《中邮消费金融》专题
-
 Java如何通过线程解决生产者/消费者问题
Java如何通过线程解决生产者/消费者问题本文向大家介绍Java如何通过线程解决生产者/消费者问题,包括了Java如何通过线程解决生产者/消费者问题的使用技巧和注意事项,需要的朋友参考一下 生产者和消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一个存储空间,如下图所示 生产者向空间里存放数据,而消费者取用数据,如果不加以协调可能会出现以下情况: 存储空间已满,而生产者占用着它,消费者等着生产者让出空间从而去除产品,生
-
JMS连接,会话和生产者/消费者之间的关系
问题内容: 我想向同一队列发送一批20k JMS消息。我使用10个线程将任务拆分,因此每个线程将处理2k条消息。我不需要交易。 我想知道是否建议建立一个连接,一个会话和10个生产者? 如果所有线程共享一个生产者,该怎么办?我的消息会损坏还是会同步发送(不会提高性能)? 如果我总是连接到同一队列,那么决定是创建新连接还是会话的一般指导方针是什么? 谢谢你,很抱歉一次问了很多。 问题答案: 如果某些消
-
 Java实现简易生产者消费者模型过程解析
Java实现简易生产者消费者模型过程解析本文向大家介绍Java实现简易生产者消费者模型过程解析,包括了Java实现简易生产者消费者模型过程解析的使用技巧和注意事项,需要的朋友参考一下 一、概述 一共两个线程,一个线程生产产品,一个线程消费产品,使用同步代码块方法,同步两个线程。当产品没有时,通知生产者生产,生产者生产后,通知消费者消费,并等待消费者消费完。 需要注意的是,有可能出现,停止生产产品后,消费者还没未来得及消费生产者生产的最后
-
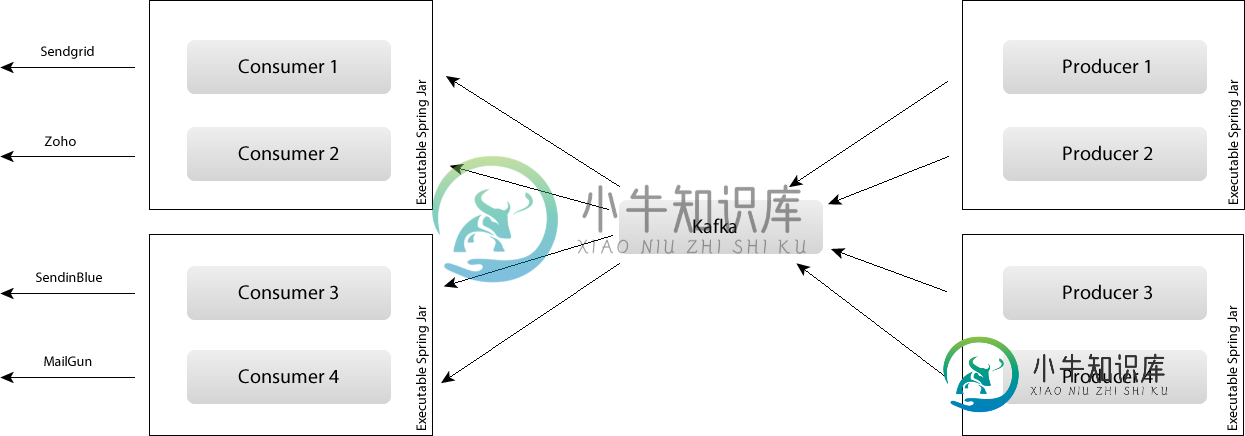 设计Kafka消费者和生产者以实现可扩展性
设计Kafka消费者和生产者以实现可扩展性我想设计一个解决方案,用于向多个提供商发送不同类型的电子邮件。总体概述。 我有几个上游提供商Sendgrid、Zoho、Mailgun等。它们将用于发送电子邮件等。例如: 注册新用户的电子邮件 删除用户的电子邮件 空间配额限制的电子邮件 (一般大约有6种类型的电子邮件) 每种类型的电子邮件都应该生成到生产者中,转换为序列化Java对象,并发送到与上游提供商集成的适当的Kafka消费者。 问题是如何
-
如何“忽略”从Apache Camel文件消费者获取的交换
我有一个批处理文件使用者,它正在轮询一个公共目录,许多不同的进程将文件拖放到该目录。这些文件通过文件名上的guid“成批”在一起。一旦某个特定批次完成,应用程序就会删除。完成文件以触发camel文件使用者。 我的问题是,我正在试图找到一种可能“忽略”邮件/交换的方法,这些邮件/交换可能包含我不想处理的文件(即…不属于我当前批处理的一部分)。 此外,我希望“被忽略”的交换不被camel处理(即...
-
单个消费者能否读取Kafka主题的多个分区?
有一个16个分区的Kafka主题 使用给定的消费者组名称,我们目前正在启动单个消费者来阅读该主题。 > 单个消费者是否从该主题的(仅)读取?如果带有消息为空,消费者是否从下一个分区开始读取(...等等)? 我们可以选择启动多个消费者(使用相同的消费者组名称)来读取相同的主题(有16个分区)。为了并行读取多个分区,可以维护多少消费者?
-
AWS运动-如何从最后一个检查点恢复消费
我正在使用KCL(v2)将Kafka消费者转换为AWS动觉消费者。在Kafka中,偏移量用于帮助消费者跟踪其最近使用的消息。如果我的Kafka应用程序死机,它将使用重新启动时停止的偏移量。 然而,这在Kinesis中是不一样的。我可以设置,但唯一的参数是、或。如果我的Kinesis应用程序死机,它将不知道重新启动时从哪里恢复消费。 我的KCL消费者非常简单。方法如下所示: 而RecordProce
-
Spring Security SAML2多个IDP但唯一的断言消费者服务
我们正在使用Spring Security SAML2与许多身份提供者一起开发SAML身份验证。我们的服务提供者的元数据文件是唯一的,它将分发给所有身份提供者,因此我们需要为断言消费者服务提供唯一的endpoint。 yaml配置如下所示: 我们尝试添加每个IDP 但是找不到url结果。 我们如何配置它? 谢啦
-
Kafka消费者在重新平衡时获得不同的补偿
我有一个微服务应用程序,它是使用camel kafka开发的,用于消费来自kafka的消息。我用4个并发实例运行这个服务,其中每个实例都有1个消费者,他们消费的主题有20个分区。 在维护期间(每天凌晨1-2点),应用程序将通过停止消费者来暂停消费。 当应用程序暂停消费时,kafka重新平衡发生,一些实例将在停止消费之前分配更多分区。 e、 由instanceA(partition1-5)使用的g分
-
使用Resilience4j库具有断路器功能的spring kafka消费者
我正在尝试实现Spring kafka消费者,它需要在处理事件时出现某个异常后暂停(例如:在将事件信息存储到DB时,DB已关闭)。 我们如何在spring boot-2.3.8(spring kafka)中使用Resilience4j断路器方法来处理这种情况 寻找一些消费者暂停和恢复的例子。 在Kafka,listerner只是想捕捉解析错误。如果出现5个以上的解析错误,则需要停止侦听器。但我不确
-
Flink 1.11当Flink 1.12成功时,消费者无法传播水印
我看到了一些奇怪的行为。我使用Flink 1.12编写了一些Flink处理器,并试图让它们在Amazon EMR上运行。然而,Amazon EMR目前只支持Flink 1.11.2。当我降级时,我莫名其妙地发现水印不再传播。 主题上只有一个分区,并行度设置为1。这里有我遗漏的东西吗?我觉得我有点疯了。 这是Flink 1.12的输出: 这是Flink 1.11的输出: 下面是公开它的集成测试:
-
Kafka-生产到一个主题,然后从该主题消费后?
我以前是学习Kafka的传统ActiveMQ用户。我有一个问题。 使用Active MQ,您可以执行以下操作: 将100条消息提交到队列中 我试着在Kafka做同样的事情 如果不启动Consumer,等待它启动,然后运行producer,则此示例不起作用。 谁能告诉我如何修改我的示例程序,以在消息等待被消费的地方执行操作?
-
我可以使用Spring Cloud Stream绑定多个消费者组吗?
我正在编写一个将处理事件消息的应用程序(发布到主题)。我有多个endpoint应该使用这些消息(和),出于实用的原因,我想将这些endpoint一起部署在一个聚合包中。 有了Spring Cloud Stream,我可以使用Spring。云流动绑定。文件上载已完成。group=元数据读取器,为第一个endpoint设置消费者组;我还想在配额检查组下处理消息,但基于属性的配置只允许每个消息队列绑定一
-
 Azure功能对消费计划冷启动可长达30分钟
Azure功能对消费计划冷启动可长达30分钟我有一个azure函数v3,用C#写的,用类库的方法。 < li >该功能由blob存储触发。 < li >该功能正在使用消费计划。 问题是冷启动可能长达30分钟!我已经查阅了这个链接的文档 但是没有关于预期冷起动正时的具体数字。 一个有趣的观察是,如果我导航到门户,并点击刷新按钮: 那么该功能会立即被触发。 这是正常的预期行为吗 您能给我指一下任何明确说明消费计划中冷启动时间为0-30-50分钟
-
Spring的Kafka--从一个话题看多个消费者的阅读
我正在使用spring boot构建一个web应用程序,现在我需要接收实时通知。我正计划使用apache kafka作为这方面的消息代理。要求用户具有不同的角色,并且根据角色,他们应该接收其他用户正在执行的操作的通知。 我设置了一个生产者和消费者,作为消费者,我可以接收发布到一个主题的信息,比如说topic1。 我遇到的问题是,我可以让多个用户收听同一个主题,而每个用户都应该得到发布到该主题的消息