《阿里面试》专题
-
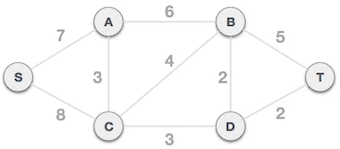 普里姆算法
普里姆算法主要内容:普里姆算法的具体实现了解了什么是 最小生成树后,本节为您讲解如何用普里姆(prim)算法查找连通网(带权的连通图)中的最小生成树。 普里姆算法查找最小生成树的过程,采用了贪心算法的思想。对于包含 N 个顶点的连通网,普里姆算法每次从连通网中找出一个权值最小的边,这样的操作重复 N-1 次,由 N-1 条权值最小的边组成的生成树就是最小生成树。 那么,如何找出 N-1 条权值最小的边呢?普里姆算法的实现思路是: 将连通
-
org.apache.batik.dom.svg.SVGDOMImplementation哪里去了?
问题内容: 在batik的文档中,它显示了如何从类org.apache.batik.dom.svg.SVGDOMImplementation中获取DOM实现的实例。 但是,从同一站点下载Batik 1.8之后,我在任何地方都找不到此类。 我下载了1.7版本,并在batik-svg-dom.jar中找到了它,但它在1.8内的同一jar中不存在(或据我所知在该软件包中的任何jar中都不存在)。 此类已
-
BeautifulSoup4藏在哪里?
问题内容: 我做到了,得到了非常乐观的回应: 但是当我尝试使用或在脚本中使用python时,它说该名称没有模块。 更新:告诉我,但是我正在运行2.7.2+(并看到2.7个路径)…所以现在我需要弄清楚为什么将事物放置在错误的位置。 问题答案: 尝试。不幸的是,PyPI软件包名称和导入名称之间没有对应关系。之后,类名与之前相同。将工作。 如果仍然无法解决问题,请重试并记下软件包安装路径。然后在您的py
-
Ruby on Rails 。哪里
本文向大家介绍Ruby on Rails 。哪里,包括了Ruby on Rails 。哪里的使用技巧和注意事项,需要的朋友参考一下 示例 该where方法可用于任何ActiveRecord模型,并允许在数据库中查询与给定条件匹配的一组记录。 该where方法接受哈希值,其中键对应于模型代表的表上的列名。 作为一个简单的示例,我们将使用以下模型: 查找所有姓氏为Sven: 为了找到的第一个名字所有人
-
kube-apiserver在哪里
问题内容: 基本问题:当我尝试在主节点上使用kube-apiserver时,出现命令未找到错误。如何安装/配置kube- apiserver?任何指向示例的链接都将有所帮助。 详细信息:我是Kubernetes和Docker的新手,并试图使用volumeClaimTemplates创建StatefulSet。我的问题是未创建自动PV,我在PVC日志中收到此消息:“ persistentvolume
-
jvisualvm去哪里了?
问题内容: 我正在运行Mac OSX Snow Leopard。 我一直使用Mac OSX的常规软件更新功能来更新Java。 我过去使用Java 工具取得了巨大的成功。 今天早上,我像往常一样键入命令行。我收到以下错误: 所有的其他Java工具(,,等)的工作就好了。 确实不包含(突然)。 产量: WTF? 问题答案: 似乎是链接的混合;/ usr / bin / jvisualvm符号链接指向不
-
从“哪里”删除
问题内容: 我正在寻找一种删除表1中记录的表,其中记录与表2中的“ stn”和“ jaar”匹配。表2中“ jaar”列的内容在上一阶段/查询中的格式为 年(基准)AS’jaar’ 抱歉,找不到我找到该“解决方案”的网站。 问题答案: 您可以使用以下方法实现此目的:
-
百里香TH:值
使用SpringMVC+Thymeleaf,如何将基于整数的模型属性绑定到使用th:value或th:field的表单中的输入字段,而字段本身不显示值“0”。
-
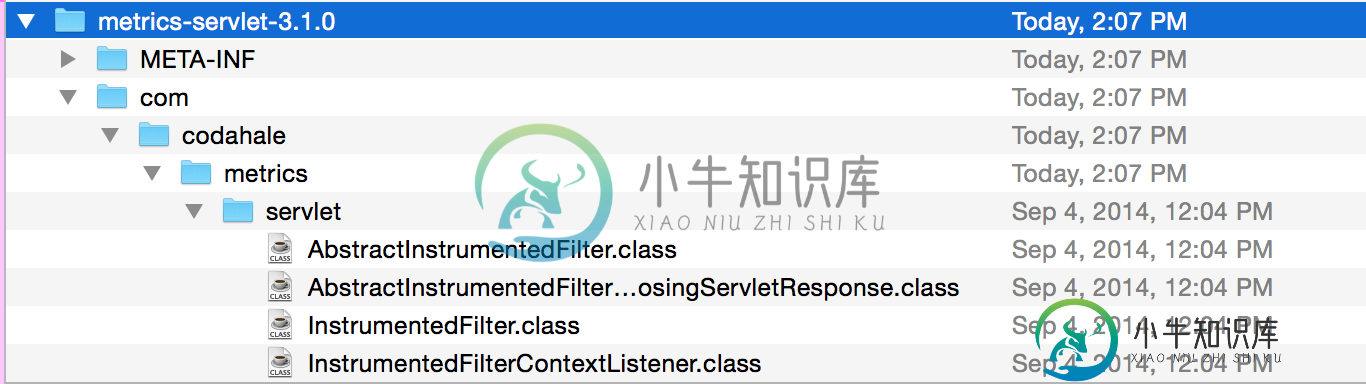 Dropwizard HealthcheckServlet在哪里?
Dropwizard HealthcheckServlet在哪里?我的build.gradle中包含以下内容: 在检查metrics-servlet时,我看到: 根据https://dropwizard.github.io/metrics/3.1.0/manual/servlets/, “metrics-servlet模块提供了一些有用的servlet”,包括HealthCheckServlet、MetricsServlet和ThreadDumpServlet。
-
蹲在骆驼里
我正在骆驼中开发一种机制,它将从一个可以是真或假的标志中为消息选择一个endpoint。这是一种节流机制,在我的上游通道被洪水淹没的情况下,它将把消息重新路由到批量摄取endpoint(发送到HDFS)。 最终,我的路线是这样的: 我的ThrottleHelper类的buildEndpoint方法如下所示: 目前,我在类上有一个名为checkStatus()的方法;设置shouldThrottle
-
春靴百里香
我使用Spring的引导2.6.3和我试图使用thymeleaf最近得到一个与html的确认消息后,我通过邮件确认我的帐户(我只是使用确认邮件来验证新帐户),所以我看了一些关于thymeleaf的视频,我标记所有的视频都有一个名为模板的文件夹和静态在src/main/ressource和我没有他们,所以我创建了一个名为模板的文件夹,在文件夹中我创建了一个html文件只是为了尝试它,如果它(html
-
1.5.3.2.11.8 里程定线
里程定线是根据指定线的范围来确定路由上对应的线对象。应用场景如当知道某一路段发生阻塞,能够确定该路段相对精确的位置范围。 下面以长春数据为例,一条路(路由 ID 为1690的路由)在距离路口 10-800km 之间的发生堵塞。 地图加载完成后进行里程定线分析服务,首先根据 RouteID 获得路由对象,路由对象查询成功之后才能进行后续的里程定线操作。里程定线的接口使用方法如下: // 通过SQL查
-
1.5.3.2.11.7 里程定点
里程定点是根据指定路由上的 M 值来定位点。应用情景与点定里程相反,如知道某事故距离某路口位置,需要确定其相对精确的坐标的时候使用。 下面以长春数据为例,确定一条发生交通事故的路上(路由ID为1690的路由)与路口距离为10km的事故点,里程定点的接口使用方法: 地图加载完成后进行里程定点分析服务,首先根据 RouteID 获得路由对象,路由对象查询成功之后才能进行后续的里程定点操作。 // 通过
-
1.5.3.2.11.6 点定里程
点定里程是计算路由上某点到起始点的 M 值,实际应用情景例如知道某事故发生的位置确定该点位于某路口距离。 下面以长春数据为例,计算一条路上(路由ID为1690的路由)发生交通事故的地点到该条路路口的距离。 点定里程接口使用方法如下: 地图加载完成后进行点定里程分析服务,首先根据 RouteID 获得路由对象,路由对象查询成功之后才能进行后续的点定里程操作。 // 通过SQL查询的方法建立路由,并添
-
从这里开始
你能够从spark官方网站查看一些spark运行例子。另外,Spark的example目录包含几个Spark例子,你能够通过如下方式运行Java或者scala例子: ./bin/run-example SparkPi 为了优化你的项目, configuration和tuning指南提高了最佳 实践的信息。保证你保存在内存中的数据是有效的格式是非常重要的事情。为了给部署操作提高帮助,集群模式概述介