
MongoDB聚合分组取第一条记录的案例与实现方法

前言
今天开发同学向我们提了一个紧急的需求,从集合mt_resources_access_log中,根据字段refererDomain分组,取分组中最近一笔插入的数据,然后将这些符合条件的数据导入到集合mt_resources_access_log_new中。
接到这个需求,还是有些心虚的,原因有二,一是,业务需要,时间紧;二是,实现这个功能MongoDB聚合感觉有些复杂,聚合要走好多步。
数据记录格式如下:
记录1
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C1",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1234",
"resourceType" : "static_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-22T19:45:46.015+08:00"),
"disabled" : 0
}
记录2
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C1",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1234",
"resourceType" : "Dome_resource",
"ip" : "17.17.13.14",
"createTime" : ISODate("2018-12-21T19:45:46.015+08:00"),
"disabled" : 0
}
记录3
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C2",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1235",
"resourceType" : "static_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-20T19:45:46.015+08:00"),
"disabled" : 0
}
记录4
{
"_id" : ObjectId("5c1e23eaa66bf62c0c390afb"),
"_class" : "C2",
"resourceUrl" : "/static/js/p.js",
"refererDomain" : "1235",
"resourceType" : "Dome_resource",
"ip" : "17.17.13.13",
"createTime" : ISODate("2018-12-20T19:45:46.015+08:00"),
"disabled" : 0
}
以上是我们的4条记录,类似的记录文档有1500W。
因为情况特殊,业务发版需要这些数据。催的比较急,而 通过 聚合 框架aggregate,短时间有没有思路, 所以,当时就想着尝试采用其他方案。
最后,问题处理方案如下。
Step 1 通过聚合框架 根据条件要求先分组,并将新生成的数据输出到集合mt_resources_access_log20190122 中(共产生95笔数据);
实现代码如下:
db.log_resources_access_collect.aggregate(
[
{ $group: { _id: "$refererDomain" } },
{ $out : "mt_resources_access_log20190122" }
]
)
Step 2 通过2次 forEach操作,循环处理 mt_resources_access_log20190122和mt_resources_access_log的数据。
代码解释,处理的逻辑为,循环逐笔取出mt_resources_access_log20190122的数据(共95笔),每笔逐行加工处理,处理的逻辑主要是 根据自己的_id字段数据(此字段来自mt_resources_access_log聚合前的refererDomain字段), 去和 mt_resources_access_log的字段 refererDomain比对,查询出符合此条件的数据,并且是按_id 倒序,仅取一笔,最后将Join刷选后的数据Insert到集合mt_resources_access_log_new。
新集合也是95笔数据。
大家不用担心性能,查询语句在1S内实现了结果查询。
db.mt_resources_access_log20190122.find({}).forEach(
function(x) {
db.mt_resources_access_log.find({ "refererDomain": x._id }).sort({ _id: -1 }).limit(1).forEach(
function(y) {
db.mt_resources_access_log_new.insert(y)
}
)
}
)
Step 3 查询验证新产生的集合mt_resources_access_log_new,结果符合业务要求。
刷选前集合mt_resources_access_log的数据量为1500多W。
刷选后产生新的集合mt_resources_access_log_new 数据量为95笔。
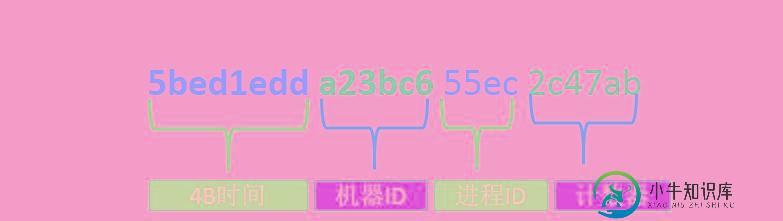
注意:根据时间排序的要求,因为部分文档没有createTime字段类型,且 createTime字段上没有创建索引,所以未了符合按时间排序我们采用了sort({_id:1})的变通方法,因为_id 还有时间的意义。下面的内容为MongoDB对应_id 的相关知识。
最重要的是前4个字节包含着标准的Unix时间戳。后面3个字节是机器ID,紧接着是2个字节的进程ID。最后3个字节存储的是进程本地计数器。计数器可以保证同一个进程和同一时刻内不会重复。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对小牛知识库的支持。
-
问题内容: 我正在尝试获取“分组”记录的第一条记录和最后一条记录。 更准确地说,我正在执行这样的查询 但我想获得小组的第一和最后的记录。可以通过执行大量请求来完成,但是我的桌子很大。 是否有使用MySQL的方法(如果可能的话,可以减少处理时间)? 问题答案: 您要使用和: 这避免了昂贵的子查询,并且我发现对于这个特定问题它通常更有效。 请查阅手册中的两个函数以了解它们的参数,或访问本文,其中包含有
-
在mongodb聚合调用中,如何使用$group操作符将管道中的所有文档分组为一个结果? 假设我有一组记录,看起来像这样: 我想使用聚合函数在数据库中查询在给定日期范围内注册的用户列表,并将其作为列表返回。我想要一个如下的结果: 我的查询如下所示: 到目前为止,一切顺利。我现在有一部分记录,所有记录的注册日期都在所需的范围内。但这就是我遇到麻烦的地方。现在,我想将所有这些记录分组到一个包含所有ID
-
问题内容: 我有一个包含以下各列的模型: 我有索引和。 现在,我想获取由排序的每个对象的第一个日志。 一种方法是对每个用户名运行以下查询: 但这显然会查询数据库很多次(等于用户名的数量)。有什么方法可以只执行一个数据库查询吗? 问题答案: 另一种情况: 返回每个“第一”条目 的整行。 这种Ruby语法应该可以工作:
-
我使用spring数据mongodb,在想要聚合查询中实现我使用MongoTemplate和聚合方法。当我跟踪日志时,它显示查询如下: 我想知道这个查询的执行计划。我如何才能发现我的索引是否在查询过程中被使用?
-
本节,我们将了解一下如何在GPU上实现直方图构建。首先实现实现了一个常规内核,该内核代码基于串行和OpenMP版本的算法。然后,再来对GPU实现进行优化,这里使用的优化策略为:合并访问和局部内存。 9.3.1 常规GPU实现:GPU1 根据清单9.2中的OpenMP实现,我们可以实现一个最简单OpenCL版本,也就是将循环迭代拆开,让每个工作项完成一个标识符的归属计算。 不过,OpenMP实现中,
-
本文向大家介绍MongoDB聚合分组多个结果,包括了MongoDB聚合分组多个结果的使用技巧和注意事项,需要的朋友参考一下 要聚合多个结果,请在MongoDB中使用$group。让我们创建一个包含文档的集合- 在find()方法的帮助下显示集合中的所有文档- 这将产生以下输出- 以下是汇总组多个结果的查询- 这将产生以下输出-