《中邮消费金融》专题
-
RabbitMQ骆驼消费者错误-java。网SocketException:连接重置
Camel RabbitMQ的新手。用Apache Camel写了一个简单的RabbitMQ消费者。 当前在从队列中弹出一个值后进行一个简单的rest调用。它可以处理大约100条消息,并开始抛出此错误 我不确定我做错了什么,任何帮助都是感激的。
-
为什么同一组id的Kafka消费者不平衡?
我正在编写一个概念验证应用程序来使用Apache Kafka0.9.0.0中的消息,看看是否可以使用它而不是通用的JMS消息代理,因为Kafka提供了好处。这是我的基本代码,使用新的消费者API: 我使用默认设置启动了一个kafka服务器,并使用shell工具启动了一个kafka生产者,以便将消息写入我的主题。然后,我使用这段代码与两个使用者连接,发送正确的服务器来连接,发送主题来订阅,其他一切都
-
用于多个jms服务器的单个jms消费者
我使用分布式jms队列,weblogic是我的应用服务器。在我的集群环境中部署了三个jms服务器。例如,生产者只是使用队列名称jndi lookup 'udq '来发送消息。现在,我已经为每个jms服务器关联了一个消费者,并且能够消费消息,到目前为止没有问题。 这里有一个问题,我是否可以让一个消费者使用来自3个jms服务器的消息。weblogic允许使用以下语法对目标查找进行jndi命名:@ 我只
-
生产商/消费者具有批量和冲洗功能
我正在尝试编写具有两种方法的批处理邮件服务: :可以发送邮件,由生产者调用 :刷新服务。消费者应该取一个List,然后调用另一个(昂贵的)方法。通常只有在达到批量大小后才应该调用昂贵的方法。 这有点类似于这个问题:生产者/消费者-生产者将数据添加到集合而不阻塞,消费者批量消费集合中的数据 使用具有超时的< code>poll()可以做到这一点。但是,如果生产者不想等待超时,它应该能够刷新邮件服务,
-
Gradle:多个项目变体:myLib匹配消费者属性
我编写的库使用中的,应用程序本身也使用。 使用Gradle4.7。在第4.4.1节中也面对这一点。 怎么修? 项目格拉德尔 app.gradle 迈里布。格拉德尔 从
-
Kafka Streams 1.1.0:消费者组重新处理整个日志
我们有一个kafka streams应用程序(2.0),它正在与kafka代理(1.1.0)通信。streams应用程序一直在毫无原因地重新处理整个日志-应用程序没有重新启动,没有重新平衡,只是闲坐着-在某些情况下,它正在处理消息,在另一些情况下,它正在等待接收消息(处理消息的时间不到6个小时)。我们已经做了大量的研究,通过将
-
Azure B2C邀请消费者用户&检索用户权限
有人能提供一个通用的方法来满足这些要求吗?我花了一些时间研究这些不同的主题并尝试实现解决方案,我对涉及的工作量感到惊讶。希望我错过了什么。 我如何邀请消费者用户到一个B2C租户,以便他们可以使用他们的社交帐户(例如:个人微软或谷歌帐户)认证进入我们的应用程序?我在Azure Portal上找到的唯一一个baked in解决方案使用B2C本地帐户。请注意,我不想使用可公开访问的注册流。 目前,我正在
-
Spring Amqp消费者在运行一段时间后暂停
我们有一个具有Ha all策略的2节点RabbitMQ集群。我们在应用程序中使用Spring AMQP与RabbitMQ对话。生产者部分工作正常,但消费者工作了一段时间并暂停。生产者和消费者作为不同的应用程序运行。更多关于消费者部分的信息。 我们将与一起使用,使用手动模式和默认 在我们的应用程序中,我们创建队列(按需)并将其添加到侦听器中 当我们从10个和20个开始时,消费大约持续15个小时并暂停
-
我话题上的耐用标志消费者不管用?
尝试在主题使用者上实现持久功能。为 jms 使用者和客户端 ID 放置了一个名称。(显然添加了持久=“真”) 据我所知。当它第一次运行时,该主题会将消费者注册为“耐用”。 所以基本上我这样做了,部署了生产者和消费者。它被注册为耐用消费者。将消息发布到主题,消费者将获得消息。现在,我取消部署消费者,并发布另一条消息,消费者无论何时起床都应该收到。当我再次部署消费者时,我得到了通用的temp-topi
-
面向外行的Java8供应商和消费者解释
作为一个学习Java的非Java程序员,我正在阅读关于和接口的文章。我无法理解它们的用法和含义。什么时候和为什么要使用这些接口?有人能给我一个简单的外行的例子吗…我发现医生的例子不够简洁,不足以让我理解。
-
保存ChronicleQueue的消费者/裁剪者读取偏移量
我正在探索ChronicleQueue来保存我的一个应用程序中生成的事件。我想在经过一些处理后,将保存的事件按其原始发生顺序发布到不同的系统。我有多个应用程序实例,每个实例都可以运行一个单线程appender来将事件添加到ChronicleQueue。尽管跨实例排序是必要的,但我想理解以下两个问题。 2)还需要一些建议,如果有一种方法来保持跨实例的事件顺序。
-
如何在骆驼路线上模拟Kafka消费者endpoint?
我有一个驼峰endpoint,基本上是Kafka消费者从一个主题中读取信息并将其发送到数据库。它工作得很好,但是,我很难对它进行单元测试,因为我无法模拟Kafkaendpoint。有谁能帮我在骆驼路线上嘲笑Kafka的消费者吗?
-
Flink-Query Kafka主题用于消费者群体的偏移?
我有一个用例,其中数据将从kafkaTopic1流入程序(我们称之为P1),经过处理,然后持久化到数据库。P1将在一个多节点集群上,因此每个节点将处理大量的kafka分区(假设本主题有5个节点和50个kafka分区)。如果其中一个节点由于任何原因完全失败,并且有数据正在处理,那么该数据将丢失。 例如,如果kafkaTopic1上有500条消息,node2拉出了10条消息(因此根据偏移量要拉出的下一
-
 关闭消费客户端后ActiveMQ Artemis队列被删除
关闭消费客户端后ActiveMQ Artemis队列被删除之后,我尝试从其他应用程序使用者那里使用该消息。这没有问题。 我的应用程序使用者是用Spring Boot构建的,如下所示: 顺便说一句,最初的队列是在应用程序生成器将消息发送到ActiveMQ Artemis时创建的,并使用完成,如下所示:
-
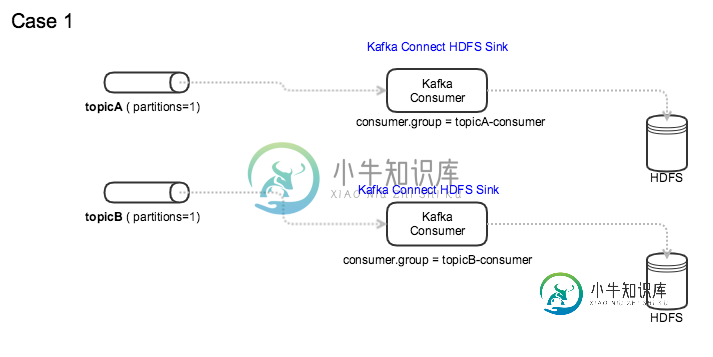 Kafka:使用公共消费者组访问多个主题
Kafka:使用公共消费者组访问多个主题我们的集群运行Kafka0.11并且对使用消费者组有严格的限制,我们不能使用任意的消费者组,所以Admin必须创建所需的消费者组。 我们运行Kafka连接HDFS接收器,从主题读取数据并写入HDFS。所有主题只有一个分区。 在Kafka HDFS接收器中使用消费者组时,我可以考虑遵循两种模式。 我知道,当一个主题有多个分区时,如果一个使用者失败,同一使用者组中的另一个使用者将接管该分区。 我的问题