
python jieba分词并统计词频后输出结果到Excel和txt文档方法

前两天,班上同学写论文,需要将很多篇论文题目按照中文的习惯分词并统计每个词出现的频率。
让我帮她实现这个功能,我在网上查了之后发现jieba这个库还挺不错的。
运行环境:
- 安装python2.7.13:https://www.python.org/downloads/release/python-2713/
- 安装jieba:pip install jieba
- 安装xlwt:pip install xlwt
具体代码如下:
#!/usr/bin/python # -*- coding:utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import jieba import jieba.analyse import xlwt #写入Excel表的库 if __name__=="__main__": wbk = xlwt.Workbook(encoding = 'ascii') sheet = wbk.add_sheet("wordCount")#Excel单元格名字 word_lst = [] key_list=[] for line in open('1.txt'):#1.txt是需要分词统计的文档 item = line.strip('\n\r').split('\t') #制表格切分 # print item tags = jieba.analyse.extract_tags(item[0]) #jieba分词 for t in tags: word_lst.append(t) word_dict= {} with open("wordCount.txt",'w') as wf2: #打开文件 for item in word_lst: if item not in word_dict: #统计数量 word_dict[item] = 1 else: word_dict[item] += 1 orderList=list(word_dict.values()) orderList.sort(reverse=True) # print orderList for i in range(len(orderList)): for key in word_dict: if word_dict[key]==orderList[i]: wf2.write(key+' '+str(word_dict[key])+'\n') #写入txt文档 key_list.append(key) word_dict[key]=0 for i in range(len(key_list)): sheet.write(i, 1, label = orderList[i]) sheet.write(i, 0, label = key_list[i]) wbk.save('wordCount.xls') #保存为 wordCount.xls文件
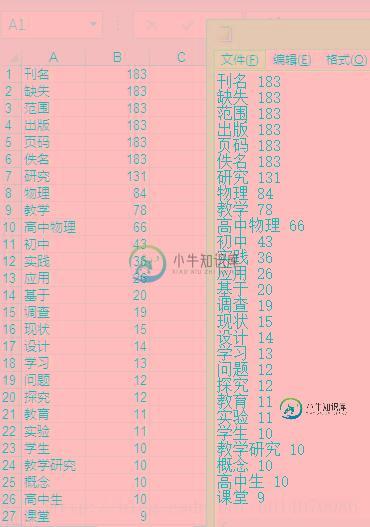
1.txt是你需要分词统计的文本内容,最后会生成wordCount.txt和wordCount.xls两个文件。下图是最后结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文向大家介绍Python英文文章词频统计(14份剑桥真题词频统计),包括了Python英文文章词频统计(14份剑桥真题词频统计)的使用技巧和注意事项,需要的朋友参考一下 Python剑桥真题词频统计 最好还是要学以致用,自主搜集了19年最近的14份剑桥真题之后,通过Python提供的jieba第三方库,对所有的文章信息进行了词频统计,并选择性地剔除了部分简易词汇,比如数字,普通冠词等,博主较懒,
-
问题内容: 我想在elasticsearch中更改评分系统,以摆脱对一个术语的多次出现计数的麻烦。例如,我想要: “德克萨斯州德克萨斯州” 和 “得克萨斯州” 得分相同。我发现elasticsearch表示该映射将禁用词频统计,但是我的搜索结果却不一样: } 任何帮助将不胜感激,我无法找到很多有关此的信息。 编辑: 我正在添加搜索代码,并在使用解释时返回了什么。 我的搜索代码: 当我搜索解释时,我
-
所以我们在一组15k推文上运行多项式朴素贝叶斯分类算法。我们首先根据Weka的StringToWordVector函数将每条推文分解成一个单词特征向量。然后,我们将结果保存到一个新的arff文件中,作为我们的训练集提供给用户。我们用另一组5k推文重复这个过程,并使用从我们的训练集中导出的相同模型重新评估测试集。 我们想做的是输出weka在测试集中分类的每个句子及其分类...我们可以看到算法的性能和
-
本文向大家介绍tr命令在统计英文单词出现频率中的妙用,包括了tr命令在统计英文单词出现频率中的妙用的使用技巧和注意事项,需要的朋友参考一下 tr命令我们很清楚,可以删除替换,删除字符串。 在英文中我们要经常会经常统计英文中出现的频率,如果用常规的方法,用设定计算器一个个算比较费事,这个时候使用tr命令,将空格分割替换为换行符,再用tr命令删除掉有的单词后面的点号,逗号,感叹号。先看看要替换的thi
-
问题内容: 我想从文本文件中提取每个词,然后计算字典中的词频。 例: 我没有那么远,但是我看不出如何完成它。到目前为止,我的代码: 问题答案: 如果您不想使用collections.Counter,则可以编写自己的函数: 对于更好的东西,请看正则表达式。
-
主要内容:执行Spark字数计算示例的步骤在Spark字数统计示例中,将找出指定文件中存在的每个单词的出现频率。在这里,我们使用Scala语言来执行Spark操作。 执行Spark字数计算示例的步骤 在此示例中,查找并显示每个单词的出现次数。在本地计算机中创建一个文本文件并在其中写入一些文本。 检查文件中写入的文本。 在HDFS中创建一个目录,保存文本文件。 将HDD上的sparkdata.txt 文件上传到特定目录中。 现在,按照以下命