键词筛选 1)便捷按钮有今日、昨日、前日、上周 X、近七天 2)能自定义选择时间段以及搜索出含有个别字眼的关键词来得出想要的结果报表 2.关键词详情 1)关键词报表中所指的关键词,是指访问者是通过搜索引擎搜索相应的关键词进入网站 2)如有需要,亦可点击下载当前报表及更多数据下载,将报表下载到个人电脑,以供存档及分析 3)关于
-
下面的表格列出了 Dart 语言特殊对待的关键词。 abstract 2 dynamic 2 implements 2 show 1 as 2 else import 2 static 2 assert enum in super async 1 export 2 interface 2 switch await 3 extends is sync 1 break external 2 libra
-
本文向大家介绍JS实现关键字搜索时的相关下拉字段效果,包括了JS实现关键字搜索时的相关下拉字段效果的使用技巧和注意事项,需要的朋友参考一下